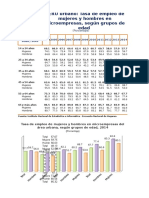
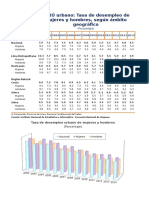
También podría gustarte
- A: José Enrique Velásquez Hurtado Asunto: Referencia: FechaDocumento7 páginasA: José Enrique Velásquez Hurtado Asunto: Referencia: FechaRicardo CordovaAún no hay calificaciones
- Valores InstitucionalesDocumento1 páginaValores InstitucionalesRicardo CordovaAún no hay calificaciones
- Definición de Recursos NecesariosDocumento2 páginasDefinición de Recursos NecesariosRicardo CordovaAún no hay calificaciones
- Orden20 3Documento4 páginasOrden20 3Ricardo CordovaAún no hay calificaciones
- Orden22 2Documento2 páginasOrden22 2Ricardo CordovaAún no hay calificaciones
- Curso de Stata para Economistas 13 PcupDocumento5 páginasCurso de Stata para Economistas 13 PcupRicardo CordovaAún no hay calificaciones
- Mi Parte de ShimaDocumento7 páginasMi Parte de ShimaRicardo CordovaAún no hay calificaciones
- Orden20 3Documento4 páginasOrden20 3Ricardo CordovaAún no hay calificaciones
- Orden19 2Documento4 páginasOrden19 2Ricardo CordovaAún no hay calificaciones
- Orden19 3Documento38 páginasOrden19 3Ricardo CordovaAún no hay calificaciones
- Orden22 2Documento2 páginasOrden22 2Ricardo CordovaAún no hay calificaciones
- Orden21 2Documento6 páginasOrden21 2Ricardo CordovaAún no hay calificaciones
- Orden 26Documento4 páginasOrden 26Ricardo CordovaAún no hay calificaciones
- Orden23 2Documento2 páginasOrden23 2Ricardo CordovaAún no hay calificaciones
- Orden21 2Documento6 páginasOrden21 2Ricardo CordovaAún no hay calificaciones
- Orden1 14Documento2 páginasOrden1 14Ricardo CordovaAún no hay calificaciones
- Orden23 1Documento4 páginasOrden23 1Ricardo CordovaAún no hay calificaciones
- Orden 25Documento2 páginasOrden 25Ricardo CordovaAún no hay calificaciones
- Orden 33Documento4 páginasOrden 33Ricardo CordovaAún no hay calificaciones
- Orden 26Documento4 páginasOrden 26Ricardo CordovaAún no hay calificaciones
- Orden 27Documento4 páginasOrden 27Ricardo CordovaAún no hay calificaciones
- Orden 25Documento2 páginasOrden 25Ricardo CordovaAún no hay calificaciones
- Orden 28Documento10 páginasOrden 28Ricardo CordovaAún no hay calificaciones
- Orden1 15Documento2 páginasOrden1 15Ricardo CordovaAún no hay calificaciones
- Orden 31Documento2 páginasOrden 31Ricardo CordovaAún no hay calificaciones
- Cap 03020Documento2 páginasCap 03020Ricardo CordovaAún no hay calificaciones
- Orden 32Documento2 páginasOrden 32Ricardo CordovaAún no hay calificaciones
- Orden-5 16Documento2 páginasOrden-5 16Ricardo CordovaAún no hay calificaciones
- Orden 1Documento2 páginasOrden 1zoid90Aún no hay calificaciones
- Orden-6 1Documento1 páginaOrden-6 1Dil Nilo Tello AparcoAún no hay calificaciones
- Manual de Millenium Gold OficialDocumento122 páginasManual de Millenium Gold OficialDaniel Valente100% (1)
- Maquinas AsincronasDocumento89 páginasMaquinas AsincronasOmar Alamilla DavilaAún no hay calificaciones
- Ejercicio 1Documento7 páginasEjercicio 1tatiana100% (1)
- Factura 145Documento2 páginasFactura 145AlejandroCavicchioliAún no hay calificaciones
- Bancos Offshore y principales grupos económicos peruanos vinculadosDocumento17 páginasBancos Offshore y principales grupos económicos peruanos vinculadosAle GaRayAún no hay calificaciones
- Cuadro GradualidadDocumento1 páginaCuadro GradualidadLizie Perez TorresAún no hay calificaciones
- Metodos de Mohr y VolhardDocumento4 páginasMetodos de Mohr y VolhardJavier FuenmayorAún no hay calificaciones
- PresupuestoDocumento10 páginasPresupuestoDaviuska RomeroAún no hay calificaciones
- Economías de escala: costos y producciónDocumento2 páginasEconomías de escala: costos y producciónJesus Palma100% (5)
- Requisitos para ingresar al sector público ecuatorianoDocumento1 páginaRequisitos para ingresar al sector público ecuatorianoJairoVsAún no hay calificaciones
- Curriculum Vitae 2018 en LimpioDocumento5 páginasCurriculum Vitae 2018 en Limpiofito2006mqAún no hay calificaciones
- MRPDocumento3 páginasMRPLuis GoveaAún no hay calificaciones
- Ejercicios Gradiente GeometricoDocumento2 páginasEjercicios Gradiente Geometricojonatan100% (2)
- Taller No. 5 - Electronica IIDocumento16 páginasTaller No. 5 - Electronica IIEduardo SandovalAún no hay calificaciones
- Informe Ejecutivo Empresa XYZDocumento6 páginasInforme Ejecutivo Empresa XYZDiego HernandezAún no hay calificaciones
- Problemas Resueltos de Van y TirDocumento6 páginasProblemas Resueltos de Van y TirAnonymous y7iVPcUBAún no hay calificaciones
- Origen de Las EmpresasDocumento2 páginasOrigen de Las EmpresasCalixto Rafael Guevara MedinaAún no hay calificaciones
- Transporte internacional y regulación aduaneraDocumento32 páginasTransporte internacional y regulación aduaneraamanda_requenaAún no hay calificaciones
- Perfeccionamiento de La Gestión de Inventarios Mediante La Aplicación de Modelos Económicos MatemáticosDocumento32 páginasPerfeccionamiento de La Gestión de Inventarios Mediante La Aplicación de Modelos Económicos Matemáticosrodrigosp32Aún no hay calificaciones
- Acta de Otorgamiento de Buena Pro TRANSPORTE - ModificadoDocumento3 páginasActa de Otorgamiento de Buena Pro TRANSPORTE - ModificadoRonyBautistaGAún no hay calificaciones
- Propuesta marketing marisqueríaDocumento33 páginasPropuesta marketing marisqueríaLuis Mantilla Monzón100% (1)
- Control 6 Iacc FinanzasDocumento5 páginasControl 6 Iacc FinanzasCristian Andres Pimentel Mancilla100% (4)
- Analisis de Precios Unitarios 345Documento11 páginasAnalisis de Precios Unitarios 345Anonymous 3TQyQtFCi100% (1)
- ZOFRA TACNAy Zofri2Documento19 páginasZOFRA TACNAy Zofri2Marielita MarielixAún no hay calificaciones
- Cap 5 y 9 Libro Finanzas Corporativas Prof Eduardo CourtDocumento31 páginasCap 5 y 9 Libro Finanzas Corporativas Prof Eduardo CourtRobert Diaz R100% (1)
- Sesion 1 Plan de NegocioDocumento6 páginasSesion 1 Plan de NegocioYahaira BarriosAún no hay calificaciones
- Cotizacion GaspetrolDocumento2 páginasCotizacion GaspetrolKenny MendozaAún no hay calificaciones
- Reglamento de Habilitacion y Construccion Urbana EspecialDocumento4 páginasReglamento de Habilitacion y Construccion Urbana Especialgabita159Aún no hay calificaciones
- Catedra KPMGDocumento70 páginasCatedra KPMGJosue JuarezAún no hay calificaciones
- Bioquímica métodosDocumento47 páginasBioquímica métodosEvelyn Morán NinaAún no hay calificaciones