También podría gustarte
- Intelligent Techniques For Data ScienceDocumento282 páginasIntelligent Techniques For Data Scienceswjaffry100% (7)
- Learning Adobe Photoshop CS3Documento36 páginasLearning Adobe Photoshop CS3Guided Computer Tutorials88% (8)
- Qradar TopicsDocumento2 páginasQradar Topicsprasad d tAún no hay calificaciones
- ITEC 5001U, Fall 2012, Unit 2 Assignment: From Chapter 4Documento7 páginasITEC 5001U, Fall 2012, Unit 2 Assignment: From Chapter 4ahhshuga75% (4)
- QSA Main Student Study Guide 4.12Documento21 páginasQSA Main Student Study Guide 4.12Jon GordonAún no hay calificaciones
- IBM QRadar SIEM TrainingDocumento8 páginasIBM QRadar SIEM TrainingshilpaAún no hay calificaciones
- EC-Council Certified Security Analyst (ECSA) Practice ExamDocumento96 páginasEC-Council Certified Security Analyst (ECSA) Practice ExamdonaldAún no hay calificaciones
- Threat Hunting - Hunter or HuntedauthorDocumento8 páginasThreat Hunting - Hunter or HuntedauthorMateen KianiAún no hay calificaciones
- Playbook - The Network Ops DDoS PlaybookDocumento30 páginasPlaybook - The Network Ops DDoS PlaybookFmaa ArnoldAún no hay calificaciones
- CISM Certified Information Security Manager Exam QuestionsDocumento5 páginasCISM Certified Information Security Manager Exam QuestionsMTAún no hay calificaciones
- McAfee SIEM POC Setup GuideDocumento61 páginasMcAfee SIEM POC Setup Guideab_laaroussi50% (2)
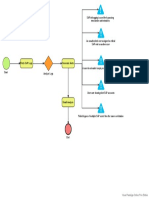
- SIEM Process FlowDocumento1 páginaSIEM Process FlowhallarmemonAún no hay calificaciones
- Pentest QuestionareDocumento7 páginasPentest QuestionareMaqsood Alam100% (1)
- Analysis of Incident Response Tactics For The Extreme Insecure WebsiteDocumento18 páginasAnalysis of Incident Response Tactics For The Extreme Insecure WebsiteAmandaAún no hay calificaciones
- McAfee SIEM POC Setup Guide (9.4) PDFDocumento61 páginasMcAfee SIEM POC Setup Guide (9.4) PDFgheodanAún no hay calificaciones
- CNDDocumento4 páginasCNDDandy GonzálezAún no hay calificaciones
- Anatomy of A Breach - Cyber SecurityDocumento22 páginasAnatomy of A Breach - Cyber SecurityAgustínParoli100% (1)
- Accenture Splunk Cyber Defense Solution PDFDocumento8 páginasAccenture Splunk Cyber Defense Solution PDFmalli karjunAún no hay calificaciones
- 114 Pentesting APIs and Cloud ApplicationsDocumento140 páginas114 Pentesting APIs and Cloud Applicationsamin jahromiAún no hay calificaciones
- MITRE ATT&CK® Best Practices MappingDocumento22 páginasMITRE ATT&CK® Best Practices MappingricardoAún no hay calificaciones
- SOC QuestionsDocumento24 páginasSOC QuestionsDark Storm WolfAún no hay calificaciones
- Preparing For The CISM ExamDocumento1 páginaPreparing For The CISM Examadane24Aún no hay calificaciones
- Exabeam SecurityDocumento32 páginasExabeam SecurityAbie Widyatmojo100% (1)
- Chapter 5 - Security Operations QuizDocumento6 páginasChapter 5 - Security Operations Quizmario.ochoa.rAún no hay calificaciones
- SE571 Air Craft Solutions - Phase 1Documento7 páginasSE571 Air Craft Solutions - Phase 1zkeatleyAún no hay calificaciones
- Siem - ReportDocumento8 páginasSiem - Reportapi-335480408Aún no hay calificaciones
- Tenablesc UserGuideDocumento665 páginasTenablesc UserGuideLucas RealAún no hay calificaciones
- COMMVAULT SnapProtect FieldGuide For NetApp Storage - Including SnapMirror and SnapVault IntegrationDocumento73 páginasCOMMVAULT SnapProtect FieldGuide For NetApp Storage - Including SnapMirror and SnapVault IntegrationBharath PriyaAún no hay calificaciones
- Darktrace: Best Practices For Small Teams: Data SheetDocumento8 páginasDarktrace: Best Practices For Small Teams: Data SheetLuc CardAún no hay calificaciones
- Security by Design Framework PDFDocumento51 páginasSecurity by Design Framework PDFميلاد نوروزي رهبرAún no hay calificaciones
- GIAC CertificationsDocumento13 páginasGIAC CertificationsYemi ShowunmiAún no hay calificaciones
- Top 15 Indicators of CompromiseDocumento7 páginasTop 15 Indicators of CompromisenandaanujAún no hay calificaciones
- NeXpose User GuideDocumento317 páginasNeXpose User GuidePrince WilliamsAún no hay calificaciones
- 28.4.13 Lab - Incident HandlingDocumento3 páginas28.4.13 Lab - Incident HandlingBroe MelloAún no hay calificaciones
- Tenable Csis Compliance WhitepaperDocumento22 páginasTenable Csis Compliance Whitepapernaushad73Aún no hay calificaciones
- CCNA Cyber Ops (Version 1.1) - Chapter 10 Exam Answers FullDocumento13 páginasCCNA Cyber Ops (Version 1.1) - Chapter 10 Exam Answers FullSaber TunisienAún no hay calificaciones
- 8 Best SIEM SolutionsDocumento10 páginas8 Best SIEM SolutionsJag GeronimoAún no hay calificaciones
- MAS - Methodology To Select Security Information and Event Management (SIEM) Use CasesDocumento35 páginasMAS - Methodology To Select Security Information and Event Management (SIEM) Use CasesHafiz SafwanAún no hay calificaciones
- Guide To Threat ModelingDocumento30 páginasGuide To Threat ModelingVivek DAún no hay calificaciones
- Correlation Rules and Engine Debugging1Documento30 páginasCorrelation Rules and Engine Debugging1JC AMAún no hay calificaciones
- Cyber Security Notes Unit 3Documento8 páginasCyber Security Notes Unit 3Reshma BasuAún no hay calificaciones
- Defending Microsoft environments at scaleDocumento31 páginasDefending Microsoft environments at scalekeepzthebeezAún no hay calificaciones
- CC DemoDocumento3 páginasCC DemoMuhammad FahadAún no hay calificaciones
- MEM CPE - Handbook DIGITALDocumento20 páginasMEM CPE - Handbook DIGITALmebreaAún no hay calificaciones
- IBM Security Ransomware Client Engagement GuideDocumento46 páginasIBM Security Ransomware Client Engagement GuideOmarAún no hay calificaciones
- CCSK notes-MGDocumento23 páginasCCSK notes-MGN Sai Avinash100% (1)
- SIEM Use Case Development Guide v.2Documento7 páginasSIEM Use Case Development Guide v.2cnbird100% (1)
- McAfee Threat Hunting Solution BriefDocumento3 páginasMcAfee Threat Hunting Solution BriefozgurerdoganAún no hay calificaciones
- Esm Guide PDFDocumento340 páginasEsm Guide PDFabbuasherAún no hay calificaciones
- ESM AdminGuide 6.9.1Documento186 páginasESM AdminGuide 6.9.1aziz.rhazlaniAún no hay calificaciones
- Lesson 4 Collecting and Querying SecurityDocumento37 páginasLesson 4 Collecting and Querying SecurityDickson PaminAún no hay calificaciones
- Welcome To Ipaymy: SSLI-1727603986-199/3.0Documento26 páginasWelcome To Ipaymy: SSLI-1727603986-199/3.0Ngọc Nghĩa PhạmAún no hay calificaciones
- Gartner Database Activity Monitoring Is Evolving Into Database Audit and ProtectionDocumento4 páginasGartner Database Activity Monitoring Is Evolving Into Database Audit and ProtectionJuank CifuentesAún no hay calificaciones
- Guide to Procuring a Security Operations Centre (SOCDocumento10 páginasGuide to Procuring a Security Operations Centre (SOCep230842Aún no hay calificaciones
- Guardium Administration Help BookDocumento88 páginasGuardium Administration Help Bookreanve0% (1)
- Forcepoint UEBA: User & Entity Behavior AnalyticsDocumento23 páginasForcepoint UEBA: User & Entity Behavior AnalyticsvuyaniAún no hay calificaciones
- Symantec Endpoint Protection - Few Registry Tweaks.Documento17 páginasSymantec Endpoint Protection - Few Registry Tweaks.David Brasil da CunhaAún no hay calificaciones
- Security+ Practice Exam - 65 Questions Just For PracticeDocumento35 páginasSecurity+ Practice Exam - 65 Questions Just For PracticeZeeshan RanaAún no hay calificaciones
- Using Splunk To Develop An Incident Response Plan: White PaperDocumento7 páginasUsing Splunk To Develop An Incident Response Plan: White Paperhuy hoangAún no hay calificaciones
- Risk Assessment Process Nist 80030 7383Documento20 páginasRisk Assessment Process Nist 80030 7383datadinkAún no hay calificaciones
- CIS IBM DB2 9 Benchmark v3.0.1Documento206 páginasCIS IBM DB2 9 Benchmark v3.0.1Andrei SandulescuAún no hay calificaciones
- Security: The Great Cloud Inhibitor: Brought To You by andDocumento4 páginasSecurity: The Great Cloud Inhibitor: Brought To You by anddeals4kbAún no hay calificaciones
- Dopra Linux OS Security SingleRAN 12 PDFDocumento48 páginasDopra Linux OS Security SingleRAN 12 PDFmickycachoperro0% (1)
- Document Fraud Detecting SystemDocumento5 páginasDocument Fraud Detecting SystemHarshit SrivastavaAún no hay calificaciones
- Oracle Exalogic Elastic Cloud Backup and Recovery Guide Using ExaBR E36329-05Documento52 páginasOracle Exalogic Elastic Cloud Backup and Recovery Guide Using ExaBR E36329-05Soumendu GoraiAún no hay calificaciones
- Oracle SQL Developer Keyboard Shortcuts: by ViaDocumento1 páginaOracle SQL Developer Keyboard Shortcuts: by ViasatyajitAún no hay calificaciones
- SICAM 230 Manual: History of ChangesDocumento14 páginasSICAM 230 Manual: History of ChangesELVIS JOHAN LAUREANO APOLINARIOAún no hay calificaciones
- Devendra Net Developer ResumeDocumento7 páginasDevendra Net Developer ResumeMohamed SaidAún no hay calificaciones
- How To Change Compatible Parameter in OracleDocumento3 páginasHow To Change Compatible Parameter in OracleAbhjijit ChandraAún no hay calificaciones
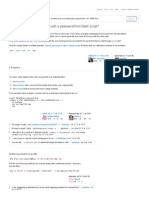
- Run SFTP - PWD From Bash ScriptDocumento4 páginasRun SFTP - PWD From Bash ScriptKARTHIK145Aún no hay calificaciones
- Vaadin Fact Sheet: Components: A Modern Set of Web Components For Business ApplicationsDocumento11 páginasVaadin Fact Sheet: Components: A Modern Set of Web Components For Business ApplicationsThiago MonteiroAún no hay calificaciones
- Samsung Serial NumberDocumento4 páginasSamsung Serial NumberNsb El-kathiriAún no hay calificaciones
- Boost Your Productivity with Advanced ToolsDocumento32 páginasBoost Your Productivity with Advanced Toolsghor venusAún no hay calificaciones
- Health Information System For A HospitalDocumento26 páginasHealth Information System For A HospitalJayathri WijayarathneAún no hay calificaciones
- Goldengate Internationalization Best Practices For V11.2.1: Oracle-To-OracleDocumento14 páginasGoldengate Internationalization Best Practices For V11.2.1: Oracle-To-OracleTebs AAún no hay calificaciones
- Omnis Web ServicesDocumento50 páginasOmnis Web ServicesJorge ReyesAún no hay calificaciones
- What Is NormalizationDocumento9 páginasWhat Is NormalizationBhagya Sri MallelaAún no hay calificaciones
- Industrial Training Report: Submitted By: Puru Govind (02bce070) Btech (Cse)Documento21 páginasIndustrial Training Report: Submitted By: Puru Govind (02bce070) Btech (Cse)Er Meghvrat AryaAún no hay calificaciones
- Seedlink Technologies Terms and ConditionsDocumento71 páginasSeedlink Technologies Terms and Conditionsmatheus figueiraAún no hay calificaciones
- Redhat EX310 ExamDocumento8 páginasRedhat EX310 Examsafyh2005Aún no hay calificaciones
- Contoh Soal SapDocumento11 páginasContoh Soal SapWildan HaryonoAún no hay calificaciones
- IBM Business Process Manager Operations Guide: BooksDocumento134 páginasIBM Business Process Manager Operations Guide: BooksJose DominguezAún no hay calificaciones
- Connectivity Guide For IBM InfoSphere Classic Federation Server For z/OSDocumento70 páginasConnectivity Guide For IBM InfoSphere Classic Federation Server For z/OSRoshava KratunaAún no hay calificaciones
- Smart Explorer - Software - Manual - v2.0.2.0Documento29 páginasSmart Explorer - Software - Manual - v2.0.2.0Saiful ShokriAún no hay calificaciones
- SQL Ex2Documento2 páginasSQL Ex2Sujai SenthilAún no hay calificaciones
- Linux Sample ResumeDocumento2 páginasLinux Sample ResumeMONUAún no hay calificaciones
- Available Freeware ListDocumento268 páginasAvailable Freeware Listriddhee0% (1)
- Z Pending Pos ReportDocumento14 páginasZ Pending Pos Reportolecosas4273Aún no hay calificaciones