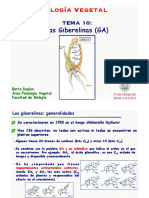
También podría gustarte
- Analisis SecuenciasDocumento20 páginasAnalisis Secuenciasleomcm83Aún no hay calificaciones
- Bases de Machine LearningDocumento26 páginasBases de Machine LearningAndres MejiaAún no hay calificaciones
- Algoritmos Entrenamiento-IADocumento3 páginasAlgoritmos Entrenamiento-IAJofre ErnestoAún no hay calificaciones
- Tema2 Aln Pareados y BLASTDocumento20 páginasTema2 Aln Pareados y BLASTJames ReinaAún no hay calificaciones
- Plantilla S8Documento8 páginasPlantilla S8jkuanAún no hay calificaciones
- Alineacion 2013 Vers CortaDocumento31 páginasAlineacion 2013 Vers CortafaustohernanAún no hay calificaciones
- Sintesis de Secuencia de SeparacionDocumento6 páginasSintesis de Secuencia de Separacionampere123Aún no hay calificaciones
- Alineamiento Multiple T-CoffeeDocumento7 páginasAlineamiento Multiple T-CoffeeGabby GonzálezAún no hay calificaciones
- Algoritmos de Maximizacion de EsperanzaDocumento29 páginasAlgoritmos de Maximizacion de EsperanzaCarolina AravenaAún no hay calificaciones
- Alineamiento pareado de secuenciasDocumento36 páginasAlineamiento pareado de secuenciasOrlando SevillanoAún no hay calificaciones
- Estudio de CasoDocumento15 páginasEstudio de CasoJesus SotoAún no hay calificaciones
- Alineamiento Multiple T-CoffeeDocumento7 páginasAlineamiento Multiple T-CoffeeGabby GonzálezAún no hay calificaciones
- Bioinformatica TeoriaDocumento65 páginasBioinformatica TeoriaFAUSTO GABRIEL YEPEZ CALDERONAún no hay calificaciones
- MetaheuristicaDocumento13 páginasMetaheuristicaEstebanAún no hay calificaciones
- Exposicion Metodos de Clasificacion y Prediccion RDocumento48 páginasExposicion Metodos de Clasificacion y Prediccion RJesus Alberto Quishpe GrandaAún no hay calificaciones
- Identificación de sistemas dinámicos mediante MatLABDocumento15 páginasIdentificación de sistemas dinámicos mediante MatLABMiguel RodriguezAún no hay calificaciones
- 3 +preprocesamiento+de+datos+ (Pres)Documento42 páginas3 +preprocesamiento+de+datos+ (Pres)Jonathan ProcelAún no hay calificaciones
- Metodos de EsembleDocumento78 páginasMetodos de EsembleRobert SinsAún no hay calificaciones
- Alinaneamientos MultiplesDocumento2 páginasAlinaneamientos MultiplesAndy JavierAún no hay calificaciones
- Análisis Cluster Con SPSSDocumento17 páginasAnálisis Cluster Con SPSSpepelu2Aún no hay calificaciones
- Evaluación de Algoritmos SupervisadosDocumento5 páginasEvaluación de Algoritmos SupervisadosSandra Patricia BarretoAún no hay calificaciones
- Unidad 4Documento31 páginasUnidad 4Javier MnAún no hay calificaciones
- Algoritmo GeneticoDocumento19 páginasAlgoritmo GeneticoPitter PastorAún no hay calificaciones
- K-Means ResumenDocumento2 páginasK-Means ResumenWillian VargasAún no hay calificaciones
- JasonChanchay Deber3Documento4 páginasJasonChanchay Deber3ANA PATRICIA TACOAún no hay calificaciones
- Lab11 Quinga Sango Soria Tello Rapidminner TemplateDocumento16 páginasLab11 Quinga Sango Soria Tello Rapidminner TemplateFran SoriaAún no hay calificaciones
- Herramientas InformáticasDocumento20 páginasHerramientas InformáticasLetty EAún no hay calificaciones
- Lab Alineamiento de Secuencias - Arboles DistanciaDocumento3 páginasLab Alineamiento de Secuencias - Arboles DistanciaElizaAún no hay calificaciones
- Reglas y BúsquedaDocumento42 páginasReglas y BúsquedaAry Chan0% (1)
- SFSFDSFDocumento22 páginasSFSFDSFEDISSON ANDRES VILLA AVILAAún no hay calificaciones
- dm4 PDFDocumento36 páginasdm4 PDFPablo Esau Mejia MedinaAún no hay calificaciones
- Diferencias Entre MUSCLEDocumento2 páginasDiferencias Entre MUSCLEAnn AguirreAún no hay calificaciones
- Cómo Se Elabora El ClusteringDocumento3 páginasCómo Se Elabora El ClusteringrojasperezjoaquinliAún no hay calificaciones
- Blast NcbiDocumento6 páginasBlast NcbimarioaAún no hay calificaciones
- Unidad1 AnálisisdeSecuencias ADocumento59 páginasUnidad1 AnálisisdeSecuencias AMicaela AvacaAún no hay calificaciones
- Diapos BioinformaticaDocumento171 páginasDiapos BioinformaticaJenny S-boomAún no hay calificaciones
- Analisis de Cluster Con SPSSDocumento29 páginasAnalisis de Cluster Con SPSSEvelyn GutierrezAún no hay calificaciones
- Algoritmos de planificación del procesadorDocumento6 páginasAlgoritmos de planificación del procesadorshioky coomerAún no hay calificaciones
- Estudio de Caso - U4-Soto - JesusDocumento16 páginasEstudio de Caso - U4-Soto - JesusJesus SotoAún no hay calificaciones
- Resumen de HenleyDocumento3 páginasResumen de HenleyGiovanni MuñozAún no hay calificaciones
- Ensayo Improved Tools For Biological Sequence ComparisonDocumento2 páginasEnsayo Improved Tools For Biological Sequence ComparisonJacqueline Rodríguez QuijanoAún no hay calificaciones
- Resumen Del Apunte de Curso - 10 Introducción A Machine LearningDocumento5 páginasResumen Del Apunte de Curso - 10 Introducción A Machine LearningSpaceGemAún no hay calificaciones
- LB PDFDocumento15 páginasLB PDFLaura CruzAún no hay calificaciones
- 01 Análisis de OutliersDocumento33 páginas01 Análisis de OutliersCarlos CarmonaAún no hay calificaciones
- Preguntas FinalDocumento25 páginasPreguntas FinalFelipe Fernández Hernando de LarramendiAún no hay calificaciones
- Wuolah Free App 1706189836558 Gulag FreeDocumento8 páginasWuolah Free App 1706189836558 Gulag Freejaja jajaAún no hay calificaciones
- Mineria de DatosDocumento8 páginasMineria de DatosNicole VargasAún no hay calificaciones
- Arboles FilogeneticosDocumento14 páginasArboles FilogeneticosTatiana RiveraAún no hay calificaciones
- Monitoreo de Espacio en Disco Duro en MysqlDocumento9 páginasMonitoreo de Espacio en Disco Duro en MysqlCarlos CortésAún no hay calificaciones
- Tesis en IQ 2 - 2022-2Documento20 páginasTesis en IQ 2 - 2022-2Franco Camacho CanchariAún no hay calificaciones
- Modelo de Clasificacion 1Documento8 páginasModelo de Clasificacion 1Miguel HerreraAún no hay calificaciones
- Cim 2000Documento30 páginasCim 2000Diego Alejandro Ledesma FloresAún no hay calificaciones
- Resumen Tesis TDocumento6 páginasResumen Tesis TEdwin HidalgoAún no hay calificaciones
- Examen Parcial - Seccion1Documento4 páginasExamen Parcial - Seccion1Miguel Angel Alvarado RamosAún no hay calificaciones
- Laboratorio MrBayes 2020-2Documento11 páginasLaboratorio MrBayes 2020-2Harold RiveraAún no hay calificaciones
- Tecnicas de Clustering en Machine LearningDocumento12 páginasTecnicas de Clustering en Machine LearningFernan FortichAún no hay calificaciones
- Aprendizaje SupervisadoDocumento9 páginasAprendizaje SupervisadoLeonil MartínezAún no hay calificaciones
- Introducción a los Algoritmos y las Estructuras de Datos 3: Introducción a los Algoritmos y las Estructuras de Datos, #3De EverandIntroducción a los Algoritmos y las Estructuras de Datos 3: Introducción a los Algoritmos y las Estructuras de Datos, #3Aún no hay calificaciones
- Álgebra abstracta aplicada en ingeniería: casos de aplicación en sistemas difusos tipo 1 y tipo 2De EverandÁlgebra abstracta aplicada en ingeniería: casos de aplicación en sistemas difusos tipo 1 y tipo 2Aún no hay calificaciones
- Tema 4 CompletoDocumento2 páginasTema 4 CompletoAnaAún no hay calificaciones
- Qui MicaDocumento6 páginasQui MicaAna Lopez GarciaAún no hay calificaciones
- Manual Básico de Nutrición Clínica y Dietética - BorrasDocumento312 páginasManual Básico de Nutrición Clínica y Dietética - BorrasGiovanna Gomez Cervantes96% (24)
- Bifidus, Algo Más Que Una ModaDocumento3 páginasBifidus, Algo Más Que Una ModaAnaAún no hay calificaciones
- Guia de Alimentacion y Salud - DeporteDocumento20 páginasGuia de Alimentacion y Salud - DeporteJulieth PMAún no hay calificaciones
- Informe Practicas VacunasDocumento2 páginasInforme Practicas VacunasAnaAún no hay calificaciones
- Consulta de dietética y nutriciónDocumento27 páginasConsulta de dietética y nutriciónLuis López100% (1)
- Plan LaboratorioDocumento84 páginasPlan LaboratorioAnaAún no hay calificaciones
- Biofarmacos en EspanaDocumento11 páginasBiofarmacos en EspanaAnaAún no hay calificaciones
- Figuras 10. GiberelinasDocumento31 páginasFiguras 10. GiberelinasAnaAún no hay calificaciones
- Emprender FácilDocumento2 páginasEmprender FácilAnaAún no hay calificaciones
- Reparto AlimentosDocumento2 páginasReparto AlimentosAnaAún no hay calificaciones
- 02 Figuras 02. Agua y Ce LulasDocumento16 páginas02 Figuras 02. Agua y Ce LulasAnaAún no hay calificaciones
- Figuras 05. DesarrolloDocumento35 páginasFiguras 05. DesarrolloAnaAún no hay calificaciones
- Bioquímica problemas y cuestiones tema 1Documento2 páginasBioquímica problemas y cuestiones tema 1Ana0% (1)
- Ingeniería GenéticaDocumento35 páginasIngeniería GenéticaAnaAún no hay calificaciones
- BasePizza AtunDocumento1 páginaBasePizza AtunAnaAún no hay calificaciones
- 7 Habitos de La Gente Altamente Efectiva - Stephen R Covey PDFDocumento5 páginas7 Habitos de La Gente Altamente Efectiva - Stephen R Covey PDFKatia Leite100% (3)
- 2014 Tema 1Documento116 páginas2014 Tema 1AnaAún no hay calificaciones
- CitometríaDocumento4 páginasCitometríaAnaAún no hay calificaciones
- Ingenieria Genetica PDF Modificacion de Los Genes para Su EstudioDocumento29 páginasIngenieria Genetica PDF Modificacion de Los Genes para Su EstudioAnaAún no hay calificaciones
- Articulo 2.en - EsDocumento24 páginasArticulo 2.en - EsEtson Edu Alarcon AlarconAún no hay calificaciones
- Análisis de MarkovDocumento51 páginasAnálisis de MarkovPerla_Celeste__754886% (7)
- Articulo 03 Reconocimiento de Voz Con Redes Neuronales DTW y MOMDocumento6 páginasArticulo 03 Reconocimiento de Voz Con Redes Neuronales DTW y MOMPedro BeltranAún no hay calificaciones
- Modelos ocultos de Markov para perfiles de familias de secuenciasDocumento10 páginasModelos ocultos de Markov para perfiles de familias de secuenciasPablo LuceroAún no hay calificaciones
- PFC - HMM y Algoritmo EMDocumento132 páginasPFC - HMM y Algoritmo EMAndrés Mauricio Barragán SarmientoAún no hay calificaciones
- Reconocimiento de Voz-AplicacionesDocumento15 páginasReconocimiento de Voz-AplicacionesBruno LeppeAún no hay calificaciones
- 76ac-2 en EsDocumento11 páginas76ac-2 en EsANDRES DAVID DOMINGUEZ ROZOAún no hay calificaciones
- Reconocimiento de Voz en La EducaciónDocumento18 páginasReconocimiento de Voz en La EducaciónIvan PortillaAún no hay calificaciones
- GurlekianProtocolopericiasforensesdevoz v2.0Documento14 páginasGurlekianProtocolopericiasforensesdevoz v2.0fabianaAún no hay calificaciones
- DeteccionPeatonesVisInfrarrojoDocumento245 páginasDeteccionPeatonesVisInfrarrojoFrancisco Rodriguez MartinezAún no hay calificaciones
- Cadena de MarkovDocumento5 páginasCadena de MarkovSergio Ochoa100% (1)
- Articulo OperacionesDocumento9 páginasArticulo OperacionesDanielaAndreaRoldanAún no hay calificaciones
- Ilovepdf MergedDocumento52 páginasIlovepdf MergedJimmyJoelMillaMartinezAún no hay calificaciones
- Modelos de Normalizacion de Direcciones PDFDocumento4 páginasModelos de Normalizacion de Direcciones PDFApril EatonAún no hay calificaciones
- Cadenas Ocultas de MarkovDocumento13 páginasCadenas Ocultas de MarkovCeli JL0% (1)
- II Alineacion de Secuencias - Oliva Ramirez LuisgDocumento44 páginasII Alineacion de Secuencias - Oliva Ramirez LuisgLuis Gerardo OlivaAún no hay calificaciones
- GurlekianProtocolopericiasforensesdevoz v2.0Documento14 páginasGurlekianProtocolopericiasforensesdevoz v2.0César Eduardo Ramos RivasAún no hay calificaciones
- Control de equipo de sonido por vozDocumento127 páginasControl de equipo de sonido por vozAlexisEnrriqueLopezOrtizAún no hay calificaciones
- Cap2: Un Vistazo A La Teoría de Reconocimientos de Patrones.Documento26 páginasCap2: Un Vistazo A La Teoría de Reconocimientos de Patrones.DANAún no hay calificaciones
- Analisis de MarkovDocumento47 páginasAnalisis de MarkovChristian LeónAún no hay calificaciones
- MsaDocumento78 páginasMsaAnaAún no hay calificaciones
- PLN 53 PDFDocumento216 páginasPLN 53 PDFricky10000Aún no hay calificaciones
- Ecuaciones Diferenciales en La Ingeniería en ComputaciónDocumento6 páginasEcuaciones Diferenciales en La Ingeniería en ComputaciónUlises Landázuri Brambila0% (1)
- Modelos de Markov CMDocumento47 páginasModelos de Markov CMALBERTO MOLINA FELIPEAún no hay calificaciones
- Cadenas de Markov OcultasDocumento11 páginasCadenas de Markov OcultasRodney CamiloAún no hay calificaciones
- Introduccion Al Modelo Oculto de Markov - Luis BergasaDocumento25 páginasIntroduccion Al Modelo Oculto de Markov - Luis BergasaAdmón de EmpresasAún no hay calificaciones
- Detection of Epileptic Seizure Using Accelerometer Time Series Data and Hidden Markov Model - En.esDocumento4 páginasDetection of Epileptic Seizure Using Accelerometer Time Series Data and Hidden Markov Model - En.esMiguel PalacioAún no hay calificaciones
- Inteligencia ArtificialDocumento64 páginasInteligencia ArtificialLuis Ricardo Chávez AliagaAún no hay calificaciones
- Vsip - Info Pln53pdf PDF FreeDocumento216 páginasVsip - Info Pln53pdf PDF FreeJulián Emiliano EscalanteAún no hay calificaciones