También podría gustarte
- Sistemas eléctrico y electrónico del automóvil.: Tecnología automotriz: mantenimiento y reparación de vehículosDe EverandSistemas eléctrico y electrónico del automóvil.: Tecnología automotriz: mantenimiento y reparación de vehículosCalificación: 4 de 5 estrellas4/5 (62)
- Arquitectura sustentable: Más que una nueva tendencia, una necesidadDe EverandArquitectura sustentable: Más que una nueva tendencia, una necesidadAún no hay calificaciones
- Detección y compensación de irregularidades de inyecciónDe EverandDetección y compensación de irregularidades de inyecciónAún no hay calificaciones
- Recirculación de gases de escape mediante sistemas de baja presión en motores diésel sobrealimentadosDe EverandRecirculación de gases de escape mediante sistemas de baja presión en motores diésel sobrealimentadosCalificación: 3 de 5 estrellas3/5 (3)
- Guía de laboratorio de mecánica de fluidosDe EverandGuía de laboratorio de mecánica de fluidosAún no hay calificaciones
- Diagnóstico avanzado de fallas automotrices.: Tecnología automotriz: mantenimiento y reparación de vehículosDe EverandDiagnóstico avanzado de fallas automotrices.: Tecnología automotriz: mantenimiento y reparación de vehículosCalificación: 3.5 de 5 estrellas3.5/5 (9)
- Logística estadística: Gestión e indicadores en la cadena de suministroDe EverandLogística estadística: Gestión e indicadores en la cadena de suministroAún no hay calificaciones
- Análisis integral de pruebas de trazadores en yacimientos: Diseño, ejecución e interpretaciónDe EverandAnálisis integral de pruebas de trazadores en yacimientos: Diseño, ejecución e interpretaciónAún no hay calificaciones
- UF1880 - Gestión de redes telemáticasDe EverandUF1880 - Gestión de redes telemáticasAún no hay calificaciones
- Influencia de la cavitación sobre el desarrollo del chorro diéselDe EverandInfluencia de la cavitación sobre el desarrollo del chorro diéselAún no hay calificaciones
- Análisis estadístico de datos multivariadosDe EverandAnálisis estadístico de datos multivariadosCalificación: 5 de 5 estrellas5/5 (1)
- Econometría: modelos econométricos y series temporales. Tomo 2: Con los paquetes micro-TSP y TSPDe EverandEconometría: modelos econométricos y series temporales. Tomo 2: Con los paquetes micro-TSP y TSPAún no hay calificaciones
- Modelado fenomenológico del proceso de combustión por difusión diéselDe EverandModelado fenomenológico del proceso de combustión por difusión diéselAún no hay calificaciones
- Estadística multivariada: inferencia y métodosDe EverandEstadística multivariada: inferencia y métodosAún no hay calificaciones
- Ecología Aplicada: Diseño y análisis estadísticoDe EverandEcología Aplicada: Diseño y análisis estadísticoCalificación: 5 de 5 estrellas5/5 (1)
- Manual de hidrología para obras viales basado en el uso de sistemas de información geográfica.De EverandManual de hidrología para obras viales basado en el uso de sistemas de información geográfica.Calificación: 5 de 5 estrellas5/5 (2)
- Teoría clásica del crecimiento económico: Modelos de crecimiento exógenoDe EverandTeoría clásica del crecimiento económico: Modelos de crecimiento exógenoAún no hay calificaciones
- KNX. Domótica e Inmótica: Guía Práctica para el instaladorDe EverandKNX. Domótica e Inmótica: Guía Práctica para el instaladorCalificación: 5 de 5 estrellas5/5 (1)
- Formulación y evaluación de proyectos agropecuarios: Estructura del proyecto agropecuario, con enfoque de marco lógico - 1ra ediciónDe EverandFormulación y evaluación de proyectos agropecuarios: Estructura del proyecto agropecuario, con enfoque de marco lógico - 1ra ediciónCalificación: 5 de 5 estrellas5/5 (2)
- Introducción al análisis de supervivencia avanzadaDe EverandIntroducción al análisis de supervivencia avanzadaAún no hay calificaciones
- Estudio del comportamiento del chorro diésel en campo próximoDe EverandEstudio del comportamiento del chorro diésel en campo próximoAún no hay calificaciones
- Manual de laboratorio de estructurasDe EverandManual de laboratorio de estructurasAún no hay calificaciones
- Análisis de chorros diésel mediante fluorescencia inducida por laserDe EverandAnálisis de chorros diésel mediante fluorescencia inducida por laserAún no hay calificaciones
- Modelado tridimensional del flujo de aire en el cilindro de motores diésel de inyección directaDe EverandModelado tridimensional del flujo de aire en el cilindro de motores diésel de inyección directaAún no hay calificaciones
- Formación de Auxiliar de Odontología en menos de 40 horasDocumento18 páginasFormación de Auxiliar de Odontología en menos de 40 horasJose PaulAún no hay calificaciones
- Modelado unidimensional de los motores de dos tiempos de pequeña cilindradaDe EverandModelado unidimensional de los motores de dos tiempos de pequeña cilindradaCalificación: 5 de 5 estrellas5/5 (1)
- Análisis estructural de sectores estratégicosDe EverandAnálisis estructural de sectores estratégicosAún no hay calificaciones
- Modelado Euleriano de flujo bifásico para el cálculo CFD de chorros diéselDe EverandModelado Euleriano de flujo bifásico para el cálculo CFD de chorros diéselAún no hay calificaciones
- Administración de sistemas gestores de bases de datosDe EverandAdministración de sistemas gestores de bases de datosAún no hay calificaciones
- Practica 5Documento2 páginasPractica 5Hermilo Robledo100% (1)
- Predicción y optimización de emisiores y consumo mediante redes neuronales en motores diéselDe EverandPredicción y optimización de emisiores y consumo mediante redes neuronales en motores diéselAún no hay calificaciones
- Programa Curricular de Educación Básica Alternativa. Ciclo AvanzadoDocumento150 páginasPrograma Curricular de Educación Básica Alternativa. Ciclo AvanzadoLicida Flor Rodriguez BustamanteAún no hay calificaciones
- Diseño de Bocatomas - Alfredo ManseDocumento47 páginasDiseño de Bocatomas - Alfredo ManseJohn E Gomez P83% (6)
- Gerencia de NegociosDocumento30 páginasGerencia de NegociosDavid BonillaAún no hay calificaciones
- Cálculo termofluidodinámico de filtros de partículas de flujo de paredDe EverandCálculo termofluidodinámico de filtros de partículas de flujo de paredCalificación: 5 de 5 estrellas5/5 (1)
- Costes del 'Urban Sprawl' para la Administración local: El caso valencianoDe EverandCostes del 'Urban Sprawl' para la Administración local: El caso valencianoAún no hay calificaciones
- Estudio de los efectos de la cavitación en toberas de inyección diésel sobre los procesos de inyección y de formación de hollínDe EverandEstudio de los efectos de la cavitación en toberas de inyección diésel sobre los procesos de inyección y de formación de hollínCalificación: 5 de 5 estrellas5/5 (2)
- Ollas AgitacionDocumento203 páginasOllas AgitacionpacoAún no hay calificaciones
- Minería de Datos para Series Temporales en Weka y Su Aplicación en El Pronóstico de PrecipitacionesDocumento93 páginasMinería de Datos para Series Temporales en Weka y Su Aplicación en El Pronóstico de PrecipitacionesAlfredo Avendaño SerranoAún no hay calificaciones
- Nacional 1Documento122 páginasNacional 1Dante 96Aún no hay calificaciones
- Proyecto de Grado para Optar Por El Título de Ingeniero de Telecomunicaciones. Juan Fernando Cifuentes Obando Cod - PDFDocumento90 páginasProyecto de Grado para Optar Por El Título de Ingeniero de Telecomunicaciones. Juan Fernando Cifuentes Obando Cod - PDFYohana CanoAún no hay calificaciones
- Modelos Digitales Del TerrenoDocumento122 páginasModelos Digitales Del TerrenoJuan CasherAún no hay calificaciones
- IPO429 ModelacionHidrologica June2020Documento3 páginasIPO429 ModelacionHidrologica June2020FelipeGo199Aún no hay calificaciones
- Programaanlitico 2017Documento4 páginasProgramaanlitico 2017Ivan AcostaAún no hay calificaciones
- Tesis TwiDocumento128 páginasTesis TwiOrlandoRenzoAún no hay calificaciones
- VillaMartinezFernandoA MANAV 2019Documento78 páginasVillaMartinezFernandoA MANAV 2019Almanelly Bartolo FloresAún no hay calificaciones
- Escuela Politécnica Nacional: Escuela de IngenieríaDocumento166 páginasEscuela Politécnica Nacional: Escuela de IngenieríaDayanaAún no hay calificaciones
- MDT en ciencias ambientalesDocumento66 páginasMDT en ciencias ambientalesddd0511Aún no hay calificaciones
- Model Digital de TerrenosDocumento122 páginasModel Digital de TerrenosDexterAún no hay calificaciones
- T1241 PDFDocumento137 páginasT1241 PDFCarlos RiveraAún no hay calificaciones
- Informe de Delimitación Nathaly M. Huamaní Quispe-AmbientalDocumento28 páginasInforme de Delimitación Nathaly M. Huamaní Quispe-AmbientalNathalyAún no hay calificaciones
- Métodos numéricos con introducción al método de Adomian y las series de FourierDe EverandMétodos numéricos con introducción al método de Adomian y las series de FourierAún no hay calificaciones
- Crecimiento urbanístico en la zona costera de la Comunidad Valenciana (1987-2009): Análisis y perspectivas de futuroDe EverandCrecimiento urbanístico en la zona costera de la Comunidad Valenciana (1987-2009): Análisis y perspectivas de futuroCalificación: 3 de 5 estrellas3/5 (1)
- Fundamentos de la prospectiva en sistemas de informaciónDe EverandFundamentos de la prospectiva en sistemas de informaciónAún no hay calificaciones
- Ciclos logísticos - 1ra edición: Planeación y estrategias en la cadena de suministroDe EverandCiclos logísticos - 1ra edición: Planeación y estrategias en la cadena de suministroAún no hay calificaciones
- Folleto - Tacazo®Documento2 páginasFolleto - Tacazo®luli_kbreraAún no hay calificaciones
- Taller1 Reconocimiento de VinosDocumento9 páginasTaller1 Reconocimiento de Vinosluli_kbreraAún no hay calificaciones
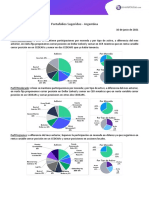
- Portafolios Sugeridos - ArgentinaDocumento17 páginasPortafolios Sugeridos - Argentinaluli_kbreraAún no hay calificaciones
- Logica DifusaDocumento4 páginasLogica Difusaluli_kbreraAún no hay calificaciones
- Portfolio Arg 25-02-2021Documento12 páginasPortfolio Arg 25-02-2021luli_kbreraAún no hay calificaciones
- Reforma de Ley Nacional de Educación SexualDocumento1 páginaReforma de Ley Nacional de Educación Sexualluli_kbreraAún no hay calificaciones
- Portfolio Arg 31-03-2021Documento14 páginasPortfolio Arg 31-03-2021luli_kbreraAún no hay calificaciones
- Portfolio Arg 05-05-2021Documento15 páginasPortfolio Arg 05-05-2021luli_kbreraAún no hay calificaciones
- Acciones ResumenDocumento1 páginaAcciones Resumenluli_kbreraAún no hay calificaciones
- Portfolio Arg 15-01-2021Documento11 páginasPortfolio Arg 15-01-2021luli_kbreraAún no hay calificaciones
- Reporte Diario Nacional de Pacientes Con CoronavirusDocumento2 páginasReporte Diario Nacional de Pacientes Con CoronavirusFranco CenciAún no hay calificaciones
- Las Nuevas Líneas de Falla en La Economía Mundial, Según The Economist - LA NACIONDocumento17 páginasLas Nuevas Líneas de Falla en La Economía Mundial, Según The Economist - LA NACIONluli_kbreraAún no hay calificaciones
- MineradedatosparaSeriesTemporales PDFDocumento54 páginasMineradedatosparaSeriesTemporales PDFluli_kbreraAún no hay calificaciones
- Seguros paramétricos: introducción a sus características y tipos de índicesDocumento15 páginasSeguros paramétricos: introducción a sus características y tipos de índicesmotaocAún no hay calificaciones
- Seguros ParametricosDocumento136 páginasSeguros Parametricosluli_kbreraAún no hay calificaciones
- Seguros paramétricos: introducción a sus características y tipos de índicesDocumento15 páginasSeguros paramétricos: introducción a sus características y tipos de índicesmotaocAún no hay calificaciones
- Hidro2016 0006Documento68 páginasHidro2016 0006luli_kbreraAún no hay calificaciones
- Fútbol y Matemáticas - Recurso Metodológico (Aplicaciones Básicas) - Jagg PDFDocumento9 páginasFútbol y Matemáticas - Recurso Metodológico (Aplicaciones Básicas) - Jagg PDFSalva CarrilAún no hay calificaciones
- 1629166473.95 Evapro Análisis de RiesgoDocumento33 páginas1629166473.95 Evapro Análisis de RiesgoDesayunos DestellizAún no hay calificaciones
- InterpolaciónDocumento28 páginasInterpolaciónAbel VenAún no hay calificaciones
- Ensayo4t34 PDFDocumento12 páginasEnsayo4t34 PDFluli_kbreraAún no hay calificaciones
- Economia de La EmpresaDocumento10 páginasEconomia de La EmpresamidialaoropesaAún no hay calificaciones
- WMO168 Ed2008 Vol I Ch3 Up2008 EsDocumento35 páginasWMO168 Ed2008 Vol I Ch3 Up2008 Esjose bari regalado andoaAún no hay calificaciones
- Guia Practica de Clasificacion de Imagenes Satelitales IlwisDocumento31 páginasGuia Practica de Clasificacion de Imagenes Satelitales IlwisVilchez Arroyo RicharsAún no hay calificaciones
- Proyectos EspecialesDocumento59 páginasProyectos EspecialesmohamedazabAún no hay calificaciones
- Machine Learning Strategies For Time Series Forecasting: Lecture Notes in Business Information Processing January 2013Documento17 páginasMachine Learning Strategies For Time Series Forecasting: Lecture Notes in Business Information Processing January 2013luli_kbreraAún no hay calificaciones
- Modelos para La Toma de Decisiones SEPTIEMBRE 2012Documento78 páginasModelos para La Toma de Decisiones SEPTIEMBRE 2012charlyvldzAún no hay calificaciones
- Teledetección AgrícolaDocumento18 páginasTeledetección Agrícolaluli_kbreraAún no hay calificaciones
- Listado CIIUDocumento21 páginasListado CIIUMariana Cecilia ArruzazabalaAún no hay calificaciones
- Manual Camara Wifi PDFDocumento27 páginasManual Camara Wifi PDFAlvaroAún no hay calificaciones
- Triptico CancerDocumento2 páginasTriptico CancerdenisguilleAún no hay calificaciones
- ATPIIIDocumento12 páginasATPIIIgiannaAún no hay calificaciones
- Salud y Prevención de EnfermedadesDocumento5 páginasSalud y Prevención de EnfermedadesCarolina Silva GonzálezAún no hay calificaciones
- Cantidad de Movimiento - ChoquesDocumento7 páginasCantidad de Movimiento - ChoquesMiguelAún no hay calificaciones
- PDFServletDocumento2 páginasPDFServletIvan Hernandez BecerraAún no hay calificaciones
- Practica 1Documento8 páginasPractica 1MarioAún no hay calificaciones
- Ontología y Lenguaje de La Realidad SocialDocumento10 páginasOntología y Lenguaje de La Realidad SocialCinta de MoebioAún no hay calificaciones
- La LATTICE y La ESTRUCTURA Del ESPACIODocumento5 páginasLa LATTICE y La ESTRUCTURA Del ESPACIOLuis ChavezAún no hay calificaciones
- Expo1 Materiales G7Documento16 páginasExpo1 Materiales G7Andres LopezAún no hay calificaciones
- Proyecto Educativo Davinci 2021 FinalDocumento23 páginasProyecto Educativo Davinci 2021 Finalian fuentesAún no hay calificaciones
- Economía - MonografíaDocumento9 páginasEconomía - MonografíaLAVALLE MACHUCA JACINTO ALFONSOAún no hay calificaciones
- Fractura de Cadera01Documento16 páginasFractura de Cadera01claudia casalAún no hay calificaciones
- DIAGNOSTICO DE ENFERMERÍA UltimoDocumento8 páginasDIAGNOSTICO DE ENFERMERÍA UltimoEthel Sharmila Chávez MarmanilloAún no hay calificaciones
- Registro Sonico BHCDocumento26 páginasRegistro Sonico BHCCristian Jasiel Barrios Suarez100% (1)
- Taller 26 Marzo PDFDocumento28 páginasTaller 26 Marzo PDFJose Alfredo Lozano ForeroAún no hay calificaciones
- Prueba de Infiltración en El Suelo Mediante Formula PorchetDocumento8 páginasPrueba de Infiltración en El Suelo Mediante Formula PorchetFernando PalmerosAún no hay calificaciones
- Guia Impresion 3d Anet EspañolDocumento55 páginasGuia Impresion 3d Anet EspañolWeyn ZictoAún no hay calificaciones
- Dioxido de CloroDocumento2 páginasDioxido de CloroKim CorreaAún no hay calificaciones
- Albeitar198 El Huevo Del FuturoDocumento44 páginasAlbeitar198 El Huevo Del FuturoINCOGNITO AudioboxAún no hay calificaciones
- Error Brother Error 46Documento3 páginasError Brother Error 46Juan L. Pucheta ObilAún no hay calificaciones
- Análisis de Sangre de Frotis de Sangre PeriféricaDocumento3 páginasAnálisis de Sangre de Frotis de Sangre PeriféricaNaty RodriguezAún no hay calificaciones
- Actividad 3 AntropologíaDocumento6 páginasActividad 3 AntropologíaAlisson HernandezAún no hay calificaciones
- Los simios hablantes: polémica sobre sus capacidades lingüísticasDocumento3 páginasLos simios hablantes: polémica sobre sus capacidades lingüísticasany solisAún no hay calificaciones
- COCHURADODocumento4 páginasCOCHURADOVaneAún no hay calificaciones