También podría gustarte
- The Yellow House: A Memoir (2019 National Book Award Winner)De EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Calificación: 4 de 5 estrellas4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceCalificación: 4 de 5 estrellas4/5 (895)
- Avor TaroDocumento106 páginasAvor TaroSiap SiapAún no hay calificaciones
- The Cat Is Out of The Bag: Orientalism Anti-Blackness and White Supremacy in Dr. Seuss's Children's BooksDocumento51 páginasThe Cat Is Out of The Bag: Orientalism Anti-Blackness and White Supremacy in Dr. Seuss's Children's Bookstimsmith1081574Aún no hay calificaciones
- Elementos de Gramática Del MiskitoDocumento380 páginasElementos de Gramática Del MiskitolevisjaviAún no hay calificaciones
- Estimating Vocabulary SizeDocumento27 páginasEstimating Vocabulary SizeATX TOXICAún no hay calificaciones
- List Words SfiDocumento167 páginasList Words SfikarabaAún no hay calificaciones
- Understanding Technical English-1Documento67 páginasUnderstanding Technical English-1Ega Marga PutraAún no hay calificaciones
- Viz Shotcut Guide 1.3Documento34 páginasViz Shotcut Guide 1.3levisjaviAún no hay calificaciones
- Seamless Object-Oriented Software Architecture Analysis and Design of Reliable SystemsDocumento458 páginasSeamless Object-Oriented Software Architecture Analysis and Design of Reliable Systemsapi-3734765100% (5)
- Katyusha For UkeleleDocumento1 páginaKatyusha For UkelelelevisjaviAún no hay calificaciones
- (Ancient Maps) Maps of The Late Medieval Period 1300 - 1500Documento105 páginas(Ancient Maps) Maps of The Late Medieval Period 1300 - 1500api-3707729100% (2)
- PyCon2012 IPythonTutorial NotebookDocumento17 páginasPyCon2012 IPythonTutorial NotebooklevisjaviAún no hay calificaciones
- La Kabylie Et Les Coutumes Kabyles 1/3, Par Hanoteau Et Letourneux, 1893Documento607 páginasLa Kabylie Et Les Coutumes Kabyles 1/3, Par Hanoteau Et Letourneux, 1893Tamkaṛḍit - la Bibliothèque amazighe (berbère) internationale100% (3)
- Rob Costlow - Woods of ChaosDocumento5 páginasRob Costlow - Woods of ChaoslevisjaviAún no hay calificaciones
- A Bible Study of John (Gospel Tract) - Miskito LanguageDocumento25 páginasA Bible Study of John (Gospel Tract) - Miskito LanguageJesus LivesAún no hay calificaciones
- Walter Benjamin Aura of PhotographyDocumento23 páginasWalter Benjamin Aura of Photographykriky100% (2)
- ArchetypesDocumento17 páginasArchetypesrovanl100% (1)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeCalificación: 4 de 5 estrellas4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe EverandThe Little Book of Hygge: Danish Secrets to Happy LivingCalificación: 3.5 de 5 estrellas3.5/5 (399)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaCalificación: 4.5 de 5 estrellas4.5/5 (266)
- Shoe Dog: A Memoir by the Creator of NikeDe EverandShoe Dog: A Memoir by the Creator of NikeCalificación: 4.5 de 5 estrellas4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureCalificación: 4.5 de 5 estrellas4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe EverandNever Split the Difference: Negotiating As If Your Life Depended On ItCalificación: 4.5 de 5 estrellas4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe EverandGrit: The Power of Passion and PerseveranceCalificación: 4 de 5 estrellas4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryCalificación: 3.5 de 5 estrellas3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerDe EverandThe Emperor of All Maladies: A Biography of CancerCalificación: 4.5 de 5 estrellas4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyCalificación: 3.5 de 5 estrellas3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealDe EverandOn Fire: The (Burning) Case for a Green New DealCalificación: 4 de 5 estrellas4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersCalificación: 4.5 de 5 estrellas4.5/5 (344)
- Rise of ISIS: A Threat We Can't IgnoreDe EverandRise of ISIS: A Threat We Can't IgnoreCalificación: 3.5 de 5 estrellas3.5/5 (137)
- Team of Rivals: The Political Genius of Abraham LincolnDe EverandTeam of Rivals: The Political Genius of Abraham LincolnCalificación: 4.5 de 5 estrellas4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDe EverandThe Unwinding: An Inner History of the New AmericaCalificación: 4 de 5 estrellas4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreCalificación: 4 de 5 estrellas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Calificación: 4.5 de 5 estrellas4.5/5 (121)
- The Perks of Being a WallflowerDe EverandThe Perks of Being a WallflowerCalificación: 4.5 de 5 estrellas4.5/5 (2102)
- Her Body and Other Parties: StoriesDe EverandHer Body and Other Parties: StoriesCalificación: 4 de 5 estrellas4/5 (821)
- Sex Differences in Positive Well-Being: A Consideration of Emotional Style and Marital StatusDocumento16 páginasSex Differences in Positive Well-Being: A Consideration of Emotional Style and Marital StatusWidyaUtamiAún no hay calificaciones
- A Historical Account of The Stratigraphy of Qatar, Middle-East (1816 To 2015)Documento1220 páginasA Historical Account of The Stratigraphy of Qatar, Middle-East (1816 To 2015)Jacques LeBlanc100% (2)
- The Aiche Sustainability Index: The Factors in DetailDocumento4 páginasThe Aiche Sustainability Index: The Factors in DetailAllalannAún no hay calificaciones
- fs3 2Documento10 páginasfs3 2api-312231268Aún no hay calificaciones
- Effectivness of Promotional Schemes in Reliance MartDocumento22 páginasEffectivness of Promotional Schemes in Reliance MartSavan BhattAún no hay calificaciones
- Master Thesis in LiteratureDocumento5 páginasMaster Thesis in Literaturegja8e2sv100% (2)
- Lecture 3 - Decision Making in ManagementDocumento15 páginasLecture 3 - Decision Making in ManagementDenys VdovychenkoAún no hay calificaciones
- Effective Business Communication Case StudyDocumento8 páginasEffective Business Communication Case StudyamritaAún no hay calificaciones
- Igcse Art Coursework ChecklistDocumento7 páginasIgcse Art Coursework Checklistdgmtutlfg100% (1)
- The Distinctive Role of Gerontological Social WorkDocumento4 páginasThe Distinctive Role of Gerontological Social WorktejaswinadubettaAún no hay calificaciones
- Proposal Body Shaming The Age of Social Media, New DraftDocumento13 páginasProposal Body Shaming The Age of Social Media, New DraftMunashe GoromonziAún no hay calificaciones
- Learning WalksDocumento6 páginasLearning WalksheenamodiAún no hay calificaciones
- Sports Tourism in IndiaDocumento7 páginasSports Tourism in Indiaabdul khanAún no hay calificaciones
- Self AssessmentDocumento4 páginasSelf Assessmentapi-579839747Aún no hay calificaciones
- Motor Speech Skills in Down SyndromeDocumento11 páginasMotor Speech Skills in Down SyndromePaulaAún no hay calificaciones
- Causal Inference The MixtapeDocumento657 páginasCausal Inference The Mixtape何旭波Aún no hay calificaciones
- Marking Scheme AgriDocumento3 páginasMarking Scheme AgriDa bert100% (1)
- Chapter 3 - Mother TongueDocumento7 páginasChapter 3 - Mother TongueCatherine BonAún no hay calificaciones
- Etextbook 978 0205985807 CognitionDocumento61 páginasEtextbook 978 0205985807 Cognitionbenjamin.vega423100% (45)
- Lesson Plan in PhysicsDocumento2 páginasLesson Plan in PhysicsGen SinangoteAún no hay calificaciones
- Unit 4: Ready For Testing in Live Organisms: Exercise 10Documento5 páginasUnit 4: Ready For Testing in Live Organisms: Exercise 10Thanh HoàAún no hay calificaciones
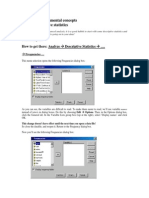
- Chapter 1 Fundamental Concepts SPSS - Descriptive StatisticsDocumento4 páginasChapter 1 Fundamental Concepts SPSS - Descriptive StatisticsAvinash AmbatiAún no hay calificaciones
- Revised Irr of Mining Act of 1995Documento6 páginasRevised Irr of Mining Act of 1995agfajardoAún no hay calificaciones
- This Study Resource WasDocumento8 páginasThis Study Resource WasSamAún no hay calificaciones
- PNNL 24843Documento196 páginasPNNL 24843FabSan21Aún no hay calificaciones
- Customer Buying BehaviorDocumento17 páginasCustomer Buying BehaviorJohn J. Kundi100% (28)
- 2012 - Job Profile - Field Service Engineer FSEDocumento2 páginas2012 - Job Profile - Field Service Engineer FSEskybmeAún no hay calificaciones
- Inquiries Midterm ExamDocumento2 páginasInquiries Midterm ExamMarkmarilyn100% (1)
- India India Lab Hyderabad: Exhibitor List of Mumbai (2018) Visitor Registration Why Mumbai Why HyderabadDocumento3 páginasIndia India Lab Hyderabad: Exhibitor List of Mumbai (2018) Visitor Registration Why Mumbai Why HyderabadaaAún no hay calificaciones
- Artificial Intelligence For Clinical OncologyDocumento23 páginasArtificial Intelligence For Clinical OncologyJuan Fernando Méndez RamírezAún no hay calificaciones