También podría gustarte
- Prueba de Bondad de AjusteDocumento19 páginasPrueba de Bondad de AjusteEdsson MendezAún no hay calificaciones
- Solucion A Ejercicio 1.1Documento58 páginasSolucion A Ejercicio 1.1Ssj IngJuan Diego Quishpi LuceroAún no hay calificaciones
- Econometría I Vega Baque Betsy Lisbeth MA6-2Documento13 páginasEconometría I Vega Baque Betsy Lisbeth MA6-2Viviana VasquezAún no hay calificaciones
- Normalidad 1Documento6 páginasNormalidad 1Sergio Alejandro FuentealbaAún no hay calificaciones
- Reporte de LaboratorioDocumento8 páginasReporte de LaboratoriocarlaAún no hay calificaciones
- Investigación EstadisticaDocumento9 páginasInvestigación Estadisticairanis bravoAún no hay calificaciones
- Medidas de Dispersión Empleando ExcelDocumento25 páginasMedidas de Dispersión Empleando ExcelPatricio SaucedaAún no hay calificaciones
- Entrega 1 Estadistica Inferencial OkDocumento14 páginasEntrega 1 Estadistica Inferencial Oksebatian chavarriaAún no hay calificaciones
- Gars S4a4Documento8 páginasGars S4a4Gabriel Rodriguez SantyagoAún no hay calificaciones
- Lección 4 - Probabilidad y Estadística - 1Documento14 páginasLección 4 - Probabilidad y Estadística - 1Edison CastilloAún no hay calificaciones
- Chi Cuadrado Orquidea FinalDocumento8 páginasChi Cuadrado Orquidea FinalOrquidea Vallejo peñaAún no hay calificaciones
- 10.8 - Prueba de Bondad de AjusteDocumento8 páginas10.8 - Prueba de Bondad de AjusteRaulOliverRuizAún no hay calificaciones
- Trabajo Colaborativo Estadística InferencialDocumento15 páginasTrabajo Colaborativo Estadística Inferenciallayne padilla100% (1)
- 01 Muestreo1Documento221 páginas01 Muestreo1Slavenko AndreAún no hay calificaciones
- EstadísticaDocumento24 páginasEstadísticaHarold Gamarra EchevarriaAún no hay calificaciones
- Practica6g PDFDocumento12 páginasPractica6g PDFRamon Antonio Jimenez-zarzaAún no hay calificaciones
- EstadisticaDocumento11 páginasEstadisticaLuis ArenasAún no hay calificaciones
- Pruebas No ParametricasDocumento11 páginasPruebas No Parametricaswilliam LibreAún no hay calificaciones
- Desarrollo de Los Estadísticos Trabajados en ClaseDocumento9 páginasDesarrollo de Los Estadísticos Trabajados en ClaseSantiago OtaloraAún no hay calificaciones
- 1.7 y 1.8 Proceso AdministrativoDocumento9 páginas1.7 y 1.8 Proceso AdministrativoYasser GomezAún no hay calificaciones
- Analisis de ReplicasDocumento25 páginasAnalisis de Replicaslitow810Aún no hay calificaciones
- Guía No 5 - Datos AgrupadosDocumento7 páginasGuía No 5 - Datos AgrupadosceciliaAún no hay calificaciones
- VARIABILIDADDocumento35 páginasVARIABILIDADnicolas dionisio ordonez barrueta100% (1)
- Prueba de NormalidadDocumento5 páginasPrueba de NormalidadCarlo André Morales ValderramaAún no hay calificaciones
- Diapositivas de Estadistica No ParametricaDocumento33 páginasDiapositivas de Estadistica No ParametricaCARLOS DANIEL LOPEZ PEREZAún no hay calificaciones
- Medidas de Variacion o DispersionDocumento15 páginasMedidas de Variacion o DispersionJennyfer Ventocilla ZapataAún no hay calificaciones
- Estadistica Descriptiva ImprimirDocumento41 páginasEstadistica Descriptiva ImprimirJulio Cesar Romero SanchezAún no hay calificaciones
- IntroEstadistica CON GEOGEBRADocumento65 páginasIntroEstadistica CON GEOGEBRAjanicharAún no hay calificaciones
- CuartaDocumento39 páginasCuartaMauricio Andres Mongui MolinaAún no hay calificaciones
- Guía de Matemáticas - Estadísticas - 5to AñoDocumento14 páginasGuía de Matemáticas - Estadísticas - 5to AñoLauAún no hay calificaciones
- Prueba Chi CuadradoDocumento18 páginasPrueba Chi CuadradoCoronadoMartinAún no hay calificaciones
- Desarrollo de Los Estadísticos Trabajados en ClaseDocumento10 páginasDesarrollo de Los Estadísticos Trabajados en ClaseSantiago OtaloraAún no hay calificaciones
- Distribuciones MuestralesDocumento8 páginasDistribuciones MuestralesAlex Javier CajamarcaAún no hay calificaciones
- Leccion 26Documento34 páginasLeccion 26pipiu2Aún no hay calificaciones
- Medidas de DispersionDocumento10 páginasMedidas de DispersionEliza MartinezAún no hay calificaciones
- EXCEL en Química AnalíticaDocumento47 páginasEXCEL en Química AnalíticaJuan Cho100% (1)
- Análisis del flujo vehicular en la intersección de la Av. Armendáriz con la Vía Expresa en BarrancoDocumento36 páginasAnálisis del flujo vehicular en la intersección de la Av. Armendáriz con la Vía Expresa en BarrancoYuber FloresAún no hay calificaciones
- Desviación MediaDocumento7 páginasDesviación MediaEmerson Emilio Chuy SequenAún no hay calificaciones
- Estadisticas Grupo N°2Documento47 páginasEstadisticas Grupo N°2Sandy ParralesAún no hay calificaciones
- Unidad 2. Analisis Descriptivo de DatosDocumento43 páginasUnidad 2. Analisis Descriptivo de DatosjennifertellomAún no hay calificaciones
- Prueba de Anderson DarlingDocumento5 páginasPrueba de Anderson Darlingb4tipibeAún no hay calificaciones
- Tablas de frecuencia: organizar y analizar datosDocumento8 páginasTablas de frecuencia: organizar y analizar datosNatalieMGuerrero100% (1)
- Medidas de DispersionDocumento38 páginasMedidas de Dispersioncarolh2009Aún no hay calificaciones
- Tarea de EstadisticaDocumento7 páginasTarea de EstadisticaCarlos RiveraAún no hay calificaciones
- Estadística Semanal 4Documento7 páginasEstadística Semanal 4Carlos RiveraAún no hay calificaciones
- Probabilidad y Estadistica BásicaDocumento8 páginasProbabilidad y Estadistica BásicaIvon GAún no hay calificaciones
- Investigación 2Documento9 páginasInvestigación 2Yohan MorontaAún no hay calificaciones
- Informe Laboratorio #1Documento11 páginasInforme Laboratorio #1Julio Caroca VenegasAún no hay calificaciones
- Laboratorio n1 - Estadistica InferencialDocumento24 páginasLaboratorio n1 - Estadistica InferencialPaula Mariana MurilloAún no hay calificaciones
- Bondad de Ajuste StatgraphicsDocumento11 páginasBondad de Ajuste StatgraphicsCarlos BetancourtAún no hay calificaciones
- Histogramas y Distribuciones EmpíricasDocumento23 páginasHistogramas y Distribuciones EmpíricasAlonzo Alvarado LaraAún no hay calificaciones
- Medidas de Dispersión para Variables DiscretasDocumento5 páginasMedidas de Dispersión para Variables DiscretasAngelicaFeriaAún no hay calificaciones
- Histograma de resistencia al esfuerzo cortante de soldaduras ultrasonicasDocumento7 páginasHistograma de resistencia al esfuerzo cortante de soldaduras ultrasonicasMascalardoAún no hay calificaciones
- Distribución Chi cuadrada y prueba Ji-cuadradoDocumento18 páginasDistribución Chi cuadrada y prueba Ji-cuadradoEl MarcAún no hay calificaciones
- Estadistica Lectura CDocumento14 páginasEstadistica Lectura CAnna DavalosAún no hay calificaciones
- Elementos de estadística para ingeniería: Un curso básicoDe EverandElementos de estadística para ingeniería: Un curso básicoAún no hay calificaciones
- Probabilidad y estadística: un enfoque teórico-prácticoDe EverandProbabilidad y estadística: un enfoque teórico-prácticoCalificación: 4 de 5 estrellas4/5 (40)
- 09 Clase06 FIUBA Flexion Parte1 2013 PDFDocumento17 páginas09 Clase06 FIUBA Flexion Parte1 2013 PDFAnonymous mnyCjzP5Aún no hay calificaciones
- Laboratorio NDocumento4 páginasLaboratorio NStefaniaPerelsteinAún no hay calificaciones
- Resumen de Derecho AmbientalDocumento3 páginasResumen de Derecho AmbientalStefaniaPerelsteinAún no hay calificaciones
- Santiago CalatravaDocumento3 páginasSantiago CalatravaStefaniaPerelsteinAún no hay calificaciones
- 1 Requisitos GeneralesDocumento14 páginas1 Requisitos GeneralesMaria Cecilia Suarez RubiAún no hay calificaciones
- Supuestos Básicos Naturaleza HumanaDocumento20 páginasSupuestos Básicos Naturaleza HumanaStefaniaPerelsteinAún no hay calificaciones
- Pilot EsDocumento8 páginasPilot EsJuan Jose Bonilla RAún no hay calificaciones
- Instalaciones eléctricas en inmuebles AEA 90364Documento10 páginasInstalaciones eléctricas en inmuebles AEA 90364Luis OrdoñezAún no hay calificaciones
- Quadri Instalaciones Electricas en Edificios PDFDocumento176 páginasQuadri Instalaciones Electricas en Edificios PDFStefaniaPerelsteinAún no hay calificaciones
- La MotivaciónDocumento17 páginasLa MotivaciónStefaniaPerelsteinAún no hay calificaciones
- Guía de problemas de magnetismoDocumento2 páginasGuía de problemas de magnetismoStefaniaPerelsteinAún no hay calificaciones
- 1 Requisitos GeneralesDocumento14 páginas1 Requisitos GeneralesMaria Cecilia Suarez RubiAún no hay calificaciones
- Presas de TierraDocumento19 páginasPresas de TierraStefaniaPerelsteinAún no hay calificaciones
- Apunte General de CAD 2015Documento18 páginasApunte General de CAD 2015StefaniaPerelsteinAún no hay calificaciones
- Relaciones LaboralesDocumento7 páginasRelaciones LaboralesStefaniaPerelsteinAún no hay calificaciones
- Relaciones LaboralesDocumento6 páginasRelaciones LaboralesStefaniaPerelsteinAún no hay calificaciones
- Descripción Proceso de PotabilizaciónDocumento2 páginasDescripción Proceso de PotabilizaciónStefaniaPerelsteinAún no hay calificaciones
- Presas de TierraDocumento19 páginasPresas de TierraStefaniaPerelsteinAún no hay calificaciones
- TP 1 Ing - CivilDocumento8 páginasTP 1 Ing - CivilStefaniaPerelsteinAún no hay calificaciones
- Excel 2 EpitaDocumento2 páginasExcel 2 EpitaStefaniaPerelsteinAún no hay calificaciones
- Aislador Antisismico Prospect Reston Pendulum Int EsDocumento4 páginasAislador Antisismico Prospect Reston Pendulum Int EsStefaniaPerelsteinAún no hay calificaciones
- La Navegacion Fluvial en El Mundo - 1Documento54 páginasLa Navegacion Fluvial en El Mundo - 1StefaniaPerelstein100% (1)
- ProyectoDocumento4 páginasProyectoStefaniaPerelsteinAún no hay calificaciones
- II JoREIC Región Este - ConcordiaDocumento15 páginasII JoREIC Región Este - ConcordiaStefaniaPerelsteinAún no hay calificaciones
- Apunte Diseño1de Canales de NavegacionDocumento35 páginasApunte Diseño1de Canales de NavegacionStefaniaPerelsteinAún no hay calificaciones
- Bolilla 1Documento5 páginasBolilla 1StefaniaPerelsteinAún no hay calificaciones
- Trabajo Integrador FinalDocumento32 páginasTrabajo Integrador FinalStefaniaPerelsteinAún no hay calificaciones
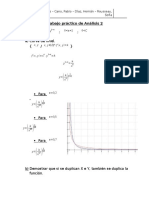
- Trabajo Práctico de Análisis 2Documento3 páginasTrabajo Práctico de Análisis 2StefaniaPerelsteinAún no hay calificaciones
- Desagües CloacalesDocumento11 páginasDesagües CloacalesStefaniaPerelsteinAún no hay calificaciones
- TP Cornu AmiiDocumento3 páginasTP Cornu AmiiStefaniaPerelsteinAún no hay calificaciones
- Taller Modelos Discretos (Luis Jimenez, Noel Neira)Documento13 páginasTaller Modelos Discretos (Luis Jimenez, Noel Neira)Lucho JimenezAún no hay calificaciones
- Ejemplo Desestacionalizacion de La DemandaDocumento41 páginasEjemplo Desestacionalizacion de La DemandaJavier VilluendasAún no hay calificaciones
- Texto UniversitarioDocumento270 páginasTexto UniversitarioKevin MendozaAún no hay calificaciones
- Plan de Trabajo Gestión Logística 1792945Documento12 páginasPlan de Trabajo Gestión Logística 1792945nathalia santamariaAún no hay calificaciones
- Ejercicios EstadisticaDocumento6 páginasEjercicios Estadisticaleidy castañoAún no hay calificaciones
- Taller 2 Variable Aleatoria Casi CompletoDocumento5 páginasTaller 2 Variable Aleatoria Casi CompletoalexAún no hay calificaciones
- 3ra ProbabilidadesDocumento22 páginas3ra ProbabilidadesDanielDanielCastroFernandezAún no hay calificaciones
- Ejercicios1 2 3 4 5Documento8 páginasEjercicios1 2 3 4 5MasheAún no hay calificaciones
- Pruebas estadísticas para validar números pseudoaleatorios en simulaciónDocumento48 páginasPruebas estadísticas para validar números pseudoaleatorios en simulaciónErick RodriguezAún no hay calificaciones
- Práctica 2.1Documento4 páginasPráctica 2.1B EAún no hay calificaciones
- Formulas de Probabilidad y Estadística UAMDocumento6 páginasFormulas de Probabilidad y Estadística UAMNatalia Pinto EstebanAún no hay calificaciones
- Ejercicios Administracion deDocumento3 páginasEjercicios Administracion deMelannye MartinezAún no hay calificaciones
- ProblemasDocumento32 páginasProblemasElmer Llagas Casas33% (3)
- Programa PRN-215 2018 PDFDocumento3 páginasPrograma PRN-215 2018 PDFRoberto Carlos HernandezAún no hay calificaciones
- Aula Matlab 2Documento81 páginasAula Matlab 2Analista Jeanka RojasAún no hay calificaciones
- Mapa de TelarañaDocumento1 páginaMapa de Telarañacomando2009Aún no hay calificaciones
- FASE 4 - Trabajo GrupalDocumento99 páginasFASE 4 - Trabajo Grupalkaren natalia pulido rodriguezAún no hay calificaciones
- Formulario de DistribucionesDocumento3 páginasFormulario de DistribucionesALVARO TOCO TOACAAún no hay calificaciones
- Ejercicios Individuales 4Documento8 páginasEjercicios Individuales 4yesica lopez contrerasAún no hay calificaciones
- 2 - 3 - Ejercicio1 Promedio MovilDocumento14 páginas2 - 3 - Ejercicio1 Promedio MovilShermie LeidyAún no hay calificaciones
- Ejercicios Espacio de EstadoDocumento7 páginasEjercicios Espacio de EstadoJonathan ArauzAún no hay calificaciones
- Unidad 1 - Tarea 2 - Diseño de AutómatasDocumento11 páginasUnidad 1 - Tarea 2 - Diseño de AutómatasElisa Maria Plazas Figueroa0% (1)
- Tarea Modulo 6Documento6 páginasTarea Modulo 6Oscar Guillermo Segura100% (1)
- Programa Estadistica InferencialDocumento4 páginasPrograma Estadistica InferencialJamith De RansAún no hay calificaciones
- Examen de Probabilidades 1Documento1 páginaExamen de Probabilidades 1César CAAún no hay calificaciones
- Variable AleatoriaDocumento12 páginasVariable AleatoriaisaacjmAún no hay calificaciones
- Estadística y probabilidad - Fase 4 discusiónDocumento81 páginasEstadística y probabilidad - Fase 4 discusiónLiz BettinAún no hay calificaciones
- Distribuciones de Probabilidad DiscretasDocumento78 páginasDistribuciones de Probabilidad DiscretasEnrique MejiaAún no hay calificaciones
- Tema 2 Promedios Móviles, Suavizamiento Exponencial Simple y Evaluación de Métodos de Pronósticos. Mario LesmezDocumento7 páginasTema 2 Promedios Móviles, Suavizamiento Exponencial Simple y Evaluación de Métodos de Pronósticos. Mario LesmezAlejandro LesmesAún no hay calificaciones