También podría gustarte
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- Taller MuestreoDocumento21 páginasTaller MuestreoMelissa Osorio Espitia100% (4)
- Estadísticas descriptivas de datos empresariales y deportivosDocumento3 páginasEstadísticas descriptivas de datos empresariales y deportivosEstefi Salazar Monsalve25% (4)
- Manual de PSPPDocumento31 páginasManual de PSPPIsaac Perez MorenoAún no hay calificaciones
- Finanzas 2 PracticaDocumento34 páginasFinanzas 2 PracticaJhon Bilmer Zarate FloresAún no hay calificaciones
- ApuntesestadísticaDocumento7 páginasApuntesestadísticaNajma HaidarAún no hay calificaciones
- TEMA 1 EstadísticaDocumento6 páginasTEMA 1 EstadísticaJorge Rojas LopezAún no hay calificaciones
- EstadisticaDocumento9 páginasEstadisticapaola veraAún no hay calificaciones
- Dia 3. AED y ProfilingDocumento73 páginasDia 3. AED y ProfilingSimon RodriguezAún no hay calificaciones
- Estadística descriptiva Murcia UPTCDocumento21 páginasEstadística descriptiva Murcia UPTCDA OscAún no hay calificaciones
- Tema 1 - EstadísticaDocumento43 páginasTema 1 - EstadísticaEdgard TellezAún no hay calificaciones
- MODULO ESTADÍSTICADocumento20 páginasMODULO ESTADÍSTICAAriel PillanaAún no hay calificaciones
- 2022 Resumen Estadística DescriptivaDocumento10 páginas2022 Resumen Estadística Descriptivaruben ulloaAún no hay calificaciones
- Estadística descriptiva unidimensionalDocumento50 páginasEstadística descriptiva unidimensionalanaAún no hay calificaciones
- Resumen EstadisticaDocumento56 páginasResumen EstadisticailatinaAún no hay calificaciones
- Estadística Descriptiva Escuela EnfermeríaDocumento11 páginasEstadística Descriptiva Escuela EnfermeríaMartinaAún no hay calificaciones
- Descr P TivaDocumento2 páginasDescr P TivaDaniel Mendoza PerezAún no hay calificaciones
- Tema I Estadistica DescriptivaDocumento60 páginasTema I Estadistica DescriptivaDenny PérezAún no hay calificaciones
- Introducción a la estadística descriptivaDocumento34 páginasIntroducción a la estadística descriptivaAlba Saez MoralesAún no hay calificaciones
- Estadistica DescriptivaDocumento29 páginasEstadistica DescriptivaCristy CorderoAún no hay calificaciones
- Qué Es La EstadísticaDocumento9 páginasQué Es La Estadísticaapi-3697274100% (2)
- Clasificación de Las VariablesDocumento1 páginaClasificación de Las VariablesEdward CarranzaAún no hay calificaciones
- Apuntes de Estadística y Probabilidad 1º EsoDocumento6 páginasApuntes de Estadística y Probabilidad 1º EsoJuanAún no hay calificaciones
- Material teórico didáctico - Estadística I 2023Documento33 páginasMaterial teórico didáctico - Estadística I 2023uliser omar Barrios EscobarAún no hay calificaciones
- ESTADÍSTICA Matemática AplicadaDocumento15 páginasESTADÍSTICA Matemática Aplicadaselvakornoski100% (27)
- Glosario EstadisticoDocumento22 páginasGlosario EstadisticoRogelio Hernandez GAún no hay calificaciones
- Descript IvaDocumento57 páginasDescript IvaLeila Padilla BenitezAún no hay calificaciones
- Conceptos Previos EstadisticaDocumento9 páginasConceptos Previos EstadisticaAyse RomeroAún no hay calificaciones
- Resumen Básico EstadísticaDocumento9 páginasResumen Básico Estadístican.bwv1041Aún no hay calificaciones
- Sesion 2Documento21 páginasSesion 2Dilman Alberto Ccotahuana HuarcaAún no hay calificaciones
- Estadística descriptiva univariante: distribuciones de frecuencias y medidas descriptivasDocumento30 páginasEstadística descriptiva univariante: distribuciones de frecuencias y medidas descriptivasAlba MegiasAún no hay calificaciones
- Estadística con Excel: Análisis de datosDocumento4 páginasEstadística con Excel: Análisis de datosMarcia Katharine Chacon VasquezAún no hay calificaciones
- EstadísticaDocumento11 páginasEstadísticaRomina FloresAún no hay calificaciones
- Tema Nº2Documento12 páginasTema Nº2Tati TurbayAún no hay calificaciones
- Módulo 1Documento19 páginasMódulo 1FelipeAún no hay calificaciones
- Apunte 1 Estadistica DescriptivaDocumento16 páginasApunte 1 Estadistica DescriptivaJosefa Villablanca LeonAún no hay calificaciones
- Unidad I Herramientas Estadisticas 1.1 Introducción A La Estadistica EstadísticaDocumento10 páginasUnidad I Herramientas Estadisticas 1.1 Introducción A La Estadistica EstadísticaJuan Diego HolguinAún no hay calificaciones
- Estadistica y ProbabilidadDocumento7 páginasEstadistica y ProbabilidadCamii DiazAún no hay calificaciones
- Guía BioestadísticaDocumento24 páginasGuía BioestadísticadaniloAún no hay calificaciones
- Universidad Nacional José María ArguedasDocumento9 páginasUniversidad Nacional José María ArguedasBRAY YUSMAN QUISPE ATAOAún no hay calificaciones
- Apuntes de EstadisticasDocumento3 páginasApuntes de EstadisticasyaninaAún no hay calificaciones
- Trabajo de EstadísticaDocumento6 páginasTrabajo de EstadísticaAndrés CorderoAún no hay calificaciones
- EstadísticaDocumento5 páginasEstadísticaagos11ochoaAún no hay calificaciones
- Estadistica Descriptiva - Resumen - Lic MaguiñaDocumento26 páginasEstadistica Descriptiva - Resumen - Lic MaguiñaRicardo Ubillus RuizAún no hay calificaciones
- Curso Introducción A La Estadística - IIDocumento61 páginasCurso Introducción A La Estadística - IIluis garciaAún no hay calificaciones
- Curso Estadística I UMGDocumento12 páginasCurso Estadística I UMGLuis Lopez100% (1)
- Bioestadísitica - Estadística DescriptivaDocumento12 páginasBioestadísitica - Estadística DescriptivaPaula BarrientosAún no hay calificaciones
- Preguntas Orientadoras Estadistica DescriptivaDocumento13 páginasPreguntas Orientadoras Estadistica Descriptivacarlos albertoAún no hay calificaciones
- Guia Frecuencias - Tablas Estadisticas 10ºDocumento3 páginasGuia Frecuencias - Tablas Estadisticas 10ºMaría Antonia Marín GarcíaAún no hay calificaciones
- Pruebas de Bondad de Ajuste Chi Cuadrada y Kolmogorov SmirnovDocumento23 páginasPruebas de Bondad de Ajuste Chi Cuadrada y Kolmogorov SmirnovMatilde Gallegos MonzonAún no hay calificaciones
- Estadìstica PDFDocumento72 páginasEstadìstica PDFJesuusAyquipaMendozaAún no hay calificaciones
- ESTADISTICA ResumenDocumento15 páginasESTADISTICA ResumenmilagrosgoparnutriAún no hay calificaciones
- Estadística descriptiva guíaDocumento28 páginasEstadística descriptiva guíaJuan Camilo Rodriguez SaninAún no hay calificaciones
- 01 Estadística DescriptivaDocumento18 páginas01 Estadística DescriptivaJaimeAún no hay calificaciones
- 170-Texto Del Artículo-225-1-10-20210818Documento22 páginas170-Texto Del Artículo-225-1-10-20210818Ana Milena Lopez DiazAún no hay calificaciones
- Probabilidad y Estadistica CAPITULO 1Documento37 páginasProbabilidad y Estadistica CAPITULO 1JAVIER EDUARDO CANTILLO BARRIOSAún no hay calificaciones
- Conceptos, Tablas, Gráficos Estadísticos 2 Ciclo 2 Periodo 2021Documento8 páginasConceptos, Tablas, Gráficos Estadísticos 2 Ciclo 2 Periodo 2021Yasmila Mosquera MurilloAún no hay calificaciones
- Métodos descriptivos cualitativosDocumento77 páginasMétodos descriptivos cualitativosAlex GimenezAún no hay calificaciones
- Apuntes de EstadisticasDocumento3 páginasApuntes de EstadisticasYanina LilianaAún no hay calificaciones
- Recolección, organización y presentación de datosDocumento9 páginasRecolección, organización y presentación de datoseliasviotti95Aún no hay calificaciones
- Estadística (Descriptiva)Documento12 páginasEstadística (Descriptiva)Siverio GianAún no hay calificaciones
- Nuevo Documento de Microsoft WordDocumento5 páginasNuevo Documento de Microsoft WordYelitza PerezAún no hay calificaciones
- Conceptos EstadísticosDocumento49 páginasConceptos EstadísticosKristianskrillex1080 HDAún no hay calificaciones
- Tema 3 - ProbabilidadDocumento6 páginasTema 3 - ProbabilidadLaviniaMenicucciAún no hay calificaciones
- 2.3. Tres Principios de NadaDocumento33 páginas2.3. Tres Principios de NadaLaviniaMenicucciAún no hay calificaciones
- Tema 2 - Regresión LinealDocumento6 páginasTema 2 - Regresión LinealLaviniaMenicucciAún no hay calificaciones
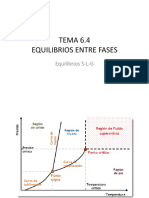
- 2.4 Equilibrio Entre Fases PDFDocumento28 páginas2.4 Equilibrio Entre Fases PDFLaviniaMenicucciAún no hay calificaciones
- 2.1. Cambios de Estado PDFDocumento36 páginas2.1. Cambios de Estado PDFLaviniaMenicucciAún no hay calificaciones
- Boletín de Ejercicios Termodinámica PDFDocumento2 páginasBoletín de Ejercicios Termodinámica PDFLaviniaMenicucciAún no hay calificaciones
- 2.2 Fundamentos TermodinámicosDocumento10 páginas2.2 Fundamentos TermodinámicosLaviniaMenicucciAún no hay calificaciones
- Trabajo de AnalfabetismoDocumento17 páginasTrabajo de Analfabetismoyessica100% (1)
- Estadística InferencialDocumento9 páginasEstadística InferencialecojaqueAún no hay calificaciones
- Funciones Estadísticas ExcelDocumento4 páginasFunciones Estadísticas ExcelhernanchoAún no hay calificaciones
- Estadistica Aplicada 1Documento4 páginasEstadistica Aplicada 1JaelAún no hay calificaciones
- Rendimiento y Distribucion Del TiempoDocumento15 páginasRendimiento y Distribucion Del Tiempojapr11Aún no hay calificaciones
- Avance Informe ABP Estadística Descriptiva GrupDocumento7 páginasAvance Informe ABP Estadística Descriptiva GrupJOSE DANIEL GARCIA MEJIAAún no hay calificaciones
- AP429 SESION SINCRONA 5 Análisis Descriptivo en Business AnalyticsDocumento50 páginasAP429 SESION SINCRONA 5 Análisis Descriptivo en Business AnalyticsLuz SebastianAún no hay calificaciones
- La Teoría Moderna de PortafoliosDocumento8 páginasLa Teoría Moderna de PortafoliosSara Estefania Vargas GomezAún no hay calificaciones
- TArea Estadistica JulioDocumento8 páginasTArea Estadistica JulioLucho TorresAún no hay calificaciones
- Control de Calidad y Validación Del Diagnóstico Inmunológico en El Banco de SangreDocumento75 páginasControl de Calidad y Validación Del Diagnóstico Inmunológico en El Banco de SangreVictorAún no hay calificaciones
- Trabajo Estadística InferencialDocumento24 páginasTrabajo Estadística InferencialSebastian GamarraAún no hay calificaciones
- TallerINTERVALOS ParejasDocumento3 páginasTallerINTERVALOS ParejasYiduar Yair Escarraga TrianaAún no hay calificaciones
- Talle R 1Documento4 páginasTalle R 1andresAún no hay calificaciones
- Taller 1 BAIN091 2do S 2022Documento2 páginasTaller 1 BAIN091 2do S 2022benjaminAún no hay calificaciones
- Ejercicios Estadistica Intervalos de ConfianzaDocumento3 páginasEjercicios Estadistica Intervalos de ConfianzaRodrigo FarfánAún no hay calificaciones
- Apuntes EstadísticaDocumento32 páginasApuntes Estadísticaale2702gAún no hay calificaciones
- Deber 1Documento10 páginasDeber 1Brayan Duarte AlbaAún no hay calificaciones
- PDF 03prueba de Hipotesis - Compress PDFDocumento4 páginasPDF 03prueba de Hipotesis - Compress PDFPathi QuirozAún no hay calificaciones
- Prueba hipótesis paramétrica muestras independientesDocumento22 páginasPrueba hipótesis paramétrica muestras independientesfrankAún no hay calificaciones
- Tema 3 EstadisticaDocumento14 páginasTema 3 Estadisticamaikel da silvaAún no hay calificaciones
- Concepto de Desviacion EstandarDocumento7 páginasConcepto de Desviacion EstandarSF CesarAún no hay calificaciones
- 07 PruebasHipótesisDocumento21 páginas07 PruebasHipótesisAlex AlexAún no hay calificaciones
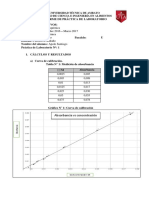
- InformeN° 1.1.absorbancia - FQDocumento4 páginasInformeN° 1.1.absorbancia - FQSanty ApoloAún no hay calificaciones
- Ejercicios Capitulo 3 (Autoguardado)Documento11 páginasEjercicios Capitulo 3 (Autoguardado)Edwin Lique HumerezAún no hay calificaciones
- Tarea 1EstadísticaII S1Documento2 páginasTarea 1EstadísticaII S1Arlett PaladaAún no hay calificaciones
- Estadistica IIDocumento18 páginasEstadistica IIariana polancoAún no hay calificaciones