También podría gustarte
- Introducción a los Algoritmos y las Estructuras de Datos 2: Introducción a los Algoritmos y las Estructuras de Datos, #2De EverandIntroducción a los Algoritmos y las Estructuras de Datos 2: Introducción a los Algoritmos y las Estructuras de Datos, #2Aún no hay calificaciones
- ARAOZ DG Sílabo DISEÑO 2D 2022-IDocumento8 páginasARAOZ DG Sílabo DISEÑO 2D 2022-INeil BellidoAún no hay calificaciones
- Desarrollo de la aplicación Android: Guía turística para el municipio de CulleraDe EverandDesarrollo de la aplicación Android: Guía turística para el municipio de CulleraAún no hay calificaciones
- UML An Lección6 Actividades PrácticasDocumento5 páginasUML An Lección6 Actividades PrácticasFernandoFortanellAún no hay calificaciones
- Laboratorio PythonDocumento4 páginasLaboratorio PythonBryan Córdova ÑahuiAún no hay calificaciones
- Lab - Laravel5 Completo - MasterDocumento77 páginasLab - Laravel5 Completo - MasterRenato BautistaAún no hay calificaciones
- Desarrollo de Software EducativoDocumento180 páginasDesarrollo de Software EducativoDaniel Tellez LeonAún no hay calificaciones
- Estandar Programacion Sistemas IonDocumento14 páginasEstandar Programacion Sistemas Ionluis_1306Aún no hay calificaciones
- Inteligencia de NegociosDocumento7 páginasInteligencia de NegociosI take life siseAún no hay calificaciones
- Silabo - Gerencia de Proyectos TiDocumento14 páginasSilabo - Gerencia de Proyectos TiJCesar Cusi AlvaradoAún no hay calificaciones
- Formato IEEE 830-1998Documento14 páginasFormato IEEE 830-1998SaraarmzAún no hay calificaciones
- DSIA Propuesta Diseño SistemasDocumento36 páginasDSIA Propuesta Diseño Sistemassrd2607Aún no hay calificaciones
- Plan de Administración de La Configuración Del SoftwareDocumento8 páginasPlan de Administración de La Configuración Del SoftwareCesar GarciaAún no hay calificaciones
- Rúbrica DESARROLLO FRONTEND I IL1Documento2 páginasRúbrica DESARROLLO FRONTEND I IL1Jaime Añazco ManchegoAún no hay calificaciones
- Trabajo Del LibroDocumento16 páginasTrabajo Del LibromarielaAún no hay calificaciones
- Patrón Screenplay en Gradle con manejo de dependenciasDocumento11 páginasPatrón Screenplay en Gradle con manejo de dependenciasMatías PeñaAún no hay calificaciones
- Saber U2 UXDocumento9 páginasSaber U2 UXFabian IbarraAún no hay calificaciones
- Formato Ieee830Documento11 páginasFormato Ieee830Steven TorresAún no hay calificaciones
- Silabo de PythonDocumento8 páginasSilabo de PythonJackeline BalvinAún no hay calificaciones
- Laboratorio 2Documento5 páginasLaboratorio 2Las AMERICASAún no hay calificaciones
- MockupsDocumento12 páginasMockupsPatricio Acum SalinasAún no hay calificaciones
- Modelo de Diseño en La Metodologia RupDocumento32 páginasModelo de Diseño en La Metodologia RupejjsmAún no hay calificaciones
- Ingenieria InversaDocumento11 páginasIngenieria InversaCristian Damian PinzonAún no hay calificaciones
- Plantilla de Modelo IEEE STD 830-1998.Documento10 páginasPlantilla de Modelo IEEE STD 830-1998.Santiago FedericoAún no hay calificaciones
- Laboratorio 03 Configuracion SQLDocumento51 páginasLaboratorio 03 Configuracion SQLCar BeatAún no hay calificaciones
- 01 Administración de La Configuración Del SoftwareDocumento34 páginas01 Administración de La Configuración Del SoftwareSuriel VivasAún no hay calificaciones
- Análisis y Diseño de Sistemas - Sesion 02 - Modelado de Procesos de Negocio IIDocumento25 páginasAnálisis y Diseño de Sistemas - Sesion 02 - Modelado de Procesos de Negocio IIGianfranco Eduardo Bravo LudeñaAún no hay calificaciones
- CibertecDocumento17 páginasCibertecJunior ToledoAún no hay calificaciones
- 1.5.1. Definición e Historia de Las Herramientas CASEDocumento52 páginas1.5.1. Definición e Historia de Las Herramientas CASEHelio Sampe ReyesAún no hay calificaciones
- Evaluación Práctica 01 - BaseDatosDocumento2 páginasEvaluación Práctica 01 - BaseDatosRaúl Salazar JaureguiAún no hay calificaciones
- Desarrollo de Aplicaciones Con Programacion ExtremaDocumento25 páginasDesarrollo de Aplicaciones Con Programacion ExtremaFrank Luis Gallardo Cabrera100% (2)
- Algoritmos distribuidos y programación concurrenteDocumento12 páginasAlgoritmos distribuidos y programación concurrenteYhonatan Robles VegaAún no hay calificaciones
- Gestión TI en Ingeniería InformáticaDocumento15 páginasGestión TI en Ingeniería InformáticaRubén RomeroAún no hay calificaciones
- Rational FinalDocumento46 páginasRational FinalrogerscitoAún no hay calificaciones
- Proyecto NoSQL Base de Datos III 2020 IDocumento7 páginasProyecto NoSQL Base de Datos III 2020 ILeonardo MiguelAún no hay calificaciones
- ClaseAYDS - 06 v2Documento73 páginasClaseAYDS - 06 v2Andres FranciscoAún no hay calificaciones
- Revisiones, inspecciones y métodos para mejorar la calidad del softwareDocumento11 páginasRevisiones, inspecciones y métodos para mejorar la calidad del softwareCarlos Alfredo Sanchez CruzAún no hay calificaciones
- Niveles y Tipos de PruebasDocumento73 páginasNiveles y Tipos de PruebasOscar RequeneAún no hay calificaciones
- Análisis y Diseño de Sistemas - Sesion 09 - Validacion de RequisitosDocumento21 páginasAnálisis y Diseño de Sistemas - Sesion 09 - Validacion de RequisitosGianfranco Eduardo Bravo LudeñaAún no hay calificaciones
- Programación segura con GitDocumento31 páginasProgramación segura con GitMichell JáureguiAún no hay calificaciones
- Manual Herramientas de Desarrollo de Software - 2019 PDFDocumento147 páginasManual Herramientas de Desarrollo de Software - 2019 PDFaxelAún no hay calificaciones
- Frameworks JSF Semana7 PDFDocumento43 páginasFrameworks JSF Semana7 PDFDavid RiveroyAún no hay calificaciones
- Ciclo de Vida 12227Documento42 páginasCiclo de Vida 12227Harold Kevin EvilHoulseAún no hay calificaciones
- Ingenieria Requerimientos v2Documento225 páginasIngenieria Requerimientos v2Oscar HunterAún no hay calificaciones
- Practica de Laboratorio N 05 Redes PDFDocumento12 páginasPractica de Laboratorio N 05 Redes PDFElvis Tineo MoralesAún no hay calificaciones
- Caso de Estudio - Sistema BibliotecarioDocumento36 páginasCaso de Estudio - Sistema BibliotecarioSocorro AranaAún no hay calificaciones
- Documento VisionDocumento10 páginasDocumento VisionJorge Cabrera AbantoAún no hay calificaciones
- Herramientas Case 1Documento8 páginasHerramientas Case 1Carlos EstradaAún no hay calificaciones
- Conceptos Básicos y Ejemplos de Sistemas DistribuidosDocumento11 páginasConceptos Básicos y Ejemplos de Sistemas DistribuidosFabricio OrtizAún no hay calificaciones
- Programacion Orientada A ObjetosDocumento44 páginasProgramacion Orientada A ObjetosDavid SalazarAún no hay calificaciones
- Silabo de Control de Calidad de SoftwareDocumento4 páginasSilabo de Control de Calidad de SoftwareRolando Villanueva ParionaAún no hay calificaciones
- Diagramas UmlDocumento19 páginasDiagramas UmlArnold Julián HerreraAún no hay calificaciones
- Anexo 3. Historias de UsuarioDocumento1 páginaAnexo 3. Historias de UsuarioJuan jose Nieto GillAún no hay calificaciones
- Fechas en JavaDocumento5 páginasFechas en JavaJuan DanielAún no hay calificaciones
- CALIDAD DEL SOFTWARE ISO 9126Documento47 páginasCALIDAD DEL SOFTWARE ISO 9126César Lainez Lozada TorattoAún no hay calificaciones
- BDD-Calidad-Pruebas-SoftwareDocumento10 páginasBDD-Calidad-Pruebas-SoftwareManuel MurguíaAún no hay calificaciones
- 7 Prog Analitico SeguridadDocumento12 páginas7 Prog Analitico SeguridadAlexis ChicaizaAún no hay calificaciones
- Enunciado Práctica Java EE Iteración 1 - Aplicación Web Con JSFDocumento9 páginasEnunciado Práctica Java EE Iteración 1 - Aplicación Web Con JSFBen AvrahamAún no hay calificaciones
- Graficos JfreeChartDocumento4 páginasGraficos JfreeChartOskar Cadena0% (1)
- Diis U2 A2 EdvrDocumento9 páginasDiis U2 A2 EdvrIsra SAún no hay calificaciones
- Archivo 1Documento5 páginasArchivo 1Nestor MoroccoAún no hay calificaciones
- Anexo 31Documento1 páginaAnexo 31Herlin RoncalAún no hay calificaciones
- Muros DelgadosDocumento57 páginasMuros DelgadosJesús Flores HernándezAún no hay calificaciones
- Cruz M PDFDocumento440 páginasCruz M PDFNestor MoroccoAún no hay calificaciones
- Tutorial Sencillo de AngularJSDocumento17 páginasTutorial Sencillo de AngularJSNestor MoroccoAún no hay calificaciones
- PFCpatrones JavaDocumento728 páginasPFCpatrones JavaLimberg CrespoAún no hay calificaciones
- PruebaDocumento5841 páginasPruebaNestor MoroccoAún no hay calificaciones
- PruebaDocumento5673 páginasPruebaNestor MoroccoAún no hay calificaciones
- Patrones en Java Parte 1Documento31 páginasPatrones en Java Parte 1Nestor MoroccoAún no hay calificaciones
- Patrones Sesion01 ApuntesDocumento18 páginasPatrones Sesion01 Apuntes0dito0Aún no hay calificaciones
- Informe Final - Arquitectura Empresaria para TD - TogafDocumento271 páginasInforme Final - Arquitectura Empresaria para TD - TogafNestor MoroccoAún no hay calificaciones
- Ejercicio Practico Diagrama de Casos UsoDocumento16 páginasEjercicio Practico Diagrama de Casos UsoHarden Alirio50% (6)
- Como Generar Codigo QRDocumento8 páginasComo Generar Codigo QRTeoloma HneAún no hay calificaciones
- Líder Técnico + Scrum Master - Comercial 2019Documento2 páginasLíder Técnico + Scrum Master - Comercial 2019Rodolfo Einstein Ramos RodriguezAún no hay calificaciones
- Respuesta Actividad 2Documento4 páginasRespuesta Actividad 2Yeimy Lorena GomezAún no hay calificaciones
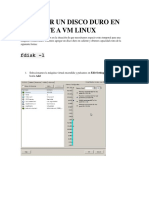
- Agregar Un Disco Duro en Caliente A VM LinuxDocumento6 páginasAgregar Un Disco Duro en Caliente A VM LinuxPatricio CardenasAún no hay calificaciones
- Unidad Educativa Marista PIODocumento3 páginasUnidad Educativa Marista PIORonny BuitronAún no hay calificaciones
- Teoría y Ejemplos Estructura Condicional SimpleDocumento4 páginasTeoría y Ejemplos Estructura Condicional Simpleppluis2010Aún no hay calificaciones
- Proceso UnificadoDocumento9 páginasProceso UnificadoClemente Rodriguez ThalassinosAún no hay calificaciones
- GENEXUSDocumento3 páginasGENEXUSBrad FrenchAún no hay calificaciones
- Monografia de Sistema OperativosDocumento29 páginasMonografia de Sistema OperativosErickMacedoPanaifoAún no hay calificaciones
- Programación Dinamica ProbabilisticaDocumento2 páginasProgramación Dinamica ProbabilisticaJosé MartinezAún no hay calificaciones
- Informe Final Programacion 2Documento17 páginasInforme Final Programacion 2hover morales plasenciaAún no hay calificaciones
- Identificador GruposDocumento1 páginaIdentificador GruposAndy PerrynAún no hay calificaciones
- Manual Uml Con EjerciciosDocumento96 páginasManual Uml Con EjerciciosMacarena Barragan White100% (1)
- Servidor de AuditoriaDocumento11 páginasServidor de AuditoriaMartin Montes De Oca FernandezAún no hay calificaciones
- Protocolo LoRaWANDocumento21 páginasProtocolo LoRaWANDavid Orjuela100% (2)
- Gestion de Almacenamiento PersistenteDocumento19 páginasGestion de Almacenamiento PersistenteBlas Antonio García F0% (1)
- Forcontu Plan Formativo Curso Avanzado Drupal8 FullStack ConilDocumento10 páginasForcontu Plan Formativo Curso Avanzado Drupal8 FullStack ConilDavid NoreñaAún no hay calificaciones
- Características de La MAC AddressDocumento2 páginasCaracterísticas de La MAC AddressBufo Viridis100% (1)
- Cuestionario Examen ADOODocumento10 páginasCuestionario Examen ADOOAndrés Muñoz OrdenesAún no hay calificaciones
- Características de Los Documentos DigitalesDocumento2 páginasCaracterísticas de Los Documentos Digitalesroly0% (1)
- Comparativa de Procesadores ActualesDocumento6 páginasComparativa de Procesadores Actualesbarinesa70Aún no hay calificaciones
- Práctica 1 Control de IluminaciónDocumento7 páginasPráctica 1 Control de IluminaciónMaida Rengifo ChernezAún no hay calificaciones
- Claves Del Registro y Archivos Batch para Mejorar Windows 10Documento6 páginasClaves Del Registro y Archivos Batch para Mejorar Windows 10Demis AndradeAún no hay calificaciones
- Programación Visual BasicDocumento30 páginasProgramación Visual BasicJohn Edison Castro Cubillos0% (1)
- 001 - Diferencia Entre Compilador e InterpreteDocumento2 páginas001 - Diferencia Entre Compilador e InterpreteJose CardenasAún no hay calificaciones
- Catalogo SENIAT NombNormDocumento7 páginasCatalogo SENIAT NombNormMarialex PereiraAún no hay calificaciones
- Aplicaciones en El Plano de Viviendas: SketchupDocumento110 páginasAplicaciones en El Plano de Viviendas: Sketchupgianella alfaro leonAún no hay calificaciones
- Cap 3.a BIG DATA IntroduccionDocumento19 páginasCap 3.a BIG DATA IntroduccionJorge Bryan Soliz VidalAún no hay calificaciones
- Documento Workflow Diagrama Por CallesDocumento50 páginasDocumento Workflow Diagrama Por CallesRichard LopezAún no hay calificaciones