También podría gustarte
- Control OptimoDocumento41 páginasControl OptimoAdelaido García Andrés100% (1)
- Teoria de Control OptimoDocumento10 páginasTeoria de Control OptimoYohanna Helen100% (1)
- Programación Dinámica (Introducción)Documento26 páginasProgramación Dinámica (Introducción)Elphego TorresAún no hay calificaciones
- Control óptimo determinista y estocásticoDocumento34 páginasControl óptimo determinista y estocásticoSantiago UlloaAún no hay calificaciones
- Lagrange RestringidaDocumento4 páginasLagrange RestringidaKenit GuevaraAún no hay calificaciones
- Ecuaciones en Diferencias SimultaneasDocumento7 páginasEcuaciones en Diferencias SimultaneasDaniela RecamanAún no hay calificaciones
- Control Óptimo y Optimización DinamicaDocumento28 páginasControl Óptimo y Optimización DinamicaJulie ClarkAún no hay calificaciones
- CALCULO 3-111052M UnivalleDocumento2 páginasCALCULO 3-111052M UnivallewdmcwdmcAún no hay calificaciones
- Calculo Diferencial EjerciciosDocumento7 páginasCalculo Diferencial EjerciciosCamilo Suarez100% (2)
- Ecuaciones DiferencialesDocumento6 páginasEcuaciones DiferencialesGerardo OrtigozaAún no hay calificaciones
- EjercicioTipicode Programacion Entera PuraDocumento5 páginasEjercicioTipicode Programacion Entera PuraCesar Camilo Baquero FlorezAún no hay calificaciones
- Err OresDocumento72 páginasErr Oresgap608688% (8)
- Proyecto Final Estadistica IIDocumento14 páginasProyecto Final Estadistica IIalejandraAún no hay calificaciones
- Muestreo SistemáticoDocumento6 páginasMuestreo SistemáticoChristine Lee100% (1)
- Ejercicios Por Tema U2 - GMM - AjlpDocumento15 páginasEjercicios Por Tema U2 - GMM - AjlpJoshue PerezAún no hay calificaciones
- Programacion DinamicaDocumento12 páginasProgramacion DinamicaAnthonyChilánAún no hay calificaciones
- Comunicaciones InalambricasDocumento9 páginasComunicaciones InalambricasJesus Sosa SalazarAún no hay calificaciones
- 01a - Programacion EnteraDocumento22 páginas01a - Programacion EnteraAndres LeyAún no hay calificaciones
- 04 Cartas de ControlDocumento24 páginas04 Cartas de ControlRey Manzera Cuadros100% (2)
- Definición Y Modelos de Programación EnteraDocumento8 páginasDefinición Y Modelos de Programación EnteraRosa MariaAún no hay calificaciones
- Método de La Gran MDocumento15 páginasMétodo de La Gran MByron HernándezAún no hay calificaciones
- Metodo de Los Minimos CuadradosDocumento10 páginasMetodo de Los Minimos CuadradosVannessa VicŤorio CasŤilloAún no hay calificaciones
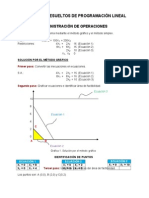
- Ejercicios resueltos de programación linealDocumento3 páginasEjercicios resueltos de programación linealCamino A IgualdadAún no hay calificaciones
- Exposicion 2 Control OptimoDocumento19 páginasExposicion 2 Control OptimoJhonatan Quintuña CordovaAún no hay calificaciones
- MétodosOSRDocumento8 páginasMétodosOSRjohezbAún no hay calificaciones
- Ejercicios Resueltos Tema 3 Micro OCW 2013 PDFDocumento24 páginasEjercicios Resueltos Tema 3 Micro OCW 2013 PDFDionisio UssacaAún no hay calificaciones
- OPTIMIZACIÓNDocumento9 páginasOPTIMIZACIÓNJOAKOAún no hay calificaciones
- Metodo SimplexDocumento21 páginasMetodo SimplexMariza Muro VargasAún no hay calificaciones
- Método de Punto FijoDocumento12 páginasMétodo de Punto FijoYoni Yo PichihuaAún no hay calificaciones
- Cap2 Ecuaciones en DiferenciasDocumento19 páginasCap2 Ecuaciones en DiferenciasMarte ValdezAún no hay calificaciones
- Manual de Investigación de OperacionesDocumento2 páginasManual de Investigación de OperacionesLuis MartínezAún no hay calificaciones
- Ant Colony Optimization ModelDocumento12 páginasAnt Colony Optimization ModelDaniel Reyes VelardeAún no hay calificaciones
- Manual de Fisica-Problemas Fisica Universidad MadridDocumento41 páginasManual de Fisica-Problemas Fisica Universidad MadridRaphael LopezAún no hay calificaciones
- OD 3° P (C.Optimo)Documento32 páginasOD 3° P (C.Optimo)Mtro José VRAún no hay calificaciones
- Unidad 3 Calculo VectorialDocumento39 páginasUnidad 3 Calculo VectorialJosé Suárez100% (1)
- Ergonomía 3 Diseño de Puestos de Trabajo - (PG 53 - 55) PDFDocumento3 páginasErgonomía 3 Diseño de Puestos de Trabajo - (PG 53 - 55) PDFJuan Andres Giraldo GiraldoAún no hay calificaciones
- Clase02 - Distribuciones de ProbabilidadDocumento64 páginasClase02 - Distribuciones de ProbabilidadMauricio Angel100% (1)
- Resolucion Matrices Teoria de La Decision LizasoDocumento7 páginasResolucion Matrices Teoria de La Decision LizasoPancho BenedettiAún no hay calificaciones
- Derivada Direccional y GradienteDocumento2 páginasDerivada Direccional y GradienteMaria Flores AymaraAún no hay calificaciones
- Probabilidad capítulo 6: Definición, enfoques y reglas básicasDocumento105 páginasProbabilidad capítulo 6: Definición, enfoques y reglas básicasJERSONAún no hay calificaciones
- El Teorema de Karush-Kuhn-TuckerDocumento32 páginasEl Teorema de Karush-Kuhn-TuckerCarbone LuisAún no hay calificaciones
- Operadores lineales autoadjuntos, normales, unitarios y ortogonalesDocumento3 páginasOperadores lineales autoadjuntos, normales, unitarios y ortogonalesArturo Chavez PalmaAún no hay calificaciones
- Control Optimo en Tiempo DiscretoDocumento16 páginasControl Optimo en Tiempo DiscretoArturo CMAún no hay calificaciones
- Ejercicios de Evaluacion - Unidad 2Documento9 páginasEjercicios de Evaluacion - Unidad 2Captian Benetts100% (1)
- Dise - Os 2k FraccionadosDocumento14 páginasDise - Os 2k Fraccionadosedugalian6685Aún no hay calificaciones
- 1.1.1 Regresion Lineal MultipleDocumento12 páginas1.1.1 Regresion Lineal MultipleKarlos RojasAún no hay calificaciones
- A Mark GoldmanDocumento3 páginasA Mark GoldmanMercedes UbAún no hay calificaciones
- Problem A Rio Mec FluidDocumento277 páginasProblem A Rio Mec FluidBeto Medina BlancoAún no hay calificaciones
- Dra - Maria Victoria Rodriguez Uría D. Miguel A. López Fernández Dña - Blanca M A Perez GladishDocumento41 páginasDra - Maria Victoria Rodriguez Uría D. Miguel A. López Fernández Dña - Blanca M A Perez GladishmariaAún no hay calificaciones
- Proyecto de Programación DinámicaDocumento16 páginasProyecto de Programación DinámicaricardoAún no hay calificaciones
- La Ecuación de Bellman v.2Documento9 páginasLa Ecuación de Bellman v.2Federico Castello RojoAún no hay calificaciones
- Alonso (1996) Control Optimo Con Restricciones. Aplicaciones Economicas. d104 - 96 PDFDocumento46 páginasAlonso (1996) Control Optimo Con Restricciones. Aplicaciones Economicas. d104 - 96 PDFrhroca2762Aún no hay calificaciones
- Planteamiento del problema de control óptimo en tiempo discretoDocumento16 páginasPlanteamiento del problema de control óptimo en tiempo discretoHillary Torres MoraAún no hay calificaciones
- Rodriguez - Optimizacion Dinamica (Continuo)Documento36 páginasRodriguez - Optimizacion Dinamica (Continuo)Rodrigo MorenoAún no hay calificaciones
- 5b-Control Optimo Sistemas ContinuosDocumento10 páginas5b-Control Optimo Sistemas ContinuosPablys ZúñigaAún no hay calificaciones
- Elementos de Programación DinámicaDocumento10 páginasElementos de Programación DinámicaMiguel Tasayco MartinezAún no hay calificaciones
- Control OptimoDocumento11 páginasControl OptimoRonyVargasAún no hay calificaciones
- Ejercicios de Ecuaciones Diferenciales OrdinariasDe EverandEjercicios de Ecuaciones Diferenciales OrdinariasCalificación: 4 de 5 estrellas4/5 (1)
- Ecuaciones de voltaje máquinas polos salientesDocumento5 páginasEcuaciones de voltaje máquinas polos salientesByron Paul Montufar AyalaAún no hay calificaciones
- Sistemas de Control AutomaticoDocumento25 páginasSistemas de Control AutomaticoYessyRinconAún no hay calificaciones
- Wolfram AlphaDocumento20 páginasWolfram AlphaCarlos YaelAún no hay calificaciones
- Cuestionario de Repaso Primer BimestreDocumento10 páginasCuestionario de Repaso Primer BimestreAndres RojasAún no hay calificaciones
- Plan de área de matemáticas grado sexto colegio Padre Rafael GarcíaDocumento18 páginasPlan de área de matemáticas grado sexto colegio Padre Rafael Garcíapedro manuel negron henaoAún no hay calificaciones
- Garrido - Diseño, Análisis y Estabilidad de Métodos Iterativos Con Memoria para La Resolución de ...Documento273 páginasGarrido - Diseño, Análisis y Estabilidad de Métodos Iterativos Con Memoria para La Resolución de ...ja gmAún no hay calificaciones
- Curso de Informes Técnicos PDFDocumento98 páginasCurso de Informes Técnicos PDFSebastian Alejandro Boscarino CorcegaAún no hay calificaciones
- Capítulo Vii-AmiiiDocumento86 páginasCapítulo Vii-AmiiiEduardo Arribasplata NimbomaAún no hay calificaciones
- Tarea 2 Algebra SimbolicaDocumento9 páginasTarea 2 Algebra SimbolicaDaysuris Lorena Valencia50% (2)
- Potencias - Ecuacion y Funcion ExponencialDocumento16 páginasPotencias - Ecuacion y Funcion ExponencialAlfredo AstrainAún no hay calificaciones
- Matematicas para Ingenieria IDocumento23 páginasMatematicas para Ingenieria IJesus GarciaAún no hay calificaciones
- Informe 4 - InfiltraciónDocumento12 páginasInforme 4 - InfiltraciónJoshua Sebastian Vargas NacarinoAún no hay calificaciones
- Antologıa Razonamiento MatematicoDocumento28 páginasAntologıa Razonamiento Matematicodjoser89Aún no hay calificaciones
- GUIA DE ESTUDIO FISICA 3er Año - 2DA FASEDocumento12 páginasGUIA DE ESTUDIO FISICA 3er Año - 2DA FASEElizabeth RiveroAún no hay calificaciones
- Cuestionario 3Documento3 páginasCuestionario 3Oscar Perez DiazAún no hay calificaciones
- Teoria de EcuacionesDocumento13 páginasTeoria de EcuacionesCarlos Arturo Sandoval SandovalAún no hay calificaciones
- Caida LibreDocumento13 páginasCaida LibreJuan MartinezAún no hay calificaciones
- SESION Resolvemos Problemas de Ecuaciones PrimeroDocumento6 páginasSESION Resolvemos Problemas de Ecuaciones PrimeroTatianita Diaz QAún no hay calificaciones
- Practica MatricesDocumento4 páginasPractica MatricesRafael Molina SalazarAún no hay calificaciones
- Calculo variacional sistemasDocumento63 páginasCalculo variacional sistemasJuan GarciaAún no hay calificaciones
- Cinco Ecuaciones Que Cambiaron Al MundoDocumento2 páginasCinco Ecuaciones Que Cambiaron Al MundoIsaias MaderaAún no hay calificaciones
- GUIA PAD MatemáticasDocumento61 páginasGUIA PAD MatemáticasAristoteles Flores BravoAún no hay calificaciones
- LISTA DE EJERCICIOS 1 - EDO Primer Orden. Solución de Una EDODocumento2 páginasLISTA DE EJERCICIOS 1 - EDO Primer Orden. Solución de Una EDOEnmanuel BozaAún no hay calificaciones
- Ejemplo de Sistema Discreto y ContinuoDocumento5 páginasEjemplo de Sistema Discreto y ContinuoB19690521 JAHIR ALEJANDRO HERRERA MENDOZAAún no hay calificaciones
- Asentamientos CompletoDocumento71 páginasAsentamientos CompletoLuis Humberto Niño AlvarezAún no hay calificaciones
- Canales Abaiertos: Ecuacion de BernoulliDocumento8 páginasCanales Abaiertos: Ecuacion de BernoulliRuler Altamirano AtaoAún no hay calificaciones
- Libro en Avance de Ma-124Documento187 páginasLibro en Avance de Ma-124Martin Colán QuevedoAún no hay calificaciones
- Semana15 Sist Edo KUTTA JJAI - EstudiantesDocumento12 páginasSemana15 Sist Edo KUTTA JJAI - EstudiantesRAVEN MANAún no hay calificaciones
- ZZ Taller I Corte I Algebra 3x1 2023Documento2 páginasZZ Taller I Corte I Algebra 3x1 2023Camilo OrtizAún no hay calificaciones