También podría gustarte
- Organigramaunp 16 Feb 2017Documento3 páginasOrganigramaunp 16 Feb 2017Anonymous S4SSQMoAún no hay calificaciones
- Capitulo IIIDocumento5 páginasCapitulo IIIAnonymous S4SSQMoAún no hay calificaciones
- La Familia A Través Del TiempoDocumento2 páginasLa Familia A Través Del TiempoAnonymous S4SSQMo80% (5)
- Qué Es La Norma ISO 3166Documento2 páginasQué Es La Norma ISO 3166Anonymous S4SSQMoAún no hay calificaciones
- Qué Es La Norma ISO 3166Documento2 páginasQué Es La Norma ISO 3166Anonymous S4SSQMoAún no hay calificaciones
- Control de Calidad-Iso 3166Documento2 páginasControl de Calidad-Iso 3166Anonymous S4SSQMoAún no hay calificaciones
- ... Reo Sistemático, Teoría y AplicacionesDocumento17 páginas... Reo Sistemático, Teoría y AplicacionesAnonymous S4SSQMoAún no hay calificaciones
- CUADRO #03 Principales Productos Exportados: 2015 - 2016 (Millones de US Dólares de 2007)Documento4 páginasCUADRO #03 Principales Productos Exportados: 2015 - 2016 (Millones de US Dólares de 2007)Anonymous S4SSQMoAún no hay calificaciones
- Tasas de MortalidadDocumento268 páginasTasas de MortalidadAnonymous S4SSQMoAún no hay calificaciones
- Data para Control de Peso de Los PollosDocumento11 páginasData para Control de Peso de Los PollosAnonymous S4SSQMoAún no hay calificaciones
- Posicionamiento en El MercadoDocumento4 páginasPosicionamiento en El MercadoAlexis IvánAún no hay calificaciones
- Haciendo Tasa de Pobreza ExtremaDocumento12 páginasHaciendo Tasa de Pobreza ExtremaAnonymous S4SSQMoAún no hay calificaciones
- Heladeria El ChalanDocumento5 páginasHeladeria El ChalanAnonymous S4SSQMo100% (1)
- 7 Pasos para Posicionar Una Marca o ProductoDocumento8 páginas7 Pasos para Posicionar Una Marca o ProductoAnonymous S4SSQMoAún no hay calificaciones
- Edli IpcDocumento10 páginasEdli IpcAnonymous S4SSQMoAún no hay calificaciones
- Organigramaunp 16 Feb 2017Documento3 páginasOrganigramaunp 16 Feb 2017Anonymous S4SSQMoAún no hay calificaciones
- Exportaciones en El PeruDocumento4 páginasExportaciones en El PeruAnonymous S4SSQMoAún no hay calificaciones
- Palestra PDFDocumento27 páginasPalestra PDFAnonymous S4SSQMoAún no hay calificaciones
- 2 Regresion SimpleDocumento35 páginas2 Regresion SimpleAnonymous S4SSQMoAún no hay calificaciones
- Trabajo de Laboratorio de Regresion IDocumento30 páginasTrabajo de Laboratorio de Regresion IAnonymous S4SSQMoAún no hay calificaciones
- Andahuaylas KaquiabambaDocumento8 páginasAndahuaylas KaquiabambaJose Calderon CatacoraAún no hay calificaciones
- Capitulo 2 - No ParametricaDocumento24 páginasCapitulo 2 - No ParametricaAnonymous S4SSQMoAún no hay calificaciones
- DurationDocumento6 páginasDurationAnonymous S4SSQMoAún no hay calificaciones
- Guia de Muestreo FANTA - Proyecto de Asistencia Técnica para La Alimentación y NutriciónDocumento65 páginasGuia de Muestreo FANTA - Proyecto de Asistencia Técnica para La Alimentación y NutriciónRolo WilsonAún no hay calificaciones
- Exportaciones Peruanas Crecen MásDocumento15 páginasExportaciones Peruanas Crecen MásRojas EdilbertoAún no hay calificaciones
- Neuro Cien CIADocumento5 páginasNeuro Cien CIACarlos Smith PecorAún no hay calificaciones
- Data para Control de Peso de Los PollosDocumento11 páginasData para Control de Peso de Los PollosAnonymous S4SSQMoAún no hay calificaciones
- A Favor y en Contra de Las Redes SocialesDocumento5 páginasA Favor y en Contra de Las Redes SocialesCarlos Smith PecorAún no hay calificaciones
- Analisis Discriminante - SPSSDocumento84 páginasAnalisis Discriminante - SPSSAnonymous S4SSQMoAún no hay calificaciones
- Solidos FarmaceuticosDocumento6 páginasSolidos FarmaceuticosFabian AndresAún no hay calificaciones
- Cuando Una Llama Se ApagaDocumento11 páginasCuando Una Llama Se ApagajlluiAún no hay calificaciones
- Mapa de MacrorelieveDocumento1 páginaMapa de MacrorelieveGaby MacancelaAún no hay calificaciones
- Caminhão Plataforma Mercedes-Benz 2428 T6x4 - Ficha TécnicaDocumento2 páginasCaminhão Plataforma Mercedes-Benz 2428 T6x4 - Ficha TécnicaRafael Antonio Rosa Romero0% (1)
- Proyecto Integrador 2 Calentamiento GlobalDocumento4 páginasProyecto Integrador 2 Calentamiento GlobalceciliaAún no hay calificaciones
- Boletín y Elegía de Las MitasDocumento3 páginasBoletín y Elegía de Las MitasSebastián Taya50% (2)
- Ejercicios de Funcion de Primer y Segundo Grado para Discutir en ParejaDocumento1 páginaEjercicios de Funcion de Primer y Segundo Grado para Discutir en ParejaDïëgö BöhörqüëzAún no hay calificaciones
- Caso clínico-HEPATITIS AUTOINMUNE-2Documento4 páginasCaso clínico-HEPATITIS AUTOINMUNE-2Valeria GrandeAún no hay calificaciones
- La Constitucion Como Regulacion Del Poder PoliticoDocumento26 páginasLa Constitucion Como Regulacion Del Poder PoliticorocioAún no hay calificaciones
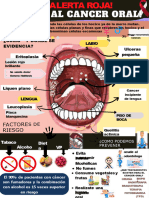
- Poster de Cancer OralDocumento1 páginaPoster de Cancer OralNoemi Cabrera OrtizAún no hay calificaciones
- 01 09 20 Comunicación L1 2°Documento5 páginas01 09 20 Comunicación L1 2°Ana BernalAún no hay calificaciones
- V. - Materialismo MilitanteDocumento8 páginasV. - Materialismo MilitanteAlexandre GiannoniAún no hay calificaciones
- Tarea 4 - Joseph CoralDocumento7 páginasTarea 4 - Joseph CoralLUIS CARLOS ZUÑIGA VILLACORTEAún no hay calificaciones
- Características Fisica TareaDocumento6 páginasCaracterísticas Fisica TareaarceliaAún no hay calificaciones
- Corrales Jáuregui Daniel - Linea Del Tiempo de La ElectrónicaDocumento1 páginaCorrales Jáuregui Daniel - Linea Del Tiempo de La ElectrónicadanielAún no hay calificaciones
- Ciatesa Mi MRDocumento20 páginasCiatesa Mi MRpetroza74Aún no hay calificaciones
- Responde A Conceptos de Psicología.Documento20 páginasResponde A Conceptos de Psicología.Petter Dipiton MateoAún no hay calificaciones
- Ensayo - Caso Chevron Texaco y EcuadorDocumento6 páginasEnsayo - Caso Chevron Texaco y EcuadorLILIANAAún no hay calificaciones
- Sol AmigurumiDocumento2 páginasSol AmigurumiAndreina Fermin100% (1)
- Planta RadiofarmaDocumento5 páginasPlanta RadiofarmaJoelBarrientosAún no hay calificaciones
- Informe de Fuerza IonicaDocumento16 páginasInforme de Fuerza IonicaKriz Tinita MirandaAún no hay calificaciones
- Resumen PerspectivasDocumento3 páginasResumen Perspectivasmaimonides76Aún no hay calificaciones
- Fundamentos Ontológicos de La RSEDocumento8 páginasFundamentos Ontológicos de La RSEMarìa Ermila Pèrez100% (1)
- Proyecto Diseño de Una InstalacionDocumento10 páginasProyecto Diseño de Una InstalacionAlex Tapara MantillaAún no hay calificaciones
- HM6116Documento4 páginasHM6116Samuel CanasaAún no hay calificaciones
- Protocolo Preventivo de Hemoparásitos Transmitidos Por Garrapatas en CaninosDocumento58 páginasProtocolo Preventivo de Hemoparásitos Transmitidos Por Garrapatas en CaninosValentina OtaloraAún no hay calificaciones
- AcondicionamientoDocumento16 páginasAcondicionamientoJohan OrdoñezAún no hay calificaciones
- Luis Orozco Xunaxhi Candelaria Unidad 1 Instalaciones ElectricasDocumento63 páginasLuis Orozco Xunaxhi Candelaria Unidad 1 Instalaciones ElectricasXunaxhi Luis100% (1)
- Quimica Organica Estereoquimica y Reacciones Quimicas PDFDocumento78 páginasQuimica Organica Estereoquimica y Reacciones Quimicas PDFShirley Hinostroza ChamorroAún no hay calificaciones