También podría gustarte
- VkFFT-A Performant Cross-Platform and Open-Source GPU FFT LibraryDocumento20 páginasVkFFT-A Performant Cross-Platform and Open-Source GPU FFT Librarymifami7390Aún no hay calificaciones
- An FPGA Implementation of The LMS Adaptive Filter For Audio ProcessingDocumento8 páginasAn FPGA Implementation of The LMS Adaptive Filter For Audio ProcessingJabran SafdarAún no hay calificaciones
- Sora: High Performance Software Radio Using General Purpose Multi-Core ProcessorsDocumento16 páginasSora: High Performance Software Radio Using General Purpose Multi-Core Processorsnandan_pappuAún no hay calificaciones
- An FPGA Implementation of OFDM Transceiver For LTE ApplicationsDocumento11 páginasAn FPGA Implementation of OFDM Transceiver For LTE ApplicationsKeerthi PriyaAún no hay calificaciones
- No Guera 2011Documento11 páginasNo Guera 2011DomRuanAún no hay calificaciones
- Performance Study of Lte Experimental Testbed Using OpenairinterfaceDocumento6 páginasPerformance Study of Lte Experimental Testbed Using OpenairinterfaceDương Trần ĐạiAún no hay calificaciones
- NTT Architecture For A Linux-Ready RISC-V Fully-Homomorphic Encryption AcceleratorDocumento14 páginasNTT Architecture For A Linux-Ready RISC-V Fully-Homomorphic Encryption AcceleratorsamarAún no hay calificaciones
- A Design of SDR-based Pseudo-Analog WirelessDocumento9 páginasA Design of SDR-based Pseudo-Analog Wirelessmianmuhammadawais321Aún no hay calificaciones
- Admin,+Journal+Manager,+42 AJPCR 19632Documento7 páginasAdmin,+Journal+Manager,+42 AJPCR 19632shobana confyyAún no hay calificaciones
- Implementation of The OFDM Physical Layer Using FpgaDocumento7 páginasImplementation of The OFDM Physical Layer Using FpgaManel JoujouAún no hay calificaciones
- Implementation of Channel Demodulator For Dab System: Huz Yunlin of & Yunlin &Documento4 páginasImplementation of Channel Demodulator For Dab System: Huz Yunlin of & Yunlin &ashu_4novAún no hay calificaciones
- Advanced MIMO Waveform Deployment Using GNU RadioDocumento9 páginasAdvanced MIMO Waveform Deployment Using GNU RadiojohnmechanjiAún no hay calificaciones
- ECE 465: Introduction to CPLDs and FPGAsDocumento21 páginasECE 465: Introduction to CPLDs and FPGAsrakeshAún no hay calificaciones
- Digital System Design - 0Documento15 páginasDigital System Design - 0Đoàn Vũ Phú VinhAún no hay calificaciones
- C 2030 Lundgren Gedae Gedae For CertificationDocumento24 páginasC 2030 Lundgren Gedae Gedae For Certificationsandia_docsAún no hay calificaciones
- 15 - 4 - 21trans. IEEE 2012 - Software-Defined Sphere Decoding For FPGA-Based MIMO DetectionDocumento10 páginas15 - 4 - 21trans. IEEE 2012 - Software-Defined Sphere Decoding For FPGA-Based MIMO DetectionTiến Anh VũAún no hay calificaciones
- P 31Documento6 páginasP 31Avinash AvuthuAún no hay calificaciones
- FPGA: Field Programmable Gate ArrayDocumento5 páginasFPGA: Field Programmable Gate ArrayGolnaz KorkianAún no hay calificaciones
- Xeon Phi CompleteDocumento88 páginasXeon Phi CompleteNecmettin yıldızAún no hay calificaciones
- FPGA Implementations of Feed Forward Neural Network by Using Floating Point Hardware AcceleratorsDocumento10 páginasFPGA Implementations of Feed Forward Neural Network by Using Floating Point Hardware AcceleratorsCarlos Torres CasasAún no hay calificaciones
- Static Scheduling of Synchronous Data Flow Programs for High-Performance Digital Signal ProcessingDocumento12 páginasStatic Scheduling of Synchronous Data Flow Programs for High-Performance Digital Signal ProcessingTadele Basazenew AyeleAún no hay calificaciones
- Roburst Implementation of OFDM System Using VHDL: AbstractDocumento7 páginasRoburst Implementation of OFDM System Using VHDL: AbstractFilipe RodriguesAún no hay calificaciones
- Smart Card:: Smart Cards-What Are They?Documento12 páginasSmart Card:: Smart Cards-What Are They?infernobibekAún no hay calificaciones
- VlsipythonDocumento4 páginasVlsipythonsiri.pogulaAún no hay calificaciones
- Thesis Fpga ImplementationDocumento6 páginasThesis Fpga Implementationjessicabriggsomaha100% (2)
- PID3410305 Final 1Documento7 páginasPID3410305 Final 1Geetha SreeAún no hay calificaciones
- Building Software-Defined Radios in MATLAB Simulink - A Step Towards Cognitive RadiosDocumento6 páginasBuilding Software-Defined Radios in MATLAB Simulink - A Step Towards Cognitive Radiospranavam_1Aún no hay calificaciones
- Implementation of DSP Algorithms On Reconfigurable Embedded PlatformDocumento7 páginasImplementation of DSP Algorithms On Reconfigurable Embedded PlatformGV Avinash KumarAún no hay calificaciones
- Aece 2014 2 11Documento6 páginasAece 2014 2 11holaAún no hay calificaciones
- Why Con Gurable Computing? The Computational Density Advantage of Con Gurable ArchitecturesDocumento17 páginasWhy Con Gurable Computing? The Computational Density Advantage of Con Gurable ArchitecturesHari KrishnaAún no hay calificaciones
- Application Feature: Dsp/Fpga: Spectrum Analysis - DSP On FpgasDocumento5 páginasApplication Feature: Dsp/Fpga: Spectrum Analysis - DSP On FpgasSilveiraJuniorAún no hay calificaciones
- Ece 465 Introduction To Cplds and Fpgas: Shantanu Dutt Ece Dept. University of Illinois at ChicagoDocumento11 páginasEce 465 Introduction To Cplds and Fpgas: Shantanu Dutt Ece Dept. University of Illinois at ChicagoMamoon BarbhuyanAún no hay calificaciones
- Fusion Engineering and Design: A. Rigoni, G. Manduchi, A. Luchetta, C. Taliercio, T. SchröderDocumento4 páginasFusion Engineering and Design: A. Rigoni, G. Manduchi, A. Luchetta, C. Taliercio, T. Schröderdavid Villa SotomayorAún no hay calificaciones
- International Journal Comp Tel - 1Documento5 páginasInternational Journal Comp Tel - 1shafa18Aún no hay calificaciones
- Jimaging 05 00016Documento22 páginasJimaging 05 00016vn7196Aún no hay calificaciones
- Algorithm For Scalable Fourier TransformsDocumento5 páginasAlgorithm For Scalable Fourier TransformsGary Ryan DonovanAún no hay calificaciones
- Synchronous Data Flow AlgorithmsDocumento12 páginasSynchronous Data Flow Algorithmscpayne10409Aún no hay calificaciones
- Compiling Occam Into Field-Programmable Gate Arrays: Ian Page and Wayne LukDocumento13 páginasCompiling Occam Into Field-Programmable Gate Arrays: Ian Page and Wayne LukTamiltamil TamilAún no hay calificaciones
- (Cm4036) الملاحظات موجودة داخل الورقةDocumento6 páginas(Cm4036) الملاحظات موجودة داخل الورقةOsama AborodesAún no hay calificaciones
- High-Performance DSP Capability Within An Optimized Low-Cost Fpga ArchitectureDocumento12 páginasHigh-Performance DSP Capability Within An Optimized Low-Cost Fpga ArchitectureYogesh YadavAún no hay calificaciones
- DSP Framework For OSMOCOMBBDocumento6 páginasDSP Framework For OSMOCOMBBBertin PolombweAún no hay calificaciones
- Introduction To Cplds and Fpgas: by N.ChandrasekharanDocumento21 páginasIntroduction To Cplds and Fpgas: by N.ChandrasekharanWilliam Arief WengAún no hay calificaciones
- Programmable Logic Devices (PLD)Documento40 páginasProgrammable Logic Devices (PLD)ALEX SAGARAún no hay calificaciones
- Architecture of FPGAs and CPLDS: A TutorialDocumento41 páginasArchitecture of FPGAs and CPLDS: A Tutorialgongster100% (5)
- Publi 4371Documento3 páginasPubli 4371Agustin Vizcarra LizarbeAún no hay calificaciones
- Parallel Prefix AdderDocumento4 páginasParallel Prefix AdderArjun RamAún no hay calificaciones
- FPGA Genreal PaperDocumento7 páginasFPGA Genreal PaperParth SomkuwarAún no hay calificaciones
- Evolution of The Graphics Process Units: Dr. Zhijie Xu Z.xu@hud - Ac.ukDocumento24 páginasEvolution of The Graphics Process Units: Dr. Zhijie Xu Z.xu@hud - Ac.ukNithin JohnAún no hay calificaciones
- PLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.De EverandPLC: Programmable Logic Controller – Arktika.: EXPERIMENTAL PRODUCT BASED ON CPLD.Aún no hay calificaciones
- CISCO PACKET TRACER LABS: Best practice of configuring or troubleshooting NetworkDe EverandCISCO PACKET TRACER LABS: Best practice of configuring or troubleshooting NetworkAún no hay calificaciones
- Embedded Software Design and Programming of Multiprocessor System-on-Chip: Simulink and System C Case StudiesDe EverandEmbedded Software Design and Programming of Multiprocessor System-on-Chip: Simulink and System C Case StudiesAún no hay calificaciones
- Embedded Systems Design with Platform FPGAs: Principles and PracticesDe EverandEmbedded Systems Design with Platform FPGAs: Principles and PracticesCalificación: 5 de 5 estrellas5/5 (1)
- Digital Signal Processing System Design: LabVIEW-Based Hybrid ProgrammingDe EverandDigital Signal Processing System Design: LabVIEW-Based Hybrid ProgrammingCalificación: 5 de 5 estrellas5/5 (1)
- Foundation Course for Advanced Computer StudiesDe EverandFoundation Course for Advanced Computer StudiesAún no hay calificaciones
- Dreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9De EverandDreamcast Architecture: Architecture of Consoles: A Practical Analysis, #9Aún no hay calificaciones
- PlayStation Architecture: Architecture of Consoles: A Practical Analysis, #6De EverandPlayStation Architecture: Architecture of Consoles: A Practical Analysis, #6Aún no hay calificaciones
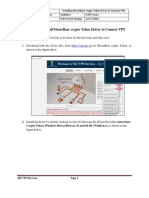
- Procedure To Install Moserbaer Crypto Token Driver To Connect VPNDocumento8 páginasProcedure To Install Moserbaer Crypto Token Driver To Connect VPNManish KunduAún no hay calificaciones
- Evt - MsiDocumento55 páginasEvt - MsiCarlos GomesAún no hay calificaciones
- Sequential Shift Add-MethodDocumento3 páginasSequential Shift Add-Methodanjanbs50% (2)
- Generations of Computer Systems and Operating SystemsDocumento7 páginasGenerations of Computer Systems and Operating SystemsVIPER CHIKUAún no hay calificaciones
- CP R75.20 Installation and Upgrade GuideDocumento144 páginasCP R75.20 Installation and Upgrade Guide搵食Aún no hay calificaciones
- X8sax-C7x58 QRG (MNL-1063-QRG) 1.0Documento1 páginaX8sax-C7x58 QRG (MNL-1063-QRG) 1.0Ben TotanesAún no hay calificaciones
- 8096or8097 Microcontroller PDFDocumento38 páginas8096or8097 Microcontroller PDFStoriesofsuperheroes50% (2)
- Alesis HD24 Meter Display LogicDocumento2 páginasAlesis HD24 Meter Display Logicguitar12345Aún no hay calificaciones
- COMPUTER NETWORK QUESTIONSDocumento6 páginasCOMPUTER NETWORK QUESTIONSHarivansh chauhanAún no hay calificaciones
- Obs LogDocumento9 páginasObs LogSusan WiseAún no hay calificaciones
- 01 - Syllabus and Intro PDFDocumento13 páginas01 - Syllabus and Intro PDFAnil Kumar GorantalaAún no hay calificaciones
- SET UP Computer ServerDocumento3 páginasSET UP Computer ServerRicHArdAún no hay calificaciones
- Getting Started With Autosar - Rev June 25 2019 PDFDocumento319 páginasGetting Started With Autosar - Rev June 25 2019 PDFkakathiAún no hay calificaciones
- Yahoo Chat SpyDocumento9 páginasYahoo Chat SpyGiovanni CiallellaAún no hay calificaciones
- Chip Resetera GS88 User GuideDocumento9 páginasChip Resetera GS88 User Guidec64thorgalAún no hay calificaciones
- Screencast 0Documento3 páginasScreencast 0Nicolás Durán GarcésAún no hay calificaciones
- SVC and V7000 Command Line Interface Users Guide PDFDocumento648 páginasSVC and V7000 Command Line Interface Users Guide PDFPanzo Vézua GarciaAún no hay calificaciones
- Inm Mtl838c MBFDocumento64 páginasInm Mtl838c MBFRoberto FinaAún no hay calificaciones
- Firebird's Nbackup Tool: Paul VinkenoogDocumento20 páginasFirebird's Nbackup Tool: Paul VinkenoogMlTriAún no hay calificaciones
- Realtek PCIE Cardreader Dirver Release NotesDocumento3 páginasRealtek PCIE Cardreader Dirver Release NotesMax PlanckAún no hay calificaciones
- Agent CompatibilityDocumento9 páginasAgent Compatibilityajilani2014Aún no hay calificaciones
- CSW - White Paper - Automotive - The Use of Multi-Core Processors in The Automotive IndustryDocumento5 páginasCSW - White Paper - Automotive - The Use of Multi-Core Processors in The Automotive IndustryRudrappa ShettiAún no hay calificaciones
- Xilinx Virtex6 Pin DetailsDocumento94 páginasXilinx Virtex6 Pin DetailsArun VeluAún no hay calificaciones
- Product Manual: Logitech® X50Documento58 páginasProduct Manual: Logitech® X50Raymoon Twopass DaysAún no hay calificaciones
- Message Tracking Log AnalysisDocumento11 páginasMessage Tracking Log Analysiskalin3169899Aún no hay calificaciones
- Eaton Windows CeDocumento137 páginasEaton Windows CeGerald LugoAún no hay calificaciones
- USM Device Administration Portal CRODocumento84 páginasUSM Device Administration Portal CROSaquib.MahmoodAún no hay calificaciones
- Network BookDocumento106 páginasNetwork BookNizar AbdulhalimAún no hay calificaciones
- Engineered Solutions JRE DLT Rugged Military Computer SystemsDocumento1 páginaEngineered Solutions JRE DLT Rugged Military Computer SystemsDavid LippincottAún no hay calificaciones
- Cloud Computing - Comparison Between IaaS, PaaS, SaaS, CaaS With Examples - Assignment No.3 - Waleed Ahmed - BSEF17E05Documento9 páginasCloud Computing - Comparison Between IaaS, PaaS, SaaS, CaaS With Examples - Assignment No.3 - Waleed Ahmed - BSEF17E05Aqsa FahimAún no hay calificaciones