También podría gustarte
- Cómo Funciona El DNSDocumento8 páginasCómo Funciona El DNSkiringAún no hay calificaciones
- Ejercicios XMLDocumento6 páginasEjercicios XMLkiringAún no hay calificaciones
- Ejercicios DOMDocumento4 páginasEjercicios DOMkiringAún no hay calificaciones
- Tutorial de XMLDocumento52 páginasTutorial de XMLmanuel_fernandez_74Aún no hay calificaciones
- DNS PresentaciónDocumento40 páginasDNS PresentaciónkiringAún no hay calificaciones
- (2019-11-06) Práctica de ApacheDocumento3 páginas(2019-11-06) Práctica de ApachekiringAún no hay calificaciones
- Tema1 Seleccion de Arquitecturas y Herramientas de ProgramacionDocumento34 páginasTema1 Seleccion de Arquitecturas y Herramientas de ProgramacionluisgarciabonifazAún no hay calificaciones
- Apuntes de XMLDocumento24 páginasApuntes de XMLAbrirllaveAún no hay calificaciones
- Tema 4. Memoria Interna. Tipo. Direccionamiento. Características y FuncionesDocumento8 páginasTema 4. Memoria Interna. Tipo. Direccionamiento. Características y FuncioneskiringAún no hay calificaciones
- Tema 2. Elementos Funcionales de Un Ordenador DigitalDocumento6 páginasTema 2. Elementos Funcionales de Un Ordenador DigitalkiringAún no hay calificaciones
- Capitulo7.PDF DwecDocumento32 páginasCapitulo7.PDF DweckiringAún no hay calificaciones
- Tema 3. Componentes, Estructura y Funcionamiento de La Unidad Central de ProcesoDocumento5 páginasTema 3. Componentes, Estructura y Funcionamiento de La Unidad Central de ProcesokiringAún no hay calificaciones
- Tema 5. Microprocesadores. Estructura. Tipos. Comunicación Con El ExteriorDocumento6 páginasTema 5. Microprocesadores. Estructura. Tipos. Comunicación Con El ExteriorkiringAún no hay calificaciones
- Muestra Tem Informatica I PDFDocumento20 páginasMuestra Tem Informatica I PDFkiring100% (1)
- Examen PracticoDocumento1 páginaExamen PracticokiringAún no hay calificaciones
- Tema 1. Representación y Comunicación de La InformaciónDocumento8 páginasTema 1. Representación y Comunicación de La InformaciónkiringAún no hay calificaciones
- Ejercicios para Romper ManoDocumento3 páginasEjercicios para Romper ManokiringAún no hay calificaciones
- Tomcat 2BDocumento13 páginasTomcat 2BkiringAún no hay calificaciones
- Sub Categori Zac I OnDocumento24 páginasSub Categori Zac I Onkiring100% (1)
- Ejercicios y Tarea Del T4 Resueltos.v1.6.4Documento66 páginasEjercicios y Tarea Del T4 Resueltos.v1.6.4kiringAún no hay calificaciones
- Tomcat 2ADocumento9 páginasTomcat 2AkiringAún no hay calificaciones
- Orientaciones 3 SintesisDocumento1 páginaOrientaciones 3 SintesiskiringAún no hay calificaciones
- Trabajo Sobre Aplicaciones Java EeDocumento1 páginaTrabajo Sobre Aplicaciones Java EekiringAún no hay calificaciones
- Ampliación Quién Es QuienDocumento1 páginaAmpliación Quién Es QuienkiringAún no hay calificaciones
- Tema 5Documento53 páginasTema 5kiringAún no hay calificaciones
- Tema 6Documento68 páginasTema 6kiringAún no hay calificaciones
- Ejercicios JSONDocumento4 páginasEjercicios JSONkiringAún no hay calificaciones
- Segunda Tanda ActividadesDocumento1 páginaSegunda Tanda ActividadeskiringAún no hay calificaciones
- 2DAW Despliegue Aplicaciones WEBDocumento15 páginas2DAW Despliegue Aplicaciones WEBYasmina Sosa100% (1)
- You Dont Know JS (Esp)Documento241 páginasYou Dont Know JS (Esp)ronic blancoAún no hay calificaciones
- Abastecimiento de Agua WatercadDocumento17 páginasAbastecimiento de Agua WatercadJean Monki OrtegalAún no hay calificaciones
- QuarkXPress 8Documento467 páginasQuarkXPress 8Miguel Angel MartínAún no hay calificaciones
- Instrucciones de ExcelDocumento14 páginasInstrucciones de ExcelMaritza MlAún no hay calificaciones
- Preguntas Pmp3Documento55 páginasPreguntas Pmp3David JonesAún no hay calificaciones
- Plan Formativo Desarrollador de Aplicaciones Móviles Android Trainee 3 PDFDocumento16 páginasPlan Formativo Desarrollador de Aplicaciones Móviles Android Trainee 3 PDFFreddy Alucema TapiaAún no hay calificaciones
- Curso Fenix Programcion VideojuegosDocumento526 páginasCurso Fenix Programcion VideojuegosAprender Libre100% (3)
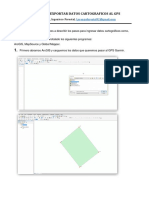
- Manual para Exportar e Importar Datos Cartograficos Al GpsDocumento11 páginasManual para Exportar e Importar Datos Cartograficos Al GpsLorenzo Ccoycca LeonAún no hay calificaciones
- Quiz 2 - Semana 7 - RA - SEGUNDO BLOQUE-ANALISIS Y VERIFICACION DE ALGORITMOS - (GRUPO1)Documento8 páginasQuiz 2 - Semana 7 - RA - SEGUNDO BLOQUE-ANALISIS Y VERIFICACION DE ALGORITMOS - (GRUPO1)Kristian OAún no hay calificaciones
- Instalacion Del Programa Vmware Workstation Pro Setup TerminadoDocumento32 páginasInstalacion Del Programa Vmware Workstation Pro Setup TerminadoOchoa VilcapomaAún no hay calificaciones
- Act U2 FHDocumento5 páginasAct U2 FHtransporte terrestreAún no hay calificaciones
- Causaciones ContablesDocumento2660 páginasCausaciones ContablesCARLOS ARTURO ALVIS ROJASAún no hay calificaciones
- Fallas en Monitores, Impresoras y Recuperacion de InformacionDocumento14 páginasFallas en Monitores, Impresoras y Recuperacion de InformacionPedro Fernando Marquez DiazAún no hay calificaciones
- La Casa de La Mosca Fosca C PDFDocumento12 páginasLa Casa de La Mosca Fosca C PDFYojaira Sosa Sánchez27% (26)
- Ups CT002157Documento204 páginasUps CT002157jasminunikaAún no hay calificaciones
- SISTEMASOPERATIVOSDocumento9 páginasSISTEMASOPERATIVOSYasser Manuel Blandón EspinozaAún no hay calificaciones
- Guía de Instalación de Audanet ComponentsDocumento6 páginasGuía de Instalación de Audanet ComponentsLUIS ALBERTO VIDALAún no hay calificaciones
- Pny Nvidia Quadro p4000 SpaDocumento1 páginaPny Nvidia Quadro p4000 SpaHenry LindoAún no hay calificaciones
- Analisis de VulnerabilidadesDocumento30 páginasAnalisis de VulnerabilidadesFranco ViacavaAún no hay calificaciones
- RBH Access - PresentaciónDocumento16 páginasRBH Access - PresentaciónDiego VelardeAún no hay calificaciones
- Clase 01Documento20 páginasClase 01DENUEY AlarconAún no hay calificaciones
- 1 Multimedia1Documento8 páginas1 Multimedia1fredymolanoAún no hay calificaciones
- Boletin Calculo de ProbabilidadesDocumento6 páginasBoletin Calculo de ProbabilidadesRGFEAún no hay calificaciones
- Practica de AlgoritmosDocumento23 páginasPractica de AlgoritmosRodrigo PusaricoAún no hay calificaciones
- Tarea 2. SOM-EDocumento6 páginasTarea 2. SOM-EWober ShopAún no hay calificaciones
- Evidencia 2: Cuadros Comparativos "Trazabilidad": Miguel Angel Medina Herrera Instructor TécnicoDocumento12 páginasEvidencia 2: Cuadros Comparativos "Trazabilidad": Miguel Angel Medina Herrera Instructor TécnicoRaul CruzAún no hay calificaciones
- Hurtado Ferran - Que Es La Geometria Computacional PDFDocumento18 páginasHurtado Ferran - Que Es La Geometria Computacional PDFalmeyda53Aún no hay calificaciones
- Visual Os ManualDocumento6 páginasVisual Os ManualCarlos Estuardo Merida BronAún no hay calificaciones
- Manual Reprap Prusa I3 3d DesktopDocumento9 páginasManual Reprap Prusa I3 3d Desktopxavierg113Aún no hay calificaciones
- Espacios de Trabajo, Paneles y VisoresDocumento10 páginasEspacios de Trabajo, Paneles y VisoresIvana Yael CurráAún no hay calificaciones