También podría gustarte
- The Yellow House: A Memoir (2019 National Book Award Winner)De EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Calificación: 4 de 5 estrellas4/5 (98)
- Abbas Et Al. - 2016 - Unusual Complication of Pituitary Macroadenoma A Case Report and ReviewDocumento5 páginasAbbas Et Al. - 2016 - Unusual Complication of Pituitary Macroadenoma A Case Report and ReviewflashjetAún no hay calificaciones
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeCalificación: 4 de 5 estrellas4/5 (5795)
- Nana Et Al. - 2014 - Left Renal Vein Thrombosis A Rare Cause of Acute Scrotal Pain PDFDocumento2 páginasNana Et Al. - 2014 - Left Renal Vein Thrombosis A Rare Cause of Acute Scrotal Pain PDFflashjetAún no hay calificaciones
- Shoe Dog: A Memoir by the Creator of NikeDe EverandShoe Dog: A Memoir by the Creator of NikeCalificación: 4.5 de 5 estrellas4.5/5 (537)
- Namburar Et Al. - 2018 - Waste Generated During Glaucoma Surgery A Comparison of Two Global Facilities PDFDocumento4 páginasNamburar Et Al. - 2018 - Waste Generated During Glaucoma Surgery A Comparison of Two Global Facilities PDFflashjetAún no hay calificaciones
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureCalificación: 4.5 de 5 estrellas4.5/5 (474)
- Abbas Et Al. - 2020 - Maneuvering The Management of A Rare Case of Primary Undifferentiated Cardiac Sarcoma PDFDocumento5 páginasAbbas Et Al. - 2020 - Maneuvering The Management of A Rare Case of Primary Undifferentiated Cardiac Sarcoma PDFflashjetAún no hay calificaciones
- Grit: The Power of Passion and PerseveranceDe EverandGrit: The Power of Passion and PerseveranceCalificación: 4 de 5 estrellas4/5 (588)
- Abbas Et Al. - 2013 - Posterior Reversible Encephalopathy Syndrome After Bevacizumab Therapy in A Normotensive PatientDocumento4 páginasAbbas Et Al. - 2013 - Posterior Reversible Encephalopathy Syndrome After Bevacizumab Therapy in A Normotensive PatientflashjetAún no hay calificaciones
- On Fire: The (Burning) Case for a Green New DealDe EverandOn Fire: The (Burning) Case for a Green New DealCalificación: 4 de 5 estrellas4/5 (74)
- Nascimento Et Al. - 2013 - Wearable Cardioverter Defibrillator in Stress Cardiomyopathy and Cardiac ArrestDocumento4 páginasNascimento Et Al. - 2013 - Wearable Cardioverter Defibrillator in Stress Cardiomyopathy and Cardiac ArrestflashjetAún no hay calificaciones
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryCalificación: 3.5 de 5 estrellas3.5/5 (231)
- Nascimento Et Al. - 2012 - Bloody Nipple Discharge in Infancy - Report of Two CasesDocumento3 páginasNascimento Et Al. - 2012 - Bloody Nipple Discharge in Infancy - Report of Two CasesflashjetAún no hay calificaciones
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceCalificación: 4 de 5 estrellas4/5 (895)
- Nasrat, Al-Alwan - 2012 - Medical Intervention in A Constitutionally Tall ChildDocumento3 páginasNasrat, Al-Alwan - 2012 - Medical Intervention in A Constitutionally Tall ChildflashjetAún no hay calificaciones
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe EverandNever Split the Difference: Negotiating As If Your Life Depended On ItCalificación: 4.5 de 5 estrellas4.5/5 (838)
- Nassani Et Al. - 2017 - Foreign Body Penetration Through Jejunal Loops Causing Renal Artery Thrombosis and Renal InfarctDocumento3 páginasNassani Et Al. - 2017 - Foreign Body Penetration Through Jejunal Loops Causing Renal Artery Thrombosis and Renal InfarctflashjetAún no hay calificaciones
- The Little Book of Hygge: Danish Secrets to Happy LivingDe EverandThe Little Book of Hygge: Danish Secrets to Happy LivingCalificación: 3.5 de 5 estrellas3.5/5 (400)
- Nascimento Et Al. - 2012 - Adrenoleukodystrophy A Forgotten Diagnosis in Children With Primary Addison' S DiseaseDocumento5 páginasNascimento Et Al. - 2012 - Adrenoleukodystrophy A Forgotten Diagnosis in Children With Primary Addison' S DiseaseflashjetAún no hay calificaciones
- Notes 190915 213814 Ea7 PDFDocumento1 páginaNotes 190915 213814 Ea7 PDFflashjetAún no hay calificaciones
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersCalificación: 4.5 de 5 estrellas4.5/5 (345)
- Nascimento Et Al. - 2013 - Asymptomatic Anomalous Left Anterior Descending Artery Arising From The Right Coronary Artery With A Rare AntDocumento3 páginasNascimento Et Al. - 2013 - Asymptomatic Anomalous Left Anterior Descending Artery Arising From The Right Coronary Artery With A Rare AntflashjetAún no hay calificaciones
- Nasser Et Al. - 2013 - Use of Transoesophageal Echocardiography in Endovascular Stenting For Superior Vena Cava SyndromeDocumento3 páginasNasser Et Al. - 2013 - Use of Transoesophageal Echocardiography in Endovascular Stenting For Superior Vena Cava SyndromeflashjetAún no hay calificaciones
- The Unwinding: An Inner History of the New AmericaDe EverandThe Unwinding: An Inner History of the New AmericaCalificación: 4 de 5 estrellas4/5 (45)
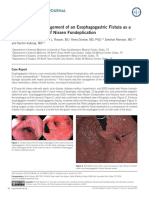
- Naveed Et Al. - 2015 - Diagnosis and Management of An Esophagogastric Fistula As A Rare Complication of Nissen FundoplicationDocumento2 páginasNaveed Et Al. - 2015 - Diagnosis and Management of An Esophagogastric Fistula As A Rare Complication of Nissen FundoplicationflashjetAún no hay calificaciones
- Team of Rivals: The Political Genius of Abraham LincolnDe EverandTeam of Rivals: The Political Genius of Abraham LincolnCalificación: 4.5 de 5 estrellas4.5/5 (234)
- Natrella Et Al. - 2012 - Rare Disease Supratentorial Neurenteric Cyst Associated With A Intraparenchymal SubependymomaDocumento6 páginasNatrella Et Al. - 2012 - Rare Disease Supratentorial Neurenteric Cyst Associated With A Intraparenchymal SubependymomaflashjetAún no hay calificaciones
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyCalificación: 3.5 de 5 estrellas3.5/5 (2259)
- Nguyen Et Al. - 2020 - Human Leukocyte Antigen Susceptibility Map For Severe Acute Respiratory Syndrome Coronavirus 2Documento36 páginasNguyen Et Al. - 2020 - Human Leukocyte Antigen Susceptibility Map For Severe Acute Respiratory Syndrome Coronavirus 2flashjetAún no hay calificaciones
- Naveen Et Al. - 2013 - Complete Denture With Pharyngeal Bulb ProsthesisDocumento4 páginasNaveen Et Al. - 2013 - Complete Denture With Pharyngeal Bulb ProsthesisflashjetAún no hay calificaciones
- Nathwani - 2013 - A Complicated Case of AnticoagulationDocumento2 páginasNathwani - 2013 - A Complicated Case of AnticoagulationflashjetAún no hay calificaciones
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaCalificación: 4.5 de 5 estrellas4.5/5 (266)
- Naveen Et Al. - 2014 - Alternatives For Restoration of A Hemisected Mandibular MolarDocumento4 páginasNaveen Et Al. - 2014 - Alternatives For Restoration of A Hemisected Mandibular MolarflashjetAún no hay calificaciones
- The Emperor of All Maladies: A Biography of CancerDe EverandThe Emperor of All Maladies: A Biography of CancerCalificación: 4.5 de 5 estrellas4.5/5 (271)
- Continuously Updated ALL USMLE DATADocumento4 páginasContinuously Updated ALL USMLE DATAflashjetAún no hay calificaciones
- Atopic Eczema Update Apr 2009Documento6 páginasAtopic Eczema Update Apr 2009flashjetAún no hay calificaciones
- Rise of ISIS: A Threat We Can't IgnoreDe EverandRise of ISIS: A Threat We Can't IgnoreCalificación: 3.5 de 5 estrellas3.5/5 (137)
- Idiopathic Stroke After Syndromic and Neuromuscular Scoliosis Surgery: A Case Report and Literature ReviewDocumento7 páginasIdiopathic Stroke After Syndromic and Neuromuscular Scoliosis Surgery: A Case Report and Literature ReviewflashjetAún no hay calificaciones
- Actinic Keratosis PIL Revision 2007Documento3 páginasActinic Keratosis PIL Revision 2007flashjetAún no hay calificaciones
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreCalificación: 4 de 5 estrellas4/5 (1090)
- Guidelines Guidelines For Prescribing Azathioprine in DermatologyDocumento10 páginasGuidelines Guidelines For Prescribing Azathioprine in DermatologyflashjetAún no hay calificaciones
- Syllabus (402050B) Finite Element Analysis (Elective IV)Documento3 páginasSyllabus (402050B) Finite Element Analysis (Elective IV)shekhusatavAún no hay calificaciones
- Technical Design of The Bukwimba Open Pit Final 12042017Documento31 páginasTechnical Design of The Bukwimba Open Pit Final 12042017Rozalia PengoAún no hay calificaciones
- Classical Feedback Control With MATLAB - Boris J. Lurie and Paul J. EnrightDocumento477 páginasClassical Feedback Control With MATLAB - Boris J. Lurie and Paul J. Enrightffranquiz100% (2)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Calificación: 4.5 de 5 estrellas4.5/5 (121)
- SweetenersDocumento23 páginasSweetenersNur AfifahAún no hay calificaciones
- WL4000Documento1 páginaWL4000Laser PowerAún no hay calificaciones
- Veg Dum Biryani - Hyderabadi Veg Biryani Recipe - Hyderabadi Biryani - Hebbar's KitchenDocumento2 páginasVeg Dum Biryani - Hyderabadi Veg Biryani Recipe - Hyderabadi Biryani - Hebbar's KitchenmusicalcarpetAún no hay calificaciones
- Aci 522R-06 PDFDocumento25 páginasAci 522R-06 PDFaldi raimon100% (2)
- Nitofloor NDocumento3 páginasNitofloor Nkiranmisale7Aún no hay calificaciones
- Nissan 720 L4-2.0-Z20 1983-86 Manual PDFDocumento641 páginasNissan 720 L4-2.0-Z20 1983-86 Manual PDFEduardo Ariel JuarezAún no hay calificaciones
- The Perks of Being a WallflowerDe EverandThe Perks of Being a WallflowerCalificación: 4.5 de 5 estrellas4.5/5 (2104)
- HPE 3PAR StoreServ 20000 Storage Service and Upgrade Guide Service EditionDocumento282 páginasHPE 3PAR StoreServ 20000 Storage Service and Upgrade Guide Service Editionben boltAún no hay calificaciones
- Nema MG10 PDFDocumento27 páginasNema MG10 PDFManuel Antonio Santos VargasAún no hay calificaciones
- International Travel Insurance Policy: PreambleDocumento20 páginasInternational Travel Insurance Policy: Preamblethakurankit212Aún no hay calificaciones
- Ayushi Environment FinalDocumento21 páginasAyushi Environment FinalRishabh SinghAún no hay calificaciones
- Her Body and Other Parties: StoriesDe EverandHer Body and Other Parties: StoriesCalificación: 4 de 5 estrellas4/5 (821)
- Medical CodingDocumento5 páginasMedical CodingBernard Paul GuintoAún no hay calificaciones
- ZW250-7 BROCHURE LowresDocumento12 páginasZW250-7 BROCHURE Lowresbjrock123Aún no hay calificaciones
- Quality Traits in Cultivated Mushrooms and Consumer AcceptabilityDocumento40 páginasQuality Traits in Cultivated Mushrooms and Consumer AcceptabilityShivendra SinghAún no hay calificaciones
- ESM-4810A1 Energy Storage Module User ManualDocumento31 páginasESM-4810A1 Energy Storage Module User ManualOscar SosaAún no hay calificaciones
- The Latent Phase of LaborDocumento8 páginasThe Latent Phase of LaborLoisana Meztli Figueroa PreciadoAún no hay calificaciones
- Advanced Aesthetics: The Definitive Guide For Building A Ripped and Muscular PhysiqueDocumento73 páginasAdvanced Aesthetics: The Definitive Guide For Building A Ripped and Muscular PhysiqueRoger murilloAún no hay calificaciones
- Curriculum VitaeDocumento7 páginasCurriculum VitaeRossy Del ValleAún no hay calificaciones
- Lec22 Mod 5-1 Copper New TechniquesDocumento24 páginasLec22 Mod 5-1 Copper New TechniquesAaila AkhterAún no hay calificaciones
- NDT Matrix 12-99-90-1710 - Rev.2 PDFDocumento2 páginasNDT Matrix 12-99-90-1710 - Rev.2 PDFEPC NCCAún no hay calificaciones
- T 1246784488 17108574 Street Lighting Control Based On LonWorks Power Line CommunicationDocumento3 páginasT 1246784488 17108574 Street Lighting Control Based On LonWorks Power Line CommunicationsryogaaAún no hay calificaciones
- Course On Quantum ComputingDocumento235 páginasCourse On Quantum ComputingAram ShojaeiAún no hay calificaciones
- Editor: Lalsangliana Jt. Ed.: H.Documento4 páginasEditor: Lalsangliana Jt. Ed.: H.bawihpuiapaAún no hay calificaciones
- Module 02 Connect Hardware Peripherals EndaleDocumento49 páginasModule 02 Connect Hardware Peripherals EndaleSoli Mondo100% (1)
- Thesis Brand BlanketDocumento4 páginasThesis Brand BlanketKayla Smith100% (2)
- Lecture 8Documento22 páginasLecture 8Ramil Jr. EntanaAún no hay calificaciones
- Outerstellar Self-Impose RulesDocumento1 páginaOuterstellar Self-Impose RulesIffu The war GodAún no hay calificaciones
- CFD Analysis of Flow Through Compressor CascadeDocumento10 páginasCFD Analysis of Flow Through Compressor CascadeKhalid KhalilAún no hay calificaciones
- Dark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseDe EverandDark Matter and the Dinosaurs: The Astounding Interconnectedness of the UniverseCalificación: 3.5 de 5 estrellas3.5/5 (69)
- 10% Human: How Your Body's Microbes Hold the Key to Health and HappinessDe Everand10% Human: How Your Body's Microbes Hold the Key to Health and HappinessCalificación: 4 de 5 estrellas4/5 (33)
- Return of the God Hypothesis: Three Scientific Discoveries That Reveal the Mind Behind the UniverseDe EverandReturn of the God Hypothesis: Three Scientific Discoveries That Reveal the Mind Behind the UniverseCalificación: 4.5 de 5 estrellas4.5/5 (52)
- When the Body Says No by Gabor Maté: Key Takeaways, Summary & AnalysisDe EverandWhen the Body Says No by Gabor Maté: Key Takeaways, Summary & AnalysisCalificación: 3.5 de 5 estrellas3.5/5 (2)
- Why We Die: The New Science of Aging and the Quest for ImmortalityDe EverandWhy We Die: The New Science of Aging and the Quest for ImmortalityCalificación: 4.5 de 5 estrellas4.5/5 (6)
- Alex & Me: How a Scientist and a Parrot Discovered a Hidden World of Animal Intelligence—and Formed a Deep Bond in the ProcessDe EverandAlex & Me: How a Scientist and a Parrot Discovered a Hidden World of Animal Intelligence—and Formed a Deep Bond in the ProcessAún no hay calificaciones