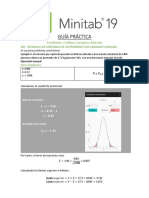
También podría gustarte
- Analisis Flujo EfectivoDocumento13 páginasAnalisis Flujo Efectivopedrop1023Aún no hay calificaciones
- Smart Running SpanishDocumento298 páginasSmart Running SpanishLeandro Reina Pérez100% (1)
- Análisis Multivariante: ACP y ClasificaciónDocumento23 páginasAnálisis Multivariante: ACP y ClasificaciónEmilyAún no hay calificaciones
- Taller 1 Microeconomía AvanzadaDocumento12 páginasTaller 1 Microeconomía AvanzadaJulian Andres Duarte BejaranoAún no hay calificaciones
- Examenes Años AnterioresDocumento334 páginasExamenes Años AnterioresGMAAún no hay calificaciones
- Antologia de EstadisticaDocumento118 páginasAntologia de EstadisticaGerardo Carmona GaliciaAún no hay calificaciones
- Analisis MultivariadoDocumento17 páginasAnalisis Multivariadojean loli100% (1)
- Ejercicio de Aplicación ReasegurosDocumento8 páginasEjercicio de Aplicación ReasegurosVerito GuerreroAún no hay calificaciones
- ANÁLISIS MULTIVARIANTE SalonDocumento9 páginasANÁLISIS MULTIVARIANTE SalonJoaquín Velázquez RblrAún no hay calificaciones
- Metodo Analisis MultivariadoDocumento205 páginasMetodo Analisis MultivariadoEriorkys MajanoAún no hay calificaciones
- Problemas Resueltos de Regresion y Correlacion LinealDocumento4 páginasProblemas Resueltos de Regresion y Correlacion LinealFred Chang100% (2)
- Gestion de MetricasDocumento20 páginasGestion de MetricasVictor Hugo Anaya Yanez0% (1)
- Analisis Factorial 2022Documento43 páginasAnalisis Factorial 2022Anderson VilchezAún no hay calificaciones
- UntitledDocumento148 páginasUntitledJose PizarroAún no hay calificaciones
- Curso de Microeconomía Avanzada-Semanas 10 A 12Documento515 páginasCurso de Microeconomía Avanzada-Semanas 10 A 12Antony GapAún no hay calificaciones
- TEORIA Teoria de ProbabilidadesDocumento15 páginasTEORIA Teoria de Probabilidadeslya aguilar floresAún no hay calificaciones
- Dependencia e InterdependenciaDocumento4 páginasDependencia e InterdependenciaBruno Diaz DelgadoAún no hay calificaciones
- Teoría de La DecisiónDocumento106 páginasTeoría de La DecisiónMartin VertizAún no hay calificaciones
- Análisis MultivariadoDocumento18 páginasAnálisis MultivariadoMauricio HinojosaAún no hay calificaciones
- Clase de Análisis MultivarianteDocumento7 páginasClase de Análisis MultivarianteHoracio Miranda VargasAún no hay calificaciones
- Analisis Multivariado AplicadoDocumento350 páginasAnalisis Multivariado AplicadoAnonymous MVQLe29anXAún no hay calificaciones
- S2 - Contribución Del Marketing v3Documento44 páginasS2 - Contribución Del Marketing v3angely sugey pompa veraAún no hay calificaciones
- 1.2. Estadística InferencialDocumento45 páginas1.2. Estadística InferencialYadira RamírezAún no hay calificaciones
- I.introducción de Análisis MultivarianteDocumento26 páginasI.introducción de Análisis MultivarianteYeny LaricoAún no hay calificaciones
- Analisis MultivariadoDocumento55 páginasAnalisis MultivariadoHarold ManzanaresAún no hay calificaciones
- Fiabilidad de Un Cuestionario Autoadministrado ParDocumento7 páginasFiabilidad de Un Cuestionario Autoadministrado ParDavey AtmeAún no hay calificaciones
- Analisis Con Clases Latentes.Documento2 páginasAnalisis Con Clases Latentes.KarlaKarinaPintoGutierrezAún no hay calificaciones
- Satisfacción de Clientes - Ecuaciones EstructuralesDocumento11 páginasSatisfacción de Clientes - Ecuaciones Estructuralesasvc8536100% (1)
- Pid 00252659Documento110 páginasPid 00252659LlorençAún no hay calificaciones
- Modelo de Ecuaciones Estructurales o Structural Equation ModelingDocumento35 páginasModelo de Ecuaciones Estructurales o Structural Equation ModelingMarco Antonio Molina Molina100% (1)
- Estadística Aplicada RDocumento28 páginasEstadística Aplicada RSebastián LenisAún no hay calificaciones
- Taller de Componentes PrincipalesDocumento18 páginasTaller de Componentes PrincipalesRigoberto ToprresAún no hay calificaciones
- El Pensamiento SistematicoDocumento16 páginasEl Pensamiento SistematicoOrangelAún no hay calificaciones
- Ecuaciones EstructuralesDocumento12 páginasEcuaciones EstructuralesvictoriusAún no hay calificaciones
- Introducción Al Análisis MultivarianteDocumento9 páginasIntroducción Al Análisis MultivarianteCarlos Enrique Vázquez MorenoAún no hay calificaciones
- Modelos de Ecuaciones EstructuralesDocumento18 páginasModelos de Ecuaciones EstructuralesnaldoAún no hay calificaciones
- ESP U2 EA ViHCDocumento7 páginasESP U2 EA ViHCAlvaro Loez100% (1)
- Teoria Completa Primer MitadDocumento43 páginasTeoria Completa Primer MitadAngelAún no hay calificaciones
- 11° Semana Analisis MultivarianteDocumento48 páginas11° Semana Analisis MultivarianteDante Palacios ValdiviezoAún no hay calificaciones
- Análisis Multivariante de Datos de MarketingDocumento6 páginasAnálisis Multivariante de Datos de MarketingMaricieloAún no hay calificaciones
- Teoria de Juegos - SotoDocumento11 páginasTeoria de Juegos - SotoHap Leos100% (1)
- Analisis Multivariado 2Documento119 páginasAnalisis Multivariado 2Andrea FrancoAún no hay calificaciones
- Análisis Factorial Aplicado en La Elaboración de Una TesisDocumento8 páginasAnálisis Factorial Aplicado en La Elaboración de Una Tesisjuan4975Aún no hay calificaciones
- Análisis PCA decisiónDocumento27 páginasAnálisis PCA decisiónGiancarlo Fiestas EstradaAún no hay calificaciones
- Análisis econométricos en RDocumento17 páginasAnálisis econométricos en RJulio César RiascosAún no hay calificaciones
- Analisis MultivarianteDocumento24 páginasAnalisis MultivarianteLiz Ani HL100% (1)
- Tema10 FactorialDocumento12 páginasTema10 FactorialJavier MartinezAún no hay calificaciones
- Sistema de ecuaciones estructurales y análisis de componentes principalesDocumento19 páginasSistema de ecuaciones estructurales y análisis de componentes principalesVivi romaniAún no hay calificaciones
- Análisis Multivariado de DatosDocumento27 páginasAnálisis Multivariado de DatosBryan CalderónAún no hay calificaciones
- Introducción Al Análisis MultivariadoDocumento137 páginasIntroducción Al Análisis Multivariadocristman440% (1)
- F2 Silabo Analisis Multivariante IDocumento2 páginasF2 Silabo Analisis Multivariante ILenin Bravo Pardo0% (1)
- TRABAJO FINAL ANALISIS DE COMPONENTES PRINCIPALES, Lucía Pardo Vazquez, Alfonso Guisado González PDFDocumento17 páginasTRABAJO FINAL ANALISIS DE COMPONENTES PRINCIPALES, Lucía Pardo Vazquez, Alfonso Guisado González PDFAlfonso Guisado GonzálezAún no hay calificaciones
- Tablas Contingencia en SpssDocumento15 páginasTablas Contingencia en SpssRoberto LuengoAún no hay calificaciones
- Unidad IVDocumento46 páginasUnidad IVLeslie Dayana Quintanilla RamosAún no hay calificaciones
- Aplicación de Análisis de Componentes Principales y Métodos BiplotsDocumento13 páginasAplicación de Análisis de Componentes Principales y Métodos BiplotsCindi Miley Cortés RodríguezAún no hay calificaciones
- Mariana Rinciog Tarea 1Documento2 páginasMariana Rinciog Tarea 1Mariana RînciogAún no hay calificaciones
- Ferguson Gould Teoria MicroeconomicaDocumento276 páginasFerguson Gould Teoria MicroeconomicawchiquiarAún no hay calificaciones
- Uso Del Propensity Score Jubc PDFDocumento40 páginasUso Del Propensity Score Jubc PDFXIOMARAramosAún no hay calificaciones
- Modelos Lineales GeneralizadosDocumento42 páginasModelos Lineales GeneralizadosDiana PalomaAún no hay calificaciones
- Modelos Lineales GeneralizadosDocumento8 páginasModelos Lineales GeneralizadosPatricio SaucedaAún no hay calificaciones
- Análisis de Correspondencias: introducción a esta técnica descriptivaDocumento10 páginasAnálisis de Correspondencias: introducción a esta técnica descriptivaLucia Rimachi SialerAún no hay calificaciones
- 5.2) Practico Multivariado STATADocumento11 páginas5.2) Practico Multivariado STATApbchanta100% (1)
- Introducción Al Análisis MultivariadoDocumento4 páginasIntroducción Al Análisis Multivariadoedu_alimania100% (14)
- Estadística MultivarianteDocumento10 páginasEstadística MultivarianteGENESIS MOSQUEDAAún no hay calificaciones
- Anaì Lisis Multivariante-3Documento5 páginasAnaì Lisis Multivariante-3Jordi tomangnimenanAún no hay calificaciones
- Análisis multivariado: métodos y aplicacionesDocumento16 páginasAnálisis multivariado: métodos y aplicacionesnaldoAún no hay calificaciones
- Bases Del ConcursoDocumento1 páginaBases Del ConcursoVerito GuerreroAún no hay calificaciones
- Hogar Dulce Hogar EncuestaDocumento1 páginaHogar Dulce Hogar EncuestaVerito GuerreroAún no hay calificaciones
- Complexivo Marketing 8-6-17Documento72 páginasComplexivo Marketing 8-6-17Verito GuerreroAún no hay calificaciones
- Hoja CuadrosDocumento4 páginasHoja CuadrosVerito GuerreroAún no hay calificaciones
- Estracto de ConstituciónDocumento5 páginasEstracto de ConstituciónVerito GuerreroAún no hay calificaciones
- Terminología Derecho Mercantil y SocietarioDocumento1 páginaTerminología Derecho Mercantil y SocietarioVerito GuerreroAún no hay calificaciones
- Deber ReasegurosDocumento8 páginasDeber ReasegurosVerito GuerreroAún no hay calificaciones
- Dialnet QueEsAnalisisEstadisticoMultivariado 2793989Documento8 páginasDialnet QueEsAnalisisEstadisticoMultivariado 2793989Segu AzulAún no hay calificaciones
- Programa VAQ2015Documento80 páginasPrograma VAQ2015Verito GuerreroAún no hay calificaciones
- Deber ReasegurosDocumento8 páginasDeber ReasegurosVerito GuerreroAún no hay calificaciones
- Formatos Ministerio de Salud EcuadorDocumento40 páginasFormatos Ministerio de Salud EcuadorVerito GuerreroAún no hay calificaciones
- El Bolívar Ya No Es CreíbleDocumento5 páginasEl Bolívar Ya No Es CreíbleVerito GuerreroAún no hay calificaciones
- Manuales administrativos universidad central ecuadorDocumento10 páginasManuales administrativos universidad central ecuadorVerito Guerrero33% (3)
- FormatosDocumento8 páginasFormatosVerito GuerreroAún no hay calificaciones
- Plantilla para Tesis Con Normas APA, Formato APADocumento18 páginasPlantilla para Tesis Con Normas APA, Formato APANazkterAún no hay calificaciones
- Encuesta 10 Cada UnoDocumento1 páginaEncuesta 10 Cada UnoVerito GuerreroAún no hay calificaciones
- Codigos UnescoDocumento74 páginasCodigos UnescoCarlos Farro PisfilAún no hay calificaciones
- Sistema Finan. y Mercado de ValoresDocumento21 páginasSistema Finan. y Mercado de Valoresmayralopez1993isabelAún no hay calificaciones
- IV Unidad Metodos de DepreciacionDocumento17 páginasIV Unidad Metodos de DepreciacionVerito GuerreroAún no hay calificaciones
- MATE DepreciaciónDocumento6 páginasMATE DepreciaciónVerito GuerreroAún no hay calificaciones
- Contrato de Arrendamiento, Marco AyalaDocumento1 páginaContrato de Arrendamiento, Marco AyalaVerito GuerreroAún no hay calificaciones
- Cadena de Valor 2Documento3 páginasCadena de Valor 2Verito GuerreroAún no hay calificaciones
- Cadena de Valor 2Documento3 páginasCadena de Valor 2Verito GuerreroAún no hay calificaciones
- Factores Internos y Externos de La EmpresaDocumento1 páginaFactores Internos y Externos de La EmpresaVerito GuerreroAún no hay calificaciones
- TumblrDocumento2 páginasTumblrVerito GuerreroAún no hay calificaciones
- Encuesta 10 Cada UnoDocumento1 páginaEncuesta 10 Cada UnoVerito GuerreroAún no hay calificaciones
- Prueba de Comparaciones SKNDocumento8 páginasPrueba de Comparaciones SKNRafa PáezAún no hay calificaciones
- Trabajo Práctico #9: Hallar La Ecuación de La Recta de Regresión Lineal y El Coeficiente de Correlación "R"Documento5 páginasTrabajo Práctico #9: Hallar La Ecuación de La Recta de Regresión Lineal y El Coeficiente de Correlación "R"angi rivera espinozaAún no hay calificaciones
- Ad2 Tema1 12 PDFDocumento62 páginasAd2 Tema1 12 PDFKaRen HeRnandezAún no hay calificaciones
- Activiada 3 Semana 5 Estadistica 2Documento3 páginasActiviada 3 Semana 5 Estadistica 2Mile GalindoAún no hay calificaciones
- Práctica3 TEIIIDocumento4 páginasPráctica3 TEIIIjosearce123Aún no hay calificaciones
- Tarea 2 - SolucionarioDocumento23 páginasTarea 2 - SolucionarioBrandon Agurto TarazonaAún no hay calificaciones
- Formulario de Prueba de HipótesisDocumento8 páginasFormulario de Prueba de HipótesisArminda Angulo CalderónAún no hay calificaciones
- Practica MinitabDocumento17 páginasPractica MinitabMarcelo OrellanaAún no hay calificaciones
- Taller 5 Pilo Experimentos 8voDocumento16 páginasTaller 5 Pilo Experimentos 8voAngie Pilonieta RiveraAún no hay calificaciones
- STATGRAFICOSDocumento29 páginasSTATGRAFICOSWilson castilloAún no hay calificaciones
- PracticaDIRIGIDA 01-SPSS V.2017Documento2 páginasPracticaDIRIGIDA 01-SPSS V.2017marinaAún no hay calificaciones
- Portafolio Evidencias U4 Lean Six SigmaDocumento16 páginasPortafolio Evidencias U4 Lean Six SigmaYomar AguilarAún no hay calificaciones
- Muestreo de AceptacionDocumento28 páginasMuestreo de AceptacionDeysi Atequipa CordovaAún no hay calificaciones
- ACTIVIDAD1T1 LopezEstradaRicardoDDocumento23 páginasACTIVIDAD1T1 LopezEstradaRicardoDRicardo López100% (2)
- R Version 4Documento34 páginasR Version 4Jeisson AndresAún no hay calificaciones
- Comandos de StataDocumento15 páginasComandos de StataLuiiz Segu'ura100% (1)
- Estadística Descriptiva Ejercicios Sección 1.2Documento20 páginasEstadística Descriptiva Ejercicios Sección 1.2yessica carolina cedeño sanchezAún no hay calificaciones
- Metodo de Asignación Igual 4 Evaluación de ProporcionesDocumento2 páginasMetodo de Asignación Igual 4 Evaluación de ProporcionesJennifer CayoAún no hay calificaciones
- Laboratorio de Ejercicios FASE 1Documento4 páginasLaboratorio de Ejercicios FASE 1Katia AguilarAún no hay calificaciones
- Scastilloa@upao Edu PeDocumento23 páginasScastilloa@upao Edu Pedalia inga vilchezAún no hay calificaciones
- Intervalos de confianza para estimaciones de poblaciónDocumento4 páginasIntervalos de confianza para estimaciones de poblaciónGina OsorioAún no hay calificaciones
- Econometria Practica I J. VasquezDocumento9 páginasEconometria Practica I J. VasquezJeleina Vasquez CalderonAún no hay calificaciones
- Análisis estadístico de datos agrupados y series de tiempoDocumento4 páginasAnálisis estadístico de datos agrupados y series de tiempoAndres RuizAún no hay calificaciones
- Practica MuestreoDocumento4 páginasPractica MuestreoJairo F. SorianoAún no hay calificaciones
- Estadística inferencial: Pruebas de hipótesis y estimaciónDocumento15 páginasEstadística inferencial: Pruebas de hipótesis y estimaciónChelsy Madeleine Puente De La Vega RoqueAún no hay calificaciones
- Secme-7126 2Documento33 páginasSecme-7126 2Robin Sanchez YanqueAún no hay calificaciones
- Historial de exámenes para Franco Rodriguez Danna Valentina: Sustentación trabajo colaborativoDocumento3 páginasHistorial de exámenes para Franco Rodriguez Danna Valentina: Sustentación trabajo colaborativoDanna Valentina Franco RodriguezAún no hay calificaciones