También podría gustarte
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeDe EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeCalificación: 4 de 5 estrellas4/5 (5794)
- The Little Book of Hygge: Danish Secrets to Happy LivingDe EverandThe Little Book of Hygge: Danish Secrets to Happy LivingCalificación: 3.5 de 5 estrellas3.5/5 (399)
- vb.netDocumento13 páginasvb.netSandeep SheoranAún no hay calificaciones
- Unix 45Documento15 páginasUnix 45Sandeep SheoranAún no hay calificaciones
- August 2010 Bachelor of Computer Application (BCA) - Semester 5 BC0052 - Theory of Computer Science 4 CreditsDocumento6 páginasAugust 2010 Bachelor of Computer Application (BCA) - Semester 5 BC0052 - Theory of Computer Science 4 CreditsSandeep SheoranAún no hay calificaciones
- Assignment Covering Page For TCPDocumento3 páginasAssignment Covering Page For TCPSandeep SheoranAún no hay calificaciones
- SW QualityDocumento14 páginasSW QualitySandeep SheoranAún no hay calificaciones
- BC0050 (Oracle)Documento8 páginasBC0050 (Oracle)Sandeep SheoranAún no hay calificaciones
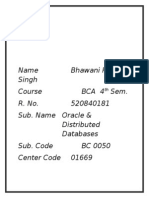
- Name Bhawani Pratap Singh Course Bca 4 Sem. R. No. 520840181 Sub. Name Oracle & Distributed Databases Sub. Code BC 0050 Center Code 01669Documento1 páginaName Bhawani Pratap Singh Course Bca 4 Sem. R. No. 520840181 Sub. Name Oracle & Distributed Databases Sub. Code BC 0050 Center Code 01669Sandeep SheoranAún no hay calificaciones
- BC0051 (Sys Software)Documento10 páginasBC0051 (Sys Software)Sandeep SheoranAún no hay calificaciones
- BC0048 (Computer Networks)Documento19 páginasBC0048 (Computer Networks)Sandeep SheoranAún no hay calificaciones
- BC0047 (Java)Documento8 páginasBC0047 (Java)Sandeep SheoranAún no hay calificaciones
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryDe EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryCalificación: 3.5 de 5 estrellas3.5/5 (231)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceDe EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceCalificación: 4 de 5 estrellas4/5 (894)
- The Yellow House: A Memoir (2019 National Book Award Winner)De EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Calificación: 4 de 5 estrellas4/5 (98)
- Shoe Dog: A Memoir by the Creator of NikeDe EverandShoe Dog: A Memoir by the Creator of NikeCalificación: 4.5 de 5 estrellas4.5/5 (537)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureDe EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureCalificación: 4.5 de 5 estrellas4.5/5 (474)
- Never Split the Difference: Negotiating As If Your Life Depended On ItDe EverandNever Split the Difference: Negotiating As If Your Life Depended On ItCalificación: 4.5 de 5 estrellas4.5/5 (838)
- Grit: The Power of Passion and PerseveranceDe EverandGrit: The Power of Passion and PerseveranceCalificación: 4 de 5 estrellas4/5 (587)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaDe EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaCalificación: 4.5 de 5 estrellas4.5/5 (265)
- The Emperor of All Maladies: A Biography of CancerDe EverandThe Emperor of All Maladies: A Biography of CancerCalificación: 4.5 de 5 estrellas4.5/5 (271)
- On Fire: The (Burning) Case for a Green New DealDe EverandOn Fire: The (Burning) Case for a Green New DealCalificación: 4 de 5 estrellas4/5 (73)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersDe EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersCalificación: 4.5 de 5 estrellas4.5/5 (344)
- Team of Rivals: The Political Genius of Abraham LincolnDe EverandTeam of Rivals: The Political Genius of Abraham LincolnCalificación: 4.5 de 5 estrellas4.5/5 (234)
- Rise of ISIS: A Threat We Can't IgnoreDe EverandRise of ISIS: A Threat We Can't IgnoreCalificación: 3.5 de 5 estrellas3.5/5 (137)
- The Unwinding: An Inner History of the New AmericaDe EverandThe Unwinding: An Inner History of the New AmericaCalificación: 4 de 5 estrellas4/5 (45)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyDe EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyCalificación: 3.5 de 5 estrellas3.5/5 (2219)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreDe EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreCalificación: 4 de 5 estrellas4/5 (1090)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)De EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Calificación: 4.5 de 5 estrellas4.5/5 (119)
- The Perks of Being a WallflowerDe EverandThe Perks of Being a WallflowerCalificación: 4.5 de 5 estrellas4.5/5 (2099)
- Her Body and Other Parties: StoriesDe EverandHer Body and Other Parties: StoriesCalificación: 4 de 5 estrellas4/5 (821)
- 16 Commands To Check Hardware Information On Linux - BinaryTidesDocumento13 páginas16 Commands To Check Hardware Information On Linux - BinaryTidesShashin KuroAún no hay calificaciones
- 03 - SYNOPSIS - Garry CachoDocumento11 páginas03 - SYNOPSIS - Garry CachoSugar Ray0% (1)
- Question Combi - 082410Documento43 páginasQuestion Combi - 082410JuhAún no hay calificaciones
- 1805690Documento492 páginas18056901costin1Aún no hay calificaciones
- Valentine Fortune Teller BOYDocumento7 páginasValentine Fortune Teller BOYJudith Maslach CirincioneAún no hay calificaciones
- HYS0631 - C1L2P0 - Brochure Update Sept16 - Hyster J1.5-3.5GXDocumento12 páginasHYS0631 - C1L2P0 - Brochure Update Sept16 - Hyster J1.5-3.5GXMickAún no hay calificaciones
- Da 14 1862a1 PDFDocumento169 páginasDa 14 1862a1 PDFManuel GuiracochaAún no hay calificaciones
- Measure, detect and amplify signals with bridges and op-ampsDocumento2 páginasMeasure, detect and amplify signals with bridges and op-ampsRajaAún no hay calificaciones
- SOP DoconDocumento38 páginasSOP DoconAcep GunawanAún no hay calificaciones
- Business Continuity and Disaster RecoveryDocumento18 páginasBusiness Continuity and Disaster RecoveryUsaid KhanAún no hay calificaciones
- Hydropneumatic Suspension SystemDocumento7 páginasHydropneumatic Suspension Systemaniket wadheAún no hay calificaciones
- BASDocumento178 páginasBASclayjr70Aún no hay calificaciones
- Maemo - I - Introduction To MaemoDocumento15 páginasMaemo - I - Introduction To MaemoCatalin ConstantinAún no hay calificaciones
- Ais Module 1Documento8 páginasAis Module 1Jamie Rose AragonesAún no hay calificaciones
- 28MN49HM - Ld72a PDFDocumento14 páginas28MN49HM - Ld72a PDFtavi100% (2)
- PMI Membership ApplicationDocumento4 páginasPMI Membership ApplicationYamna HasanAún no hay calificaciones
- Portstation Breathing Apparatus Self Contained Breathing ApparatusDocumento1 páginaPortstation Breathing Apparatus Self Contained Breathing ApparatusFebriansyah Ar-rasyid AiniAún no hay calificaciones
- International Standard: Norme InternationaleDocumento11 páginasInternational Standard: Norme InternationaleDirt FilterAún no hay calificaciones
- Life Cycle Assessment of BuildingDocumento12 páginasLife Cycle Assessment of BuildingBAIMOURNE BOURNEBE100% (1)
- Checklist 1 After Recon - Beginner Friendly ChecklistDocumento2 páginasChecklist 1 After Recon - Beginner Friendly Checklistsidhant TechAún no hay calificaciones
- Chapter - 3 System ModellingDocumento32 páginasChapter - 3 System Modellingdesalegn abebeAún no hay calificaciones
- Online Shopping: Zalora PhilippinesDocumento4 páginasOnline Shopping: Zalora PhilippinesFlorence GonzalezAún no hay calificaciones
- Role of Information Technology in Education System 170605100Documento7 páginasRole of Information Technology in Education System 170605100farahdilafAún no hay calificaciones
- Physical Design and Sign OffDocumento43 páginasPhysical Design and Sign OffAgnathavasiAún no hay calificaciones
- BS 1501-2 (1988) PDFDocumento30 páginasBS 1501-2 (1988) PDFAdesina AlabiAún no hay calificaciones
- Anson Ortigas FPS Sell-Out Report Week 2 JuneDocumento30 páginasAnson Ortigas FPS Sell-Out Report Week 2 JuneRevssor PeraltaAún no hay calificaciones
- Xcalibur Custom Reports With MerlinDocumento154 páginasXcalibur Custom Reports With MerlinGC powerAún no hay calificaciones
- ZXUN CSCF Troubleshooting: Common Faults and SolutionsDocumento37 páginasZXUN CSCF Troubleshooting: Common Faults and SolutionsBSSAún no hay calificaciones
- AE ProductCatalog Semiconductors EN 202207Documento40 páginasAE ProductCatalog Semiconductors EN 202207Clayse RalphAún no hay calificaciones
- 1992 Toyota Previa Electrical DiagramDocumento175 páginas1992 Toyota Previa Electrical DiagramTam DominhAún no hay calificaciones