También podría gustarte
- Norma de YogurthDocumento8 páginasNorma de YogurthVanii Bellamy AllenAún no hay calificaciones
- Cómo Se Tramitan Las Concesiones y Permisos para La Explotación de Recursos NaturalesDocumento4 páginasCómo Se Tramitan Las Concesiones y Permisos para La Explotación de Recursos NaturalesVanii Bellamy AllenAún no hay calificaciones
- Trampas D VaporDocumento2 páginasTrampas D VaporVanii Bellamy AllenAún no hay calificaciones
- Datos ExperimentalesDocumento1 páginaDatos ExperimentalesVanii Bellamy AllenAún no hay calificaciones
- Introducción TeóricaDocumento7 páginasIntroducción TeóricaVanii Bellamy AllenAún no hay calificaciones
- Calidad para Agua de ProcesoDocumento1 páginaCalidad para Agua de ProcesoVanii Bellamy AllenAún no hay calificaciones
- 33e09 CANNABRIC Ficha Tecnica y EnsayosDocumento5 páginas33e09 CANNABRIC Ficha Tecnica y EnsayosVanii Bellamy AllenAún no hay calificaciones
- Propiedades Del AguaDocumento1 páginaPropiedades Del AguaVanii Bellamy AllenAún no hay calificaciones
- FenolDocumento23 páginasFenolVanii Bellamy Allen100% (2)
- Calculos Tubos Concentricos EsiqieDocumento4 páginasCalculos Tubos Concentricos EsiqieVanii Bellamy AllenAún no hay calificaciones
- Calculos CHDocumento5 páginasCalculos CHVanii Bellamy AllenAún no hay calificaciones
- Rheolab SPDocumento2 páginasRheolab SPAriday Zc VAún no hay calificaciones
- Métodos de La CienciaDocumento1 páginaMétodos de La CienciaVanii Bellamy AllenAún no hay calificaciones
- Capitulo 7 TransformadorDocumento38 páginasCapitulo 7 Transformadorgeorgebrescener64Aún no hay calificaciones
- ViscosidadDocumento10 páginasViscosidadbombolo69Aún no hay calificaciones
- Nom 033Documento46 páginasNom 033Vanii Bellamy AllenAún no hay calificaciones
- p7 PrincipiosDocumento7 páginasp7 PrincipiosVanii Bellamy AllenAún no hay calificaciones
- Objetivo Que Persigue La CienciaDocumento1 páginaObjetivo Que Persigue La CienciaVanii Bellamy AllenAún no hay calificaciones
- Desecantes y TiposDocumento4 páginasDesecantes y TiposVanii Bellamy AllenAún no hay calificaciones
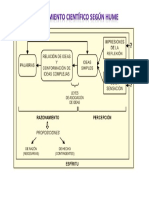
- Hume Razonamiento CientificoDocumento1 páginaHume Razonamiento CientificoVanii Bellamy AllenAún no hay calificaciones
- MatricesDocumento1 páginaMatricesVanii Bellamy AllenAún no hay calificaciones
- Ventajas y Desventajas Del Razonamiento CientíficoDocumento2 páginasVentajas y Desventajas Del Razonamiento CientíficoVanii Bellamy Allen100% (1)
- Ar BolesDocumento10 páginasAr BolesVanii Bellamy AllenAún no hay calificaciones
- Desecantes y TiposDocumento4 páginasDesecantes y TiposVanii Bellamy AllenAún no hay calificaciones
- Propiedades Del AguaDocumento1 páginaPropiedades Del AguaVanii Bellamy AllenAún no hay calificaciones
- Materiales CerámicosDocumento3 páginasMateriales CerámicosVanii Bellamy AllenAún no hay calificaciones
- Camisa y SerpentinDocumento4 páginasCamisa y SerpentinVanii Bellamy AllenAún no hay calificaciones
- ProblemarioDocumento3 páginasProblemarioVanii Bellamy AllenAún no hay calificaciones
- Desecantes y TiposDocumento4 páginasDesecantes y TiposVanii Bellamy AllenAún no hay calificaciones
- Instituto Politècnico NacionalDocumento23 páginasInstituto Politècnico NacionalLeo PerezAún no hay calificaciones
- Evaluación Geometría DescriptivaDocumento6 páginasEvaluación Geometría DescriptivaBenja Contreras HuamanAún no hay calificaciones
- Ejemplo Viga EmpotradaDocumento3 páginasEjemplo Viga EmpotradaEddi Chura MendozaAún no hay calificaciones
- Division de La EstadisticaDocumento2 páginasDivision de La Estadisticabeto100% (1)
- Mecánica de Fluidos Unidad 1Documento7 páginasMecánica de Fluidos Unidad 1ChristianJavierAún no hay calificaciones
- Guía de Función Exponencial y Logarítmica-ISGSMDocumento20 páginasGuía de Función Exponencial y Logarítmica-ISGSMmartipatricia100% (6)
- La estructura de borde del inconsciente y su efecto en la institución psicoanalíticaDocumento5 páginasLa estructura de borde del inconsciente y su efecto en la institución psicoanalíticaDennis Logroño100% (1)
- Primer SeminarioDocumento10 páginasPrimer SeminarioVeronica AlvaradoAún no hay calificaciones
- Sesion 13Documento51 páginasSesion 13Adrian De La Cruz100% (1)
- Unidad 2 SimulacionDocumento11 páginasUnidad 2 SimulacionCristina HuaraquiAún no hay calificaciones
- FICHA N°30 Act.12 EdA.8 - CANTIDAD. Planteamos Afirmaciones Sobre Prop. y Oper. Con Kcal. Notacion Científica 09.11.21 JARA.Documento6 páginasFICHA N°30 Act.12 EdA.8 - CANTIDAD. Planteamos Afirmaciones Sobre Prop. y Oper. Con Kcal. Notacion Científica 09.11.21 JARA.RAMOS OLLACHICA MARYORI JENNIFERAún no hay calificaciones
- Unidad Academica IDocumento21 páginasUnidad Academica IWashingtonCesar Palomino TerrazasAún no hay calificaciones
- PLANEACIÓN DIDÁCTICA MarzoDocumento24 páginasPLANEACIÓN DIDÁCTICA MarzoIveth GonzálezAún no hay calificaciones
- Tasas de Interés Nominal y EfectivoDocumento18 páginasTasas de Interés Nominal y EfectivoJosé TorresAún no hay calificaciones
- Enteros ResueltosDocumento7 páginasEnteros ResueltosfelixAún no hay calificaciones
- Demostracion de ZC de R K PDFDocumento2 páginasDemostracion de ZC de R K PDFJORDAN OSCAR MARCA TORRESAún no hay calificaciones
- Clase2 A1 2020 PDFDocumento2 páginasClase2 A1 2020 PDFJim Manriquez GarridoAún no hay calificaciones
- Paso 7 - Prueba de Conocimientos Unidad 3Documento5 páginasPaso 7 - Prueba de Conocimientos Unidad 3Juan Pablo Rodriguez Usme0% (1)
- Aplicación de Las Transformadas de LaplaceDocumento6 páginasAplicación de Las Transformadas de LaplaceDiego_Segoviano19Aún no hay calificaciones
- Informe Practica1 DigitalDocumento3 páginasInforme Practica1 DigitalJorge cuadrado velasquezAún no hay calificaciones
- Presocraticos 08-09Documento19 páginasPresocraticos 08-09Jose palomino praderaAún no hay calificaciones
- Ondas mecánicas: magnitudes físicas de ondas transversalesDocumento11 páginasOndas mecánicas: magnitudes físicas de ondas transversalesJairo EgusquizaAún no hay calificaciones
- Diseño de Elementos A Tension y Compresion de Una Armadura Con Uniones AtornilladasDocumento20 páginasDiseño de Elementos A Tension y Compresion de Una Armadura Con Uniones AtornilladasAlvaro Ortiz VillagomezAún no hay calificaciones
- Plano Cartesiano - Traslacion Habi 13Documento5 páginasPlano Cartesiano - Traslacion Habi 13Danielita FuentesAún no hay calificaciones
- Entrega Final Herramientas de Logica ComputacionalDocumento10 páginasEntrega Final Herramientas de Logica ComputacionalTatiana Rivas100% (1)
- Unidad 6 Grafos Digrafos y ArbolesDocumento38 páginasUnidad 6 Grafos Digrafos y ArbolesDiego IretaAún no hay calificaciones
- Cap 2 - Finanzas para DummiesDocumento5 páginasCap 2 - Finanzas para DummiesDamark BurbanoAún no hay calificaciones
- Taller - Parcial Corte 2 - 2021Documento3 páginasTaller - Parcial Corte 2 - 2021Daniel MontiillaAún no hay calificaciones
- Dibujo IsomDocumento14 páginasDibujo IsomJeanfrank GycAún no hay calificaciones
- Investigacion Tema 1 - Abigail, Jashin y Flor PDFDocumento18 páginasInvestigacion Tema 1 - Abigail, Jashin y Flor PDFAris RamirezAún no hay calificaciones