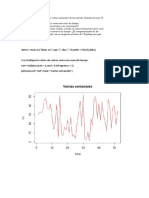
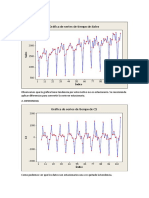
También podría gustarte
- Instrucciones de Instalación MatlabDocumento6 páginasInstrucciones de Instalación MatlabAndres VictorAún no hay calificaciones
- Resolucion Ejercicios I Taller Diseno deDocumento28 páginasResolucion Ejercicios I Taller Diseno deAndres VictorAún no hay calificaciones
- Ejer Serie WsDocumento2 páginasEjer Serie WsAndres VictorAún no hay calificaciones
- Ejercicio 17 HankeDocumento1 páginaEjercicio 17 HankeAndres VictorAún no hay calificaciones
- Prueba ArimaDocumento9 páginasPrueba ArimaAndres VictorAún no hay calificaciones
- SESION 4 Ejer1Documento3 páginasSESION 4 Ejer1Andres VictorAún no hay calificaciones
- Ejercicio 17 HankeDocumento1 páginaEjercicio 17 HankeAndres Victor0% (1)
- Prueba ArimaDocumento9 páginasPrueba ArimaAndres VictorAún no hay calificaciones
- Sir Ronald Aylmer FisherDocumento2 páginasSir Ronald Aylmer FisherAndres Victor100% (1)
- AnovacastDocumento6 páginasAnovacastAndres VictorAún no hay calificaciones
- Univeridad Tecnológica EquinoccialDocumento3 páginasUniveridad Tecnológica EquinoccialAndres VictorAún no hay calificaciones
- Ejercicio 5Documento1 páginaEjercicio 5Andres VictorAún no hay calificaciones
- Investigacion AntooooooDocumento1 páginaInvestigacion AntooooooAndres VictorAún no hay calificaciones
- Sistema General de EstudioDocumento3 páginasSistema General de EstudioAndres VictorAún no hay calificaciones
- Montubios ExposicionDocumento2 páginasMontubios ExposicionAndres Victor100% (1)
- Resumen Del Libro SthephenDocumento2 páginasResumen Del Libro SthephenAndres VictorAún no hay calificaciones
- Ide en SQLDocumento7 páginasIde en SQLAndres VictorAún no hay calificaciones
- La Atencion PreguntasDocumento3 páginasLa Atencion PreguntasAndres VictorAún no hay calificaciones
- Algebra y Calculo de PredicadosDocumento2 páginasAlgebra y Calculo de PredicadosAndres VictorAún no hay calificaciones
- Resumen Del Libro SthephenDocumento2 páginasResumen Del Libro SthephenAndres VictorAún no hay calificaciones
- Isaac NewtonDocumento1 páginaIsaac NewtonAndres VictorAún no hay calificaciones
- Isaac NewtonDocumento1 páginaIsaac NewtonAndres VictorAún no hay calificaciones
- Historia de Las Orquídeas 3Documento5 páginasHistoria de Las Orquídeas 3Andres VictorAún no hay calificaciones
- Punteros y ArraysDocumento4 páginasPunteros y ArraysAndres VictorAún no hay calificaciones
- Punteros y ArraysDocumento4 páginasPunteros y ArraysAndres VictorAún no hay calificaciones
- Ejercicos ResueltosDocumento8 páginasEjercicos ResueltosAndres VictorAún no hay calificaciones
- Isaac NewtonDocumento1 páginaIsaac NewtonAndres VictorAún no hay calificaciones