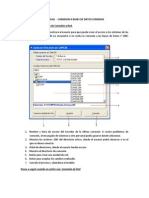
También podría gustarte
- UF2215 - Herramientas de los sistemas gestores de bases de datos. Pasarelas y medios de conexiónDe EverandUF2215 - Herramientas de los sistemas gestores de bases de datos. Pasarelas y medios de conexiónAún no hay calificaciones
- UF2213 - Modelos de datos y visión conceptual de una base de datosDe EverandUF2213 - Modelos de datos y visión conceptual de una base de datosAún no hay calificaciones
- Lenguajes de definición y modificación de datos sql. IFCT0310De EverandLenguajes de definición y modificación de datos sql. IFCT0310Aún no hay calificaciones
- 01-Generalidades de Bases de DatosDocumento5 páginas01-Generalidades de Bases de DatosHenrry Gómez Albernia0% (1)
- Cassandra Es PDFDocumento31 páginasCassandra Es PDFJohnny MerinoAún no hay calificaciones
- Análisis de datos de resistencia de arena y altura de crayonesDocumento8 páginasAnálisis de datos de resistencia de arena y altura de crayonesGeovanny ImuesAún no hay calificaciones
- SQL ProntuarioDocumento10 páginasSQL ProntuarioDani MatiAún no hay calificaciones
- Taller 1 CorteDocumento15 páginasTaller 1 CorteEduardo BolañosAún no hay calificaciones
- Enviar HoyDocumento10 páginasEnviar HoySanchez Rodriguez Mauricio JavierAún no hay calificaciones
- A Qué Se Le Denomina Base de DatosDocumento5 páginasA Qué Se Le Denomina Base de DatosSolisver GutierrezAún no hay calificaciones
- Clase 1 Gestión de Base de DatosDocumento43 páginasClase 1 Gestión de Base de DatosPio Jose valdiviaAún no hay calificaciones
- Bases de DatosDocumento20 páginasBases de DatosRuben Dario Jimenez RamirezAún no hay calificaciones
- Un Sistema Gestor de Base de Datos Está Compuesto deDocumento7 páginasUn Sistema Gestor de Base de Datos Está Compuesto deAlexis Brito GarduñoAún no hay calificaciones
- BaseDatos1-SistemasDocumento27 páginasBaseDatos1-Sistemasfefe fefeAún no hay calificaciones
- Bases de Datos Sentencias SQLDocumento47 páginasBases de Datos Sentencias SQLjorge4550% (1)
- Introduccion A Base de DatosDocumento11 páginasIntroduccion A Base de DatosJuan Alberto MnzAún no hay calificaciones
- Sistemas de Bases de DatosDocumento4 páginasSistemas de Bases de DatosEduardo Mauricio Campaña OrtegaAún no hay calificaciones
- Introducción Sistemas Bases DatosDocumento9 páginasIntroducción Sistemas Bases DatosdoensoAún no hay calificaciones
- Sistemas Gestores Bases DatosDocumento70 páginasSistemas Gestores Bases Datoschaco0527Aún no hay calificaciones
- Introducción A Las Bases de DatosDocumento10 páginasIntroducción A Las Bases de DatosAdolfo Yahir Pacheco SantosAún no hay calificaciones
- 01 - Bases de DatosDocumento11 páginas01 - Bases de DatosAlejandro TelAún no hay calificaciones
- Una Base de Datos Es Una Colección de Datos RelacionadosDocumento4 páginasUna Base de Datos Es Una Colección de Datos RelacionadosGabriel PachecoAún no hay calificaciones
- Resumen Libro Base de Datos Capitulo 1 Al 5Documento6 páginasResumen Libro Base de Datos Capitulo 1 Al 5ANDREA DEL CID100% (1)
- Apuntes BDI IDocumento11 páginasApuntes BDI IAry MmAún no hay calificaciones
- 1.1 Teoría de Bases de Datos y Manejo de InformaciónDocumento9 páginas1.1 Teoría de Bases de Datos y Manejo de InformaciónJosh GutherAún no hay calificaciones
- Introduccion FBDocumento18 páginasIntroduccion FBLupillo AnonimoAún no hay calificaciones
- Ensayo de Bases de Datos PRISCILA SALAZAR HERNANDEZDocumento4 páginasEnsayo de Bases de Datos PRISCILA SALAZAR HERNANDEZcclynew_starAún no hay calificaciones
- Base de Datos CenevalDocumento15 páginasBase de Datos CenevalOmar MatapioncheAún no hay calificaciones
- DBMS: Definición y característicasDocumento6 páginasDBMS: Definición y característicasAlfonsoCuevasAún no hay calificaciones
- Introducción a conceptos básicos de bases de datosDocumento88 páginasIntroducción a conceptos básicos de bases de datosEsther Claravalls LópezAún no hay calificaciones
- Taller de Base de Datos ExamenDocumento73 páginasTaller de Base de Datos ExamenDiana GonzalezAún no hay calificaciones
- Porta FolioDocumento17 páginasPorta FolioLucius RomaAún no hay calificaciones
- Arquitectura de Base de DatosDocumento7 páginasArquitectura de Base de DatosRuth Mora HernandezAún no hay calificaciones
- Niveles de Abstracción de Una Base de DatosDocumento4 páginasNiveles de Abstracción de Una Base de DatosSebastian JulioAún no hay calificaciones
- Sistemas Manejadores de Base de DatosDocumento11 páginasSistemas Manejadores de Base de Datosdiuzka_18Aún no hay calificaciones
- Resumen SMBDDocumento3 páginasResumen SMBDcorreo estudiantes100% (1)
- TT1 JorgeIgnacioDocumento6 páginasTT1 JorgeIgnacioivanlalvarez.22Aún no hay calificaciones
- Guia de Fundamentos de BDDocumento11 páginasGuia de Fundamentos de BDBrainman CrownlessAún no hay calificaciones
- Conceptos Introductorios de Base de DatosDocumento17 páginasConceptos Introductorios de Base de DatosJoaquín PildainAún no hay calificaciones
- Esquemas Internos de Una Base de Datos de AngelDocumento6 páginasEsquemas Internos de Una Base de Datos de Angelangeljosevasquez19Aún no hay calificaciones
- Introducción A Los Sistemas de Base de Datos PDFDocumento33 páginasIntroducción A Los Sistemas de Base de Datos PDFAntonio 2014Aún no hay calificaciones
- Base de Datos - Ing. YelminDocumento21 páginasBase de Datos - Ing. YelminskulianxAún no hay calificaciones
- A4luisernestocasadonova19 Eisn 8 012Documento7 páginasA4luisernestocasadonova19 Eisn 8 012pupuAún no hay calificaciones
- Marco ConceptualDocumento15 páginasMarco ConceptualJairoMichaelAún no hay calificaciones
- Resumen de Base de Datos Maxiel MendezDocumento6 páginasResumen de Base de Datos Maxiel MendezMAXIEL MENDEZAún no hay calificaciones
- Cuestionario de Base de DatosDocumento8 páginasCuestionario de Base de DatosCristian RiveraAún no hay calificaciones
- Ensayo Arquitectura de Una Base de Datos (Andrés Angulo)Documento2 páginasEnsayo Arquitectura de Una Base de Datos (Andrés Angulo)Andres AnguloAún no hay calificaciones
- Resumen Capitulo 1Documento2 páginasResumen Capitulo 1diana210692Aún no hay calificaciones
- Sistemas de Bases de DatosDocumento4 páginasSistemas de Bases de DatosEduardo Mauricio Campaña OrtegaAún no hay calificaciones
- Base de Datos - Ing. YelminDocumento21 páginasBase de Datos - Ing. YelminskulianxAún no hay calificaciones
- ANTOLOGIADocumento95 páginasANTOLOGIASilvetre Ascencion BarreraAún no hay calificaciones
- Base de DatosDocumento7 páginasBase de DatosDiegoAleAún no hay calificaciones
- Resumen CompuDocumento8 páginasResumen CompuCastillo GabrielAún no hay calificaciones
- BASE DE DATOS - 1 LolDocumento10 páginasBASE DE DATOS - 1 Lolcandies fireAún no hay calificaciones
- Fundamentos Teóricos de Las BDDDocumento9 páginasFundamentos Teóricos de Las BDDmissviiAún no hay calificaciones
- Conceptos GeneralesDocumento24 páginasConceptos GeneralessvidartAún no hay calificaciones
- Bases de Datos II - Ubaldo PereiraDocumento8 páginasBases de Datos II - Ubaldo PereiraJosé Eduardo Ulloa VásquezAún no hay calificaciones
- BASE DE DATOS InformacionDocumento2 páginasBASE DE DATOS InformacionMiguel BernuyAún no hay calificaciones
- Modulo de Base de Datos IDocumento57 páginasModulo de Base de Datos IMiguel Sagñay Rea100% (1)
- Investigacion Introduccion A La Bases de DatosDocumento4 páginasInvestigacion Introduccion A La Bases de DatosJeyson Isaias Mejía Paulino.Aún no hay calificaciones
- TEMA 1 Sistemas Gestores BD y Modelo ERDocumento31 páginasTEMA 1 Sistemas Gestores BD y Modelo ERjuan jesusAún no hay calificaciones
- Qué Es Un SGBDDocumento6 páginasQué Es Un SGBDCarmenAún no hay calificaciones
- Exámen COBITDocumento4 páginasExámen COBITJulian Andres Agudelo GarciaAún no hay calificaciones
- Método simplex taller mecánico optimizar producción tres productosDocumento2 páginasMétodo simplex taller mecánico optimizar producción tres productosJulian Andres Agudelo Garcia100% (1)
- Telemática y TeletrabajoDocumento14 páginasTelemática y TeletrabajoJulian Andres Agudelo GarciaAún no hay calificaciones
- Interpolación por splines cúbicosDocumento22 páginasInterpolación por splines cúbicosJo OsmarAún no hay calificaciones
- Base de Datos 1 - Práctico 5 sobre diseño relacional y dependencias funcionalesDocumento5 páginasBase de Datos 1 - Práctico 5 sobre diseño relacional y dependencias funcionalesMartin EgozcueAún no hay calificaciones
- Tema 1. - Fundamentos de Base de DatosDocumento23 páginasTema 1. - Fundamentos de Base de DatosBelarmino Tomicha Roca100% (1)
- SENA - 12 AAP10-AA1-Ev2 - Definición Del Plan de Respaldo y Restauración de Datos paraDocumento52 páginasSENA - 12 AAP10-AA1-Ev2 - Definición Del Plan de Respaldo y Restauración de Datos paraCarlos Augusto Sabino CañizaresAún no hay calificaciones
- Paso4 MetadatosDocumento27 páginasPaso4 MetadatosBrayan ReyAún no hay calificaciones
- Lección 3Documento101 páginasLección 3Anonymous gR34gQAún no hay calificaciones
- SQL Server Reporting ServicesDocumento2716 páginasSQL Server Reporting ServicesJOHN JAIRO ANGULOAún no hay calificaciones
- Base de Datos ParalelasDocumento40 páginasBase de Datos ParalelasFredy ArdilaAún no hay calificaciones
- Conexion ConcarDocumento6 páginasConexion ConcarCharly Alberty Bustamante MendozaAún no hay calificaciones
- Bases de Datos GestionDocumento8 páginasBases de Datos GestionJavier A,Aún no hay calificaciones
- El Cifrado Transparente de Datos - Orancle - 12Documento7 páginasEl Cifrado Transparente de Datos - Orancle - 12yayo007Aún no hay calificaciones
- Taller de ACCESDocumento21 páginasTaller de ACCESAlfredo MRojasAún no hay calificaciones
- 3 Guía - Fundamentos de Base de DatosDocumento16 páginas3 Guía - Fundamentos de Base de DatosNestor CAún no hay calificaciones
- Comandos SQL BásicosDocumento7 páginasComandos SQL BásicosLuz Eliana Martinez RamosAún no hay calificaciones
- Practica 2. Normalización en Una Base de Datos RelacionalDocumento4 páginasPractica 2. Normalización en Una Base de Datos RelacionalMtzanydRubyAún no hay calificaciones
- Persistencia de DatosDocumento32 páginasPersistencia de DatosCarlos Estuardo Merida BronAún no hay calificaciones
- Presentació T5 (Ampliado Fotos)Documento26 páginasPresentació T5 (Ampliado Fotos)clara100% (1)
- Insumos - Ciclo de La Tarea 2Documento30 páginasInsumos - Ciclo de La Tarea 2Paola HernandezAún no hay calificaciones
- Tarea U6T1 Punteros JonathanDocumento7 páginasTarea U6T1 Punteros JonathanJonathan Amezcua ArmentaAún no hay calificaciones
- Monografia de SQLDocumento20 páginasMonografia de SQLLivia Ccaso chipanaAún no hay calificaciones
- Biblioteca Nacional BDDocumento5 páginasBiblioteca Nacional BDDiego Armando Quiroz PérezAún no hay calificaciones
- Contenido Del Curso Geoportales ESPEDocumento7 páginasContenido Del Curso Geoportales ESPEChristiän Nöröñä100% (1)
- Sesion N 2 Terminos Basicos de Base de DatosDocumento16 páginasSesion N 2 Terminos Basicos de Base de DatosMilagros Timoteo GomezAún no hay calificaciones
- SIGESE DiccionarioDatosDocumento8 páginasSIGESE DiccionarioDatosROGER ANTHONY RAMOS PAREDESAún no hay calificaciones
- 5 sentencias SQL claveDocumento63 páginas5 sentencias SQL clavetatimayiAún no hay calificaciones
- SQLDocumento35 páginasSQLOrlandhito Medina CardenasAún no hay calificaciones
- Sobrecarga de Funciones-CURSOR REFERENCIADODocumento13 páginasSobrecarga de Funciones-CURSOR REFERENCIADOMONICAAún no hay calificaciones
- Cuestionario de InformaticaDocumento3 páginasCuestionario de InformaticaMaki LoveAún no hay calificaciones