También podría gustarte
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryCalificación: 3.5 de 5 estrellas3.5/5 (231)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Calificación: 4.5 de 5 estrellas4.5/5 (119)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe EverandNever Split the Difference: Negotiating As If Your Life Depended On ItCalificación: 4.5 de 5 estrellas4.5/5 (838)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaCalificación: 4.5 de 5 estrellas4.5/5 (265)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe EverandThe Little Book of Hygge: Danish Secrets to Happy LivingCalificación: 3.5 de 5 estrellas3.5/5 (399)
- Grit: The Power of Passion and PerseveranceDe EverandGrit: The Power of Passion and PerseveranceCalificación: 4 de 5 estrellas4/5 (587)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyCalificación: 3.5 de 5 estrellas3.5/5 (2219)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeCalificación: 4 de 5 estrellas4/5 (5794)
- Team of Rivals: The Political Genius of Abraham LincolnDe EverandTeam of Rivals: The Political Genius of Abraham LincolnCalificación: 4.5 de 5 estrellas4.5/5 (234)
- Rise of ISIS: A Threat We Can't IgnoreDe EverandRise of ISIS: A Threat We Can't IgnoreCalificación: 3.5 de 5 estrellas3.5/5 (137)
- Shoe Dog: A Memoir by the Creator of NikeDe EverandShoe Dog: A Memoir by the Creator of NikeCalificación: 4.5 de 5 estrellas4.5/5 (537)
- The Emperor of All Maladies: A Biography of CancerDe EverandThe Emperor of All Maladies: A Biography of CancerCalificación: 4.5 de 5 estrellas4.5/5 (271)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreCalificación: 4 de 5 estrellas4/5 (1090)
- Her Body and Other Parties: StoriesDe EverandHer Body and Other Parties: StoriesCalificación: 4 de 5 estrellas4/5 (821)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersCalificación: 4.5 de 5 estrellas4.5/5 (344)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceCalificación: 4 de 5 estrellas4/5 (890)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureCalificación: 4.5 de 5 estrellas4.5/5 (474)
- The Unwinding: An Inner History of the New AmericaDe EverandThe Unwinding: An Inner History of the New AmericaCalificación: 4 de 5 estrellas4/5 (45)
- The Yellow House: A Memoir (2019 National Book Award Winner)De EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Calificación: 4 de 5 estrellas4/5 (98)
- The Perks of Being a WallflowerDe EverandThe Perks of Being a WallflowerCalificación: 4.5 de 5 estrellas4.5/5 (2099)
- On Fire: The (Burning) Case for a Green New DealDe EverandOn Fire: The (Burning) Case for a Green New DealCalificación: 4 de 5 estrellas4/5 (73)
- Sculpting in Time With Andrei TarkovskyDocumento3 páginasSculpting in Time With Andrei Tarkovsky65paulosalesAún no hay calificaciones
- Iso Cie 11664-5-2016Documento16 páginasIso Cie 11664-5-2016Kuya Fabio VidalAún no hay calificaciones
- This Color Fill Indicates A Chang BlueDocumento269 páginasThis Color Fill Indicates A Chang Blueapi-27421281Aún no hay calificaciones
- DIP AssignmentDocumento4 páginasDIP AssignmentUjjwal SiddharthAún no hay calificaciones
- Linde Service Guide: ArrangementDocumento2 páginasLinde Service Guide: ArrangementTrần Đức PhiAún no hay calificaciones
- 3ds Max Training by Unique CivilDocumento5 páginas3ds Max Training by Unique CivilRatnesh ShuklaAún no hay calificaciones
- Introduction To Arnold For Maya: Standard SurfaceDocumento7 páginasIntroduction To Arnold For Maya: Standard SurfaceNazareno NenoAún no hay calificaciones
- Lab 8 DSPDocumento9 páginasLab 8 DSPzubair tahirAún no hay calificaciones
- Kode Warna PhotoshopDocumento8 páginasKode Warna PhotoshopNonkzu LozanoAún no hay calificaciones
- LQ45 Trading AnalysisDocumento16 páginasLQ45 Trading AnalysisBella Nurul IstiqomahAún no hay calificaciones
- RABIN Slide Presentation For WebpageDocumento22 páginasRABIN Slide Presentation For WebpageObet RiawanAún no hay calificaciones
- A Survey Based On Region Based Segmentation: S.Karthick Dr.K.SathiyasekarDocumento5 páginasA Survey Based On Region Based Segmentation: S.Karthick Dr.K.SathiyasekarJunaid KhanAún no hay calificaciones
- COPOMIS BrochureDocumento2 páginasCOPOMIS BrochureAmit PoudelAún no hay calificaciones
- Image WordDocumento5 páginasImage WordSai RoyalsAún no hay calificaciones
- Photoshop Course OutlineDocumento3 páginasPhotoshop Course OutlineAlireza UAún no hay calificaciones
- Projection NewDocumento27 páginasProjection NewAysha Akter UrmiAún no hay calificaciones
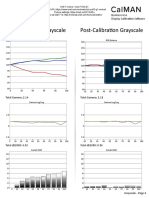
- Vizio PX65-G1 CNET Review Calibration ResultsDocumento3 páginasVizio PX65-G1 CNET Review Calibration ResultsDavid KatzmaierAún no hay calificaciones
- ImageProcessing11 MorphologyDocumento48 páginasImageProcessing11 MorphologyfamtaluAún no hay calificaciones
- Pyramid Methods in Image ProcessingDocumento47 páginasPyramid Methods in Image ProcessingAashish NagpalAún no hay calificaciones
- Konsep Dasar, Optimalisasi, Dan Teknik Pengurangan Dosis Pada Pesawat CT ScanDocumento31 páginasKonsep Dasar, Optimalisasi, Dan Teknik Pengurangan Dosis Pada Pesawat CT Scanrifqi anisaAún no hay calificaciones
- LK Permanent Cream ColorDocumento1 páginaLK Permanent Cream ColorvoluharicuAún no hay calificaciones
- Kartu Stok JanDocumento35 páginasKartu Stok JanPPIC AWSAún no hay calificaciones
- Multimedia - LECTURE 2Documento68 páginasMultimedia - LECTURE 2Hemed hafidhAún no hay calificaciones
- Image FusionDocumento86 páginasImage FusionAbhishek Reddy GarlapatiAún no hay calificaciones
- Gamma 2.2 Setup or Linear Workflow: Before You StartDocumento13 páginasGamma 2.2 Setup or Linear Workflow: Before You Startjelena1004Aún no hay calificaciones
- Amarelo CaterpillarDocumento1 páginaAmarelo CaterpillaraleciolyraAún no hay calificaciones
- Paptrade Enterprises Updated Price ListDocumento22 páginasPaptrade Enterprises Updated Price ListReignz Giangan MosquedaAún no hay calificaciones
- Product Overview: AR1335: CMOS Image Sensor, 13 MP, 1/3"Documento2 páginasProduct Overview: AR1335: CMOS Image Sensor, 13 MP, 1/3"Selven ThiranAún no hay calificaciones
- Image Sub-Sampling and PyramidsDocumento63 páginasImage Sub-Sampling and PyramidsMortal xxAún no hay calificaciones
- ANU Image Processing Pre PhD Exam GuideDocumento2 páginasANU Image Processing Pre PhD Exam Guideksai.mbAún no hay calificaciones