También podría gustarte
- The Yellow House: A Memoir (2019 National Book Award Winner)De EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Calificación: 4 de 5 estrellas4/5 (98)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceCalificación: 4 de 5 estrellas4/5 (895)
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeCalificación: 4 de 5 estrellas4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe EverandThe Little Book of Hygge: Danish Secrets to Happy LivingCalificación: 3.5 de 5 estrellas3.5/5 (399)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaCalificación: 4.5 de 5 estrellas4.5/5 (266)
- Shoe Dog: A Memoir by the Creator of NikeDe EverandShoe Dog: A Memoir by the Creator of NikeCalificación: 4.5 de 5 estrellas4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureCalificación: 4.5 de 5 estrellas4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe EverandNever Split the Difference: Negotiating As If Your Life Depended On ItCalificación: 4.5 de 5 estrellas4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe EverandGrit: The Power of Passion and PerseveranceCalificación: 4 de 5 estrellas4/5 (588)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryCalificación: 3.5 de 5 estrellas3.5/5 (231)
- The Emperor of All Maladies: A Biography of CancerDe EverandThe Emperor of All Maladies: A Biography of CancerCalificación: 4.5 de 5 estrellas4.5/5 (271)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyCalificación: 3.5 de 5 estrellas3.5/5 (2259)
- On Fire: The (Burning) Case for a Green New DealDe EverandOn Fire: The (Burning) Case for a Green New DealCalificación: 4 de 5 estrellas4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersCalificación: 4.5 de 5 estrellas4.5/5 (344)
- Rise of ISIS: A Threat We Can't IgnoreDe EverandRise of ISIS: A Threat We Can't IgnoreCalificación: 3.5 de 5 estrellas3.5/5 (137)
- Team of Rivals: The Political Genius of Abraham LincolnDe EverandTeam of Rivals: The Political Genius of Abraham LincolnCalificación: 4.5 de 5 estrellas4.5/5 (234)
- The Unwinding: An Inner History of the New AmericaDe EverandThe Unwinding: An Inner History of the New AmericaCalificación: 4 de 5 estrellas4/5 (45)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreCalificación: 4 de 5 estrellas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Calificación: 4.5 de 5 estrellas4.5/5 (121)
- The Perks of Being a WallflowerDe EverandThe Perks of Being a WallflowerCalificación: 4.5 de 5 estrellas4.5/5 (2102)
- Her Body and Other Parties: StoriesDe EverandHer Body and Other Parties: StoriesCalificación: 4 de 5 estrellas4/5 (821)
- Kepware UCONDocumento154 páginasKepware UCONmichaelliauAún no hay calificaciones
- 4th - Business IntelligenceDocumento30 páginas4th - Business IntelligenceJoyce Gutierrez JulianoAún no hay calificaciones
- SAP R - 3 Performance Monitoring and TuningDocumento12 páginasSAP R - 3 Performance Monitoring and TuningBharath PriyaAún no hay calificaciones
- Data Domain Solutions Design: Downloadable ContentDocumento36 páginasData Domain Solutions Design: Downloadable ContentGreivin ArguedasAún no hay calificaciones
- Cloud StorageDocumento14 páginasCloud StorageAtif AslamAún no hay calificaciones
- SQL Database Connectivity and The Idempotency IssueDocumento5 páginasSQL Database Connectivity and The Idempotency Issueapi-234102930Aún no hay calificaciones
- PrimeFaces Showcase Filedwn1Documento1 páginaPrimeFaces Showcase Filedwn1jbsysatmAún no hay calificaciones
- Venkat Java Projects: - Java Ieee Projects List SN O Project Title DomainDocumento11 páginasVenkat Java Projects: - Java Ieee Projects List SN O Project Title Domainchinnu snehaAún no hay calificaciones
- Notepad++ Searching and ReplacingDocumento9 páginasNotepad++ Searching and ReplacingnoxleekAún no hay calificaciones
- ZyWALL 310 - 2Documento386 páginasZyWALL 310 - 2Phonthep YimsukananAún no hay calificaciones
- WinADCP User GuideDocumento28 páginasWinADCP User Guidejohnniewalker_1Aún no hay calificaciones
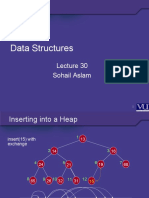
- Data Structures: Sohail AslamDocumento21 páginasData Structures: Sohail AslamM NOOR MALIKAún no hay calificaciones
- Assignment DBMSDocumento8 páginasAssignment DBMSJashanAún no hay calificaciones
- Manual Amt 70 PDFDocumento195 páginasManual Amt 70 PDFHenry SosaAún no hay calificaciones
- ALERT Versions For 4.0Documento2 páginasALERT Versions For 4.0credondo1Aún no hay calificaciones
- Performance Evaluation of BPSK Modulation With Error Control CodingDocumento6 páginasPerformance Evaluation of BPSK Modulation With Error Control CodingSaketh RaviralaAún no hay calificaciones
- HSNDocumento3 páginasHSNAnand RonnieAún no hay calificaciones
- XII - CS - Periodic AssessmentDocumento3 páginasXII - CS - Periodic AssessmentAnbuchelvan VKAún no hay calificaciones
- Active Directory, DNS, DHCP Q & AnsDocumento53 páginasActive Directory, DNS, DHCP Q & AnsSudhir Maherwal100% (3)
- TCP/IP Model PresentationDocumento11 páginasTCP/IP Model PresentationArpitmaan100% (1)
- DBMS Car Rental SystemDocumento15 páginasDBMS Car Rental SystemsxascAún no hay calificaciones
- Hibernate NotesDocumento4 páginasHibernate NotessasirekhaAún no hay calificaciones
- Data Migration Using The Migrate ModuleDocumento20 páginasData Migration Using The Migrate ModuleNitish GuleriaAún no hay calificaciones
- Ost Lab Manual r15Documento53 páginasOst Lab Manual r15chikka2515Aún no hay calificaciones
- DxdiagDocumento25 páginasDxdiagBogdan MaticAún no hay calificaciones
- Dale Carnegie How To Win Friends and Influence PeopleDocumento11 páginasDale Carnegie How To Win Friends and Influence PeopleYash Pandey0% (1)
- Otn AlcatelDocumento36 páginasOtn AlcatelGonzalo Ignacio Lesperguer Diaz0% (1)
- What's New and Changed: Informatica 10.5Documento364 páginasWhat's New and Changed: Informatica 10.5Miu XDAún no hay calificaciones
- Program 6Documento5 páginasProgram 6The Bakchod EngineerAún no hay calificaciones
- Here Is A List of Some Favorite SourcingDocumento7 páginasHere Is A List of Some Favorite SourcingAdnan YousafAún no hay calificaciones