También podría gustarte
- Practica Calificada 2°unidad (David Mauro Arocutipa Huisa)Documento6 páginasPractica Calificada 2°unidad (David Mauro Arocutipa Huisa)Mauro Arocutipa HuisaAún no hay calificaciones
- Modelo de DomarDocumento7 páginasModelo de DomarDavid EspinosaAún no hay calificaciones
- Busqueda de OportunidadesDocumento29 páginasBusqueda de OportunidadesAdri Aroni50% (2)
- CONJUNTOSDocumento6 páginasCONJUNTOSMilka QuecheAún no hay calificaciones
- Guia de EstadisticaDocumento23 páginasGuia de EstadisticaMaylito Atero MoralesAún no hay calificaciones
- Estadistica - Comprension LectoraDocumento3 páginasEstadistica - Comprension LectoraEdinson Prado MurilloAún no hay calificaciones
- Resumen de Los Capítulos VII y VII Del Libro "Desnudando La Mente Del Consumidor"Documento3 páginasResumen de Los Capítulos VII y VII Del Libro "Desnudando La Mente Del Consumidor"Fernanda Urizar QuispeAún no hay calificaciones
- Marco TeoricoDocumento4 páginasMarco TeoricoLiz Gaby Colorado QuispeAún no hay calificaciones
- Orga TrabajoDocumento8 páginasOrga TrabajoLuisAlfredoHuanacoMamaniAún no hay calificaciones
- Solucionario T3-20221Documento8 páginasSolucionario T3-20221Nirvana HornaAún no hay calificaciones
- Parcial 3 (0260) PDFDocumento3 páginasParcial 3 (0260) PDFRodrigo SantomeAún no hay calificaciones
- Matriz de ResultadosDocumento3 páginasMatriz de ResultadosveroAún no hay calificaciones
- Pequeñas Diferencias y Coyunturas CríticasDocumento3 páginasPequeñas Diferencias y Coyunturas CríticasAbigail Quiñonez RiveraAún no hay calificaciones
- I CondicionesGeneralesDeLaEconomia Agosto2017 PDFDocumento746 páginasI CondicionesGeneralesDeLaEconomia Agosto2017 PDFLorenzo antonioAún no hay calificaciones
- LABORATORIO No 1 - USO NLOGITDocumento8 páginasLABORATORIO No 1 - USO NLOGITJazmin Emely Barzola De La CruzAún no hay calificaciones
- Graficos EstadisticosDocumento11 páginasGraficos EstadisticosNohely EdgarAún no hay calificaciones
- 1er Parcial de Estadistica Aplicada A Los NegociosDocumento3 páginas1er Parcial de Estadistica Aplicada A Los NegociosJulieta Billordo OjedaAún no hay calificaciones
- Microeconomia Trabajo FinalDocumento5 páginasMicroeconomia Trabajo FinaldennisAún no hay calificaciones
- Ensayo Sector EmpresarialDocumento2 páginasEnsayo Sector EmpresarialKevin RAún no hay calificaciones
- Solución de Preguntas Del Caso Menton Bank Y Resumen de Los Casos " " & "Documento13 páginasSolución de Preguntas Del Caso Menton Bank Y Resumen de Los Casos " " & "Maria Laura Tone BurgosAún no hay calificaciones
- Que Son Gráficos EstadísticosDocumento5 páginasQue Son Gráficos EstadísticosAugusto TahualAún no hay calificaciones
- Restaurante El TapequeDocumento4 páginasRestaurante El Tapequewilson avila chaconAún no hay calificaciones
- Reflexion Video Coach CarterDocumento13 páginasReflexion Video Coach CarterJuan Felipe BravoAún no hay calificaciones
- Práctica Dirigida Nº1Documento4 páginasPráctica Dirigida Nº1Marcela Tito SantanaAún no hay calificaciones
- Presentacion CalculoDocumento4 páginasPresentacion Calculoduvanquintero ccAún no hay calificaciones
- Plan Estratégico Polleria CamposDocumento13 páginasPlan Estratégico Polleria CamposAdrianaAún no hay calificaciones
- Analisis Foda Ya ResueltoDocumento3 páginasAnalisis Foda Ya ResueltoGustavo TaramuelAún no hay calificaciones
- Evaluacion Interna de Matematicas NM Tarea 2Documento7 páginasEvaluacion Interna de Matematicas NM Tarea 2Gloria barrueta natividadAún no hay calificaciones
- Tarea Micro y MacroDocumento10 páginasTarea Micro y MacroDaniel Estrada RochabrunAún no hay calificaciones
- Curva de ValorDocumento4 páginasCurva de ValorLau CasAún no hay calificaciones
- Modelo Domar Economia PDFDocumento4 páginasModelo Domar Economia PDFLuzMeryBravoZarateAún no hay calificaciones
- Trabajo Final Analisis Interno y ExternoDocumento12 páginasTrabajo Final Analisis Interno y ExternoJazsperk Danilow PsAún no hay calificaciones
- ClimDocumento2 páginasClimJoel Monje0% (1)
- Calculando El Punto de Equilibrio Entre La Oferta Y La DemandaDocumento1 páginaCalculando El Punto de Equilibrio Entre La Oferta Y La DemandaJose LopezAún no hay calificaciones
- Estudio de viabilidad para planta de abonos orgánicosDocumento9 páginasEstudio de viabilidad para planta de abonos orgánicosGODOFREDO ROMAN LOBATO CALDERONAún no hay calificaciones
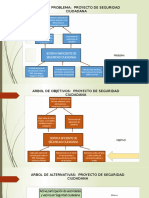
- Proyecto Seguridad Ciudadana Marco LógicoDocumento4 páginasProyecto Seguridad Ciudadana Marco LógicoliyumonviAún no hay calificaciones
- Analisis de Video CatastroikaDocumento2 páginasAnalisis de Video CatastroikaEconomiaAún no hay calificaciones
- Analisis PestelDocumento3 páginasAnalisis PestelYnf Yersii Juan Altamirano0% (1)
- Prueba de Entrada VirtualDocumento1 páginaPrueba de Entrada VirtualDavid O. BasauriAún no hay calificaciones
- Que Es FodaDocumento7 páginasQue Es FodaJessie Maye Anampa ZeaAún no hay calificaciones
- (520372698) Aplicación de Las Matrices A La Economía FamiliarDocumento2 páginas(520372698) Aplicación de Las Matrices A La Economía FamiliarJimmy León Támara100% (1)
- Roca (2019) Macroeconomía GlobalDocumento290 páginasRoca (2019) Macroeconomía GlobalAnonymous WyZwSz100% (1)
- Solucion de La Practica 1 y 2Documento13 páginasSolucion de La Practica 1 y 2Frank Hernández50% (2)
- EVALUACIONnFUNCIONnLOGICA 425fce759d6683cDocumento6 páginasEVALUACIONnFUNCIONnLOGICA 425fce759d6683cSANDYAún no hay calificaciones
- Marketing Producto Innovador PDFDocumento8 páginasMarketing Producto Innovador PDFTere ValenciaAún no hay calificaciones
- SCAMPERDocumento8 páginasSCAMPERMaria Veloz AlvarezAún no hay calificaciones
- Algoritmos de flujo para calcular notas y resultados deportivosDocumento50 páginasAlgoritmos de flujo para calcular notas y resultados deportivosSullin Santaella0% (1)
- 2 El Modelo de Regresion Lineal Simple Estimacion y PropiedadesDocumento49 páginas2 El Modelo de Regresion Lineal Simple Estimacion y PropiedadesLLd.100% (1)
- Math.1111.t2 Entregable OkDocumento11 páginasMath.1111.t2 Entregable OkBrando LoayzaAún no hay calificaciones
- GuionDocumento2 páginasGuionElvergalinda RosamelhoyoAún no hay calificaciones
- Examen de Io de MilagrosDocumento4 páginasExamen de Io de MilagrosErick Alexitho Maldonado SenceAún no hay calificaciones
- Creatividad y Características EmprendedorasDocumento4 páginasCreatividad y Características EmprendedorasandresAún no hay calificaciones
- Informes de MarketingDocumento29 páginasInformes de MarketingAlexis Obed Sánchez IlquimicheAún no hay calificaciones
- Análisis FODA Didatic SA juguetería educativaDocumento3 páginasAnálisis FODA Didatic SA juguetería educativaluz mila lozano0% (1)
- Políticas SectorialesDocumento11 páginasPolíticas SectorialesnstoruizAún no hay calificaciones
- Escala Prefectura de PichinchaDocumento2 páginasEscala Prefectura de PichinchaEdison Giovanny Anrango Medina0% (1)
- Métodos numéricos para la resolución de ecuaciones no linealesDocumento36 páginasMétodos numéricos para la resolución de ecuaciones no linealesBeto Pacichana DominguezAún no hay calificaciones
- Trabajo Final de Eviews Por Obed Joel Condori QuispeDocumento14 páginasTrabajo Final de Eviews Por Obed Joel Condori QuispeObed Joel Condori QuispeAún no hay calificaciones
- Actividad No. 1Documento6 páginasActividad No. 1Perla OrtizAún no hay calificaciones
- Tarea 1 Administracion FinancieraDocumento6 páginasTarea 1 Administracion FinancieraChepe LozanoAún no hay calificaciones
- BOCETOSDocumento1 páginaBOCETOSAlicia Sigüenza MarcoAún no hay calificaciones
- Matrices Elementales Parte PDFDocumento18 páginasMatrices Elementales Parte PDFAlicia Sigüenza MarcoAún no hay calificaciones
- El Tigre BlancoDocumento2 páginasEl Tigre BlancoAlicia Sigüenza MarcoAún no hay calificaciones
- Matrices Elementales ParteDocumento18 páginasMatrices Elementales ParteAlicia Sigüenza MarcoAún no hay calificaciones
- 04 Sistemas Lineales Con ParametrosDocumento28 páginas04 Sistemas Lineales Con ParametrosFlower PowerAún no hay calificaciones
- (Ahí / Ay / Hay) Están Mis Amigos! (Hasta / Asta) El PuebloDocumento2 páginas(Ahí / Ay / Hay) Están Mis Amigos! (Hasta / Asta) El PuebloAlicia Sigüenza MarcoAún no hay calificaciones
- Calculo de Derivadas Parte 3Documento26 páginasCalculo de Derivadas Parte 3Alicia Sigüenza MarcoAún no hay calificaciones
- Ho Jade Problem As Definiti VaDocumento54 páginasHo Jade Problem As Definiti VaAlicia Sigüenza MarcoAún no hay calificaciones
- Open CourseDocumento2 páginasOpen CourseAlicia Sigüenza MarcoAún no hay calificaciones
- Funciones de 1 Variable Parte 1Documento28 páginasFunciones de 1 Variable Parte 1Alicia Sigüenza MarcoAún no hay calificaciones
- Ho Jade Problem As Interact IvaDocumento4 páginasHo Jade Problem As Interact IvaAlicia Sigüenza MarcoAún no hay calificaciones
- Contabilidad de Tareas Matematicas OctubreDocumento3 páginasContabilidad de Tareas Matematicas OctubreAlicia Sigüenza MarcoAún no hay calificaciones
- 2 ESO Lengua Cuaderno Recuperación Verano PDFDocumento16 páginas2 ESO Lengua Cuaderno Recuperación Verano PDFUrsula Anita Oyola AncajimaAún no hay calificaciones
- Funciones de 2 Variable Parte 2Documento22 páginasFunciones de 2 Variable Parte 2Alicia Sigüenza MarcoAún no hay calificaciones
- Examen de NaturalesDocumento1 páginaExamen de NaturalesAlicia Sigüenza MarcoAún no hay calificaciones
- Señor Padre de FamiliaDocumento1 páginaSeñor Padre de FamiliaAlicia Sigüenza MarcoAún no hay calificaciones
- DISOLUCIONESDocumento1 páginaDISOLUCIONESAlicia Sigüenza MarcoAún no hay calificaciones
- Caso Práctico Tema 3Documento2 páginasCaso Práctico Tema 3Alicia Sigüenza MarcoAún no hay calificaciones
- Leyes Químicas FundamentalesDocumento32 páginasLeyes Químicas FundamentalesIllänëp SílvíäAún no hay calificaciones
- Preguntas InnovaciónDocumento1 páginaPreguntas InnovaciónAlicia Sigüenza MarcoAún no hay calificaciones
- Preguntas InnovaciónDocumento1 páginaPreguntas InnovaciónAlicia Sigüenza MarcoAún no hay calificaciones
- Disoluciones Resueltos PDFDocumento5 páginasDisoluciones Resueltos PDFadolfo olmosAún no hay calificaciones
- Mezclas QuimicasDocumento8 páginasMezclas QuimicasAlicia Sigüenza MarcoAún no hay calificaciones
- 1Documento3 páginas1Alicia Sigüenza MarcoAún no hay calificaciones
- Pasado SimpleDocumento1 páginaPasado SimpleAlicia Sigüenza MarcoAún no hay calificaciones
- Examen de InglésDocumento2 páginasExamen de InglésAlicia Sigüenza MarcoAún no hay calificaciones
- Breve Esquema BIOELEMENTOS 1º BachDocumento2 páginasBreve Esquema BIOELEMENTOS 1º BachjavierAún no hay calificaciones
- Los Números IrracionalesDocumento13 páginasLos Números IrracionalesAlicia Sigüenza MarcoAún no hay calificaciones
- Preguntas InnovaciónDocumento1 páginaPreguntas InnovaciónAlicia Sigüenza MarcoAún no hay calificaciones
- Soluciones de Las Actividades de EvaluaciónDocumento4 páginasSoluciones de Las Actividades de EvaluaciónAlicia Sigüenza MarcoAún no hay calificaciones
- Contrato de MovilidadDocumento2 páginasContrato de MovilidadMary Bustamante RodriguezAún no hay calificaciones
- Acta Acuerdo de EvaluaciónDocumento6 páginasActa Acuerdo de EvaluaciónFredy GonzalezAún no hay calificaciones
- Estilos de aprendizaje enDocumento3 páginasEstilos de aprendizaje enPsicoplasmadAún no hay calificaciones
- Acta 21 de Defensa Publica Jahel Vasquez SalazarDocumento1 páginaActa 21 de Defensa Publica Jahel Vasquez SalazarGabinete UdabolAún no hay calificaciones
- Fichas de EtiquetasDocumento9 páginasFichas de EtiquetasPauloContrerasAún no hay calificaciones
- Preguntas Sobre La PeliculaDocumento1 páginaPreguntas Sobre La PeliculaAndrea Solo Yo Andrea0% (1)
- ElimetodologiaDocumento2 páginasElimetodologiakateliz28Aún no hay calificaciones
- 9 - Crucigrama Guia de Aprendizaje Sin RespuestasDocumento3 páginas9 - Crucigrama Guia de Aprendizaje Sin Respuestassergio67% (36)
- 5.3 E Reconocer Las Emociones en Los Demas Comunicacion PDFDocumento3 páginas5.3 E Reconocer Las Emociones en Los Demas Comunicacion PDFyeogeoAún no hay calificaciones
- Programa de Pasantes de La EscuelaDocumento15 páginasPrograma de Pasantes de La EscuelaMöntszë TяejoAún no hay calificaciones
- El rey solitario encuentra el amorDocumento5 páginasEl rey solitario encuentra el amorDidiexy HenriquezAún no hay calificaciones
- Enseñanza de números dígitos preescolar indígenaDocumento64 páginasEnseñanza de números dígitos preescolar indígenaBrujaLizRamírez100% (1)
- Componentes de La Inteligencia SocialDocumento8 páginasComponentes de La Inteligencia SocialDoris GarciaAún no hay calificaciones
- Documento Filosofia de La EducacionDocumento21 páginasDocumento Filosofia de La Educacionvictor manuel diazAún no hay calificaciones
- Gratuidad educación PerúDocumento18 páginasGratuidad educación PerúHelent Quicaño100% (1)
- Registro de La ObservaciónDocumento17 páginasRegistro de La ObservaciónJesus MoraAún no hay calificaciones
- Informe de Primera Jornada de Práctica DocenteDocumento13 páginasInforme de Primera Jornada de Práctica DocenteVeritoAldanaD'GarcíaAún no hay calificaciones
- ANEXO 7aDocumento2 páginasANEXO 7aJenny MejiaAún no hay calificaciones
- Historias de Vida de Estudiantes Universitarios de Origen Indígena (López Gopar, 2016) PDFDocumento160 páginasHistorias de Vida de Estudiantes Universitarios de Origen Indígena (López Gopar, 2016) PDFmarcksmith115100% (1)
- Etica Evaluacion Primer PeriodoDocumento3 páginasEtica Evaluacion Primer PeriodoMichael KelleyAún no hay calificaciones
- 3 Tercer Trimestre 1 AñoDocumento2 páginas3 Tercer Trimestre 1 AñogabrielAún no hay calificaciones
- William Sidis, un niño superdotado con una vida trágicaDocumento3 páginasWilliam Sidis, un niño superdotado con una vida trágicajoashassanAún no hay calificaciones
- Secuencia didáctica sobre magnitudes y unidades en CienciasDocumento4 páginasSecuencia didáctica sobre magnitudes y unidades en CienciasSusana BengoaAún no hay calificaciones
- Colegio Nacional General Píntag: Oficios circulares 2015-2016Documento5 páginasColegio Nacional General Píntag: Oficios circulares 2015-2016MauricioBetancourtAún no hay calificaciones
- Guion Plan de ConvivenciaDocumento6 páginasGuion Plan de ConvivenciaAnamari0% (1)
- Unidad Didactica Los Seres VivosDocumento3 páginasUnidad Didactica Los Seres VivosJhon Jairo Obando GalvisAún no hay calificaciones
- Textos ExpositivosDocumento4 páginasTextos ExpositivosHumberto0% (1)
- Cuaderno ExpomatDocumento90 páginasCuaderno ExpomatMaribel Magnolia Saldaña QuenayaAún no hay calificaciones
- Presentación Bateria de OperariosDocumento7 páginasPresentación Bateria de OperariosEspinoza Alejandra100% (1)
- "Los Hijos de La Nieve" Sobre La Comunidad Callaquí Del Alto Bio Bio en La Cordillera ChilenaDocumento4 páginas"Los Hijos de La Nieve" Sobre La Comunidad Callaquí Del Alto Bio Bio en La Cordillera ChilenaMónica Morello100% (1)