Documentos de Académico
Documentos de Profesional
Documentos de Cultura
Técnicas Avanzadas de Predicción
Cargado por
GusTavo PrietoTítulo original
Derechos de autor
Formatos disponibles
Compartir este documento
Compartir o incrustar documentos
¿Le pareció útil este documento?
¿Este contenido es inapropiado?
Denunciar este documentoCopyright:
Formatos disponibles
Técnicas Avanzadas de Predicción
Cargado por
GusTavo PrietoCopyright:
Formatos disponibles
etsii Escuela Tcnica Superior de Ingeniera Informtica
Universidad de Sevilla
Departamento de Lenguajes y Sistemas
TCNICAS AVANZADAS DE PREDICCIN
Y OPTIMIZACIN APLICADAS A
SISTEMAS DE POTENCIA
TESIS DOCTORAL
por
Alicia Troncoso Lora
Memoria presentada para optar al grado de
Doctora por la Universidad de Sevilla
Directores: D. Jos Cristbal Riquelme Santos
D. Jos Luis Martnez Ramos
Sevilla, Junio de 2005.
Jos Cristbal Riquelme Santos, Profesor Titular de Universidad, adscrito
al rea de Lenguajes y Sistemas Informticos y Jos Luis Martnez Ramos,
Profesor Titular de Universidad, adscrito al rea de Ingeniera Elctrica,
CERTIFICAN QUE
Alicia Troncoso Lora ha realizado bajo nuestra supervisin el trabajo de in-
vestigacin titulado:
Tcnicas Avanzadas de Prediccin y Optimizacin aplicadas a
Sistemas de Potencia
Una vez revisado, autorizan la presentacin del mismo como Tesis Doctoral en
la Universidad de Sevilla y estiman oportuna su presentacin al tribunal que
habr de valorarlo.
Fdo. Jos C. Riquelme Santos
Profesor Titular de Universidad
rea de Lenguajes y Sistemas Informticos
Fdo. Jos Luis Martnez Ramos
Profesor Titular de Universidad
rea de Ingeniera Elctrica
Sevilla, Junio de 2005
etsii Escuela Tcnica Superior de Ingeniera Informtica
Universidad de Sevilla
Departamento de Lenguajes y Sistemas
TCNICAS AVANZADAS DE PREDICCIN
Y OPTIMIZACIN APLICADAS A
SISTEMAS DE POTENCIA
TESIS DOCTORAL
Autora: Da. Alicia Troncoso Lora
Directores: D. Jos Cristbal Riquelme Santos
D. Jos Luis Martnez Ramos
TRIBUNAL CALIFICADOR
Presidente: D. Jos Miguel Toro Bonilla
Secretario: D. Rafael Morales Bueno
Vocales: D. Antonio Gmez Expsito
Da. Mara Amparo Vila Miranda
D. Antonio Jess Conejo Navarro
Obtuvo la calicacin de Sobresaliente Cum Laude por unanimidad
Sevilla, 3 de Junio de 2005
Esta Tesis Doctoral ha obtenido el premio de investigacin Fun-
dacin Sevillana de Electricidad para Licenciados, Ingenieros y
Arquitectos de las Universidades de Andaluca. Programa conjunto
que realiza la Consejera de Educacin y Ciencia de la Junta de
Andaluca y la Fundacin Sevillana Endesa.
Tesis Doctoral nanciada por el Ministerio de Ciencia y Tecno-
loga (PB97-0719) y la Junta de Andaluca (ACC-1021-TIC-2002).
A mi futuro sobrino
El libro de la naturaleza est escrito en un
lenguaje matemtico.
Galileo Galilei.
Agradecimientos
Quisiera que las primeras lneas de esta tesis fueran el agradecimiento a
todas las personas que me han ayudado a la realizacin de la misma.
En primer lugar quiero agradecer la buena direccin realizada por D. Jos
C. Riquelme Santos y D. Jos Luis Martnez Ramos. A Pepe le quiero reconocer
que bajo su direccin no hayan faltado buenos consejos en todos los aspectos
y un punto de vista prctico. La conanza que siempre ha depositado en m
desde un primer momento y la paciencia que en estos aos me ha mostrado
han sido ejemplares. A Jos Luis le agradezco todo lo que he aprendido de l,
tanto a nivel tcnico como personal. Su meticulosidad y su claridad de ideas en
la direccin de este trabajo de investigacin siempre han sido de gran ayuda.
A D. Antonio Gmez Expsito porque su admirable capacidad de trabajo
y su gusto por las cosas bien hechas es una fuente inagotable de estmulo para
cualquier investigador que est a su lado.
Tambin quisiera recordar a D. Carlos Izquierdo Mitchell por la paz que
siempre transmita en el da a da de un departamento.
A D. Miguel Toro Bonilla por la constante innovacin docente que transmite
a todo el departamento de Lenguajes y Sistemas Informticos.
A todos mis compaeros del Departamento de Ingeniera Elctrica de la
Universidad de Sevilla porque sin ese ambiente de trabajo en equipo y esa ale-
gra que transmiten, hacer una tesis sera algo muy diferente a lo que ha sido.
A Esther porque en estos aos no ha sido slo una compaera de trabajo; a
Jos Mara mi mejor vecino por su ambicin y voluntad de trabajo; a Manuel
Burgos por su incondicional apoyo desde un principio. En especial a Jess no
tengo palabras para agradecerle todo el tiempo que me ha dedicado desinte-
resadamente, tengo que destacar su brillantez como investigador y su calidad
humana puesto que siempre est luchando por lo que considera justo. A Re-
medios por el ahorro de trabajo que supone tener a la eciencia personalizada
como secretaria de un departamento.
A mis compaeros del grupo de investigacin por toda la ayuda desinte-
resada que me han ofrecido: a Jess por su inagotable fuerza en todo lo que
respecta a investigacin; a Paco por las horas de tutora que me ha regalado en
mi primer ao de docencia; a Ral por facilitarme ayuda en muchos aspectos
tanto tcnicos como de organizacin; a Dani por su buen entendimiento en los
grupos de prctica que hemos compartido; a Roberto porque siempre me ha
animado; a Domingo e Isa por su constante inters.
A mis compaeras y compaeros del Departamento de Lenguajes y Siste-
mas de la Universidad de Sevilla por su constante nimo y su predisposicin
siempre a ayudarme en todo lo que he necesitado. En especial a Rafa, Mayte,
Toi y Octavio porque sin ellos la adaptacin hubiera sido mucho ms dura.
A mi familia por creer en m en todo momento de mi carrera profesional.
Mi ilusin por la realizacin de esta tesis tambin ha sido su ilusin.
A mis amigas y amigos por los buenos momentos que me han aportado,
momentos necesarios para desconectar del trabajo que supone la realizacin
de una tesis.
ndice general
1. Introduccin 3
1.1. Motivacin de la Investigacin . . . . . . . . . . . . . . . . . . . 7
1.2. Objetivos de la Tesis . . . . . . . . . . . . . . . . . . . . . . . . 8
1.3. Principales Contribuciones . . . . . . . . . . . . . . . . . . . . . 10
1.4. Estructura de la Memoria . . . . . . . . . . . . . . . . . . . . . 14
2. Estado del Arte 17
2.1. Minera de Datos . . . . . . . . . . . . . . . . . . . . . . . . . . 17
2.2. Preprocesado de Series Temporales . . . . . . . . . . . . . . . . 18
2.3. Mtodos de Prediccin . . . . . . . . . . . . . . . . . . . . . . . 21
2.3.1. Prediccin basada en reglas . . . . . . . . . . . . . . . . 21
2.3.2. Mtodos Lineales . . . . . . . . . . . . . . . . . . . . . . 22
2.3.2.1. Metodologa de Box and Jenkins . . . . . . . . 22
2.3.2.1.1. Modelos ARMA . . . . . . . . . . . . 23
2.3.2.1.2. Modelos ARIMA . . . . . . . . . . . . 24
2.3.2.2. rboles de Regresin . . . . . . . . . . . . . . . 26
2.3.3. Mtodos no Lineales . . . . . . . . . . . . . . . . . . . . 28
2.3.3.1. Mtodos Globales . . . . . . . . . . . . . . . . . 28
2.3.3.1.1. Redes Neuronales Articiales . . . . . 28
2.3.3.1.2. Programacin Gentica . . . . . . . . 30
2.3.3.2. Mtodos Locales: Vecinos . . . . . . . . . . . . 33
2.4. Tcnicas de Optimizacin . . . . . . . . . . . . . . . . . . . . . 36
2.4.1. Programacin Dinmica . . . . . . . . . . . . . . . . . . 40
2.4.2. Programacin Lineal Entera-Mixta: Ramicacin y Cota 41
2.4.3. Relajacin Lagrangiana . . . . . . . . . . . . . . . . . . . 42
2.4.4. Mtodos de Punto Interior . . . . . . . . . . . . . . . . . 43
2.4.5. Algoritmos Genticos . . . . . . . . . . . . . . . . . . . . 48
i
ndice General
I Prediccin de Series Temporales 53
3. Mtodo basado en los Vecinos ms Cercanos 55
3.1. Representacin de los Datos . . . . . . . . . . . . . . . . . . . . 55
3.2. Mtodo basado en los Vecinos ms Cercanos . . . . . . . . . . . 60
3.3. La funcin distancia . . . . . . . . . . . . . . . . . . . . . . . . 62
3.4. Nmero de Vecinos . . . . . . . . . . . . . . . . . . . . . . . . . 63
3.5. Acotacin del Error . . . . . . . . . . . . . . . . . . . . . . . . . 64
4. Aplicacin a los Precios de la
Energa en el Mercado Elctrico 67
4.1. Precios. Optimizacin de Venta/Compra de Energa . . . . . . . 67
4.2. Descripcin del problema . . . . . . . . . . . . . . . . . . . . . . 72
4.3. Obtencin del modelo . . . . . . . . . . . . . . . . . . . . . . . . 72
4.3.1. Con prediccin directa . . . . . . . . . . . . . . . . . . . 72
4.3.2. Con prediccin iterada . . . . . . . . . . . . . . . . . . . 79
4.4. Prediccin. Resultados . . . . . . . . . . . . . . . . . . . . . . . 86
4.4.1. Con prediccin directa . . . . . . . . . . . . . . . . . . . 86
4.4.2. Con prediccin iterada . . . . . . . . . . . . . . . . . . . 92
4.5. Anlisis heurstico del error . . . . . . . . . . . . . . . . . . . . 97
4.6. Comparacin con Redes Neuronales . . . . . . . . . . . . . . . . 98
4.6.1. Estructura de la red neuronal . . . . . . . . . . . . . . . 98
4.6.2. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . 100
4.7. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 102
5. Aplicacin a la Demanda de Energa Elctrica. 105
5.1. Demanda. Programacin Horaria de Centrales . . . . . . . . . . 105
5.2. Descripcin del problema . . . . . . . . . . . . . . . . . . . . . . 108
5.3. Obtencin del modelo . . . . . . . . . . . . . . . . . . . . . . . . 109
5.4. Prediccin. Resultados . . . . . . . . . . . . . . . . . . . . . . . 113
5.5. Estudio Cualitativo y Comparativo de la Demanda y los Precios
de la Energa en el Mercado Elctrico Espaol. . . . . . . . . . . 119
5.6. Comparacin con rboles de Regresin: Algoritmo M5 . . . . . 126
5.6.1. Transformacin de atributos no numricos . . . . . . . . 127
5.6.2. Valores perdidos . . . . . . . . . . . . . . . . . . . . . . 128
5.6.3. Cortes . . . . . . . . . . . . . . . . . . . . . . . . . . . . 129
5.6.4. Suavizado . . . . . . . . . . . . . . . . . . . . . . . . . . 129
5.6.5. Poda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 130
5.6.6. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . 130
5.7. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 132
ii
ndice General
II Programacin con Mltiples Mnimos Locales 133
6. Programacin no Lineal no Convexa 135
6.1. Variables reales . . . . . . . . . . . . . . . . . . . . . . . . . . . 135
6.1.1. Formulacin del problema . . . . . . . . . . . . . . . . . 135
6.1.2. Mtodo propuesto . . . . . . . . . . . . . . . . . . . . . . 136
6.1.2.1. Solucin de los subproblemas . . . . . . . . . . 137
6.1.2.2. Condiciones de optimalidad . . . . . . . . . . . 138
6.1.2.3. Direccin de bsqueda . . . . . . . . . . . . . . 139
6.1.2.4. Actualizacin de variables . . . . . . . . . . . . 141
6.1.2.5. Inicializacin y reduccin del parmetro barrera 142
6.1.2.6. Test de convergencia . . . . . . . . . . . . . . . 143
6.1.2.7. Valor inicial y actualizacin de la cota de la
funcin objetivo . . . . . . . . . . . . . . . . . 144
6.1.3. Un ejemplo de una variable . . . . . . . . . . . . . . . . 145
6.2. Variables reales y enteras . . . . . . . . . . . . . . . . . . . . . . 146
6.2.1. Formulacin del problema . . . . . . . . . . . . . . . . . 146
6.2.2. Mtodo propuesto . . . . . . . . . . . . . . . . . . . . . . 147
6.2.2.1. Solucin de los subproblemas continuos . . . . . 149
6.2.2.2. Solucin de los subproblemas discretos . . . . . 149
6.2.2.3. Valores iniciales y actualizacin de las cotas de
la funcin objetivo . . . . . . . . . . . . . . . . 150
6.2.3. Un ejemplo de dos variables . . . . . . . . . . . . . . . . 151
7. Aplicacin: Programacin Horaria de Centrales 155
7.1. Formulacin del problema . . . . . . . . . . . . . . . . . . . . . 155
7.1.1. Funcin objetivo. . . . . . . . . . . . . . . . . . . . . . . 156
7.1.1.1. Costes de produccin . . . . . . . . . . . . . . . 156
7.1.1.2. Costes de arranque . . . . . . . . . . . . . . . . 156
7.1.1.3. Costes de parada . . . . . . . . . . . . . . . . . 157
7.1.2. Restricciones . . . . . . . . . . . . . . . . . . . . . . . . 159
7.1.2.1. Restricciones tcnicas de las centrales trmicas 159
7.1.2.2. Restricciones tcnicas de las centrales hidrulicas160
7.1.2.3. Restricciones de demanda . . . . . . . . . . . . 162
7.1.2.4. Restricciones de reserva rodante . . . . . . . . . 163
7.2. Solucin mediante el mtodo propuesto . . . . . . . . . . . . . . 165
7.2.1. Subproblema continuo . . . . . . . . . . . . . . . . . . . 165
7.2.2. Subproblema discreto . . . . . . . . . . . . . . . . . . . . 168
7.3. Resultados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 171
7.3.1. Comparacin con algoritmos genticos . . . . . . . . . . 173
iii
ndice General
7.4. Conclusiones . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 179
8. Conclusiones y Futuras Lneas de Investigacin 181
8.1. Prediccin . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 182
8.2. Optimizacin . . . . . . . . . . . . . . . . . . . . . . . . . . . . 183
8.3. Futuras lneas de investigacin . . . . . . . . . . . . . . . . . . . 184
8.3.1. Prediccin . . . . . . . . . . . . . . . . . . . . . . . . . . 184
8.3.2. Optimizacin . . . . . . . . . . . . . . . . . . . . . . . . 185
A. rboles de Regresin 187
A.1. Sin seleccin de atributos . . . . . . . . . . . . . . . . . . . . . . 187
A.2. Con seleccin de atributos . . . . . . . . . . . . . . . . . . . . . 215
B. Datos 223
B.1. Caso test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223
B.2. Caso realista . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 225
C. Soluciones obtenidas 231
C.1. Caso test . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
C.2. Caso realista . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 231
D. Subproblemas 245
D.1. Subproblema continuo . . . . . . . . . . . . . . . . . . . . . . . 245
D.2. Subproblema discreto . . . . . . . . . . . . . . . . . . . . . . . . 255
iv
ndice de guras
2.1. Fase de Minera de Datos . . . . . . . . . . . . . . . . . . . . . . 18
2.2. Representacin de un individuo. . . . . . . . . . . . . . . . . . . 31
2.3. Algoritmo de Punto Interior . . . . . . . . . . . . . . . . . . . . 48
3.1. Vecinos Falsos. . . . . . . . . . . . . . . . . . . . . . . . . . . . 58
3.2. Vecinos falsos versus longitud de la ventana. . . . . . . . . . . . 60
3.3. Aproximacin local. . . . . . . . . . . . . . . . . . . . . . . . . . 61
4.1. Media horaria de los precios. . . . . . . . . . . . . . . . . . . . . 69
4.2. Distribucin de los precios. . . . . . . . . . . . . . . . . . . . . . 69
4.3. Histograma de los precios del ao 2000 y 2001. . . . . . . . . . . 70
4.4. Precios de dos das de marzo. . . . . . . . . . . . . . . . . . . . 71
4.5. Coeciente de correlacin. . . . . . . . . . . . . . . . . . . . . . 71
4.6. Vecinos falsos. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73
4.7. Pseudocdigo del algoritmo FNN para la serie temporal Precios. 74
4.8. Nmero de vecinos cercanos falsos. . . . . . . . . . . . . . . . . 76
4.9. Pseudocdigo del algoritmo para obtener el nmero de vecinos. . 77
4.10. Nmero ptimo de vecinos usando la distancia Eucldea. . . . . 78
4.11. Nmero ptimo de vecinos usando la distancia Manhattan. . . . 78
4.12. Pseudocdigo del algoritmo FNN para la serie temporal Precios. 81
4.13. Nmero de vecinos cercanos falsos. . . . . . . . . . . . . . . . . 83
4.14. Pseudocdigo del algoritmo para obtener el nmero de vecinos. . 84
4.15. Nmero ptimo de vecinos usando la distancia Eucldea. . . . . 85
4.16. Nmero ptimo de vecinos usando la distancia Manhattan. . . . 85
4.17. Pseudocdigo del algoritmo para obtener predicciones. . . . . . 87
4.18. Media horaria de la prediccin usando la distancia Eucldea. . . 89
4.19. Media horaria de la prediccin usando la distancia Manhattan. . 89
4.20. Media diaria de la prediccin usando la distancia Eucldea. . . . 90
4.21. Media diaria de la prediccin usando la distancia Manhattan. . 90
4.22. Media diaria del error relativo usando la distancia Eucldea. . . 91
4.23. Media diaria del error relativo usando la distancia Manhattan. . 91
i
ndice de Figuras
4.24. Pseudocdigo del algoritmo para obtener predicciones. . . . . . 93
4.25. Media horaria de la prediccin usando la distancia Eucldea. . . 94
4.26. Media horaria de la prediccin usando la distancia Manhattan. . 94
4.27. Media diaria de la prediccin usando la distancia Eucldea. . . . 95
4.28. Media diaria de la prediccin usando la distancia Manhattan. . 95
4.29. Media diaria del error relativo usando la distancia Eucldea. . . 96
4.30. Media diaria del error relativo usando la distancia Manhattan. . 96
4.31. Error medio de la prediccin. . . . . . . . . . . . . . . . . . . . 99
4.32. Error absoluto de la mejor y peor prediccin. . . . . . . . . . . . 100
4.33. Media horaria de la prediccin de los precios para el mes de marzo.101
5.1. Media horaria de la demanda. . . . . . . . . . . . . . . . . . . . 107
5.2. Histograma de la demanda del ao 2000 y 2001. . . . . . . . . . 107
5.3. Coeciente de Correlacin. . . . . . . . . . . . . . . . . . . . . . 108
5.4. Nmero de vecinos cercanos falsos. . . . . . . . . . . . . . . . . 111
5.5. Nmero ptimo de vecinos usando la distancia Manhattan. . . . 112
5.6. Nmero ptimo de vecinos usando la distancia Eucldea. . . . . 112
5.7. Media horaria de la prediccin usando la distancia Eucldea. . . 114
5.8. Media horaria de la prediccin usando la distancia Manhattan. . 114
5.9. Media diaria de la prediccin. . . . . . . . . . . . . . . . . . . . 115
5.10. Media horaria del error absoluto. . . . . . . . . . . . . . . . . . 116
5.11. Mejor prediccin semanal. . . . . . . . . . . . . . . . . . . . . . 116
5.12. Peor prediccin semanal. . . . . . . . . . . . . . . . . . . . . . . 117
5.13. Mejor prediccin diaria. . . . . . . . . . . . . . . . . . . . . . . 118
5.14. Peor prediccin diaria. . . . . . . . . . . . . . . . . . . . . . . . 118
5.15. Relaciones entre los precios de horas consecutivas. . . . . . . . . 120
5.16. Relaciones entre la demanda de horas consecutivas. . . . . . . . 120
5.17. Relacin entre los precios de la hora 7 y la hora 8. . . . . . . . . 121
5.18. Relacin entre la demanda de la hora 7 y la hora 8. . . . . . . . 121
5.19. Relacin entre los precios de das consecutivos. . . . . . . . . . . 122
5.20. Relacin entre la demanda de das consecutivos. . . . . . . . . . 122
5.21. Relacin entre los precios de la hora 1 en das consecutivos. . . . 123
5.22. Relacin entre la demanda de la hora 1 en das consecutivos. . . 123
5.23. Atractor de los precios. . . . . . . . . . . . . . . . . . . . . . . . 124
5.24. Atractor de la demanda. . . . . . . . . . . . . . . . . . . . . . . 125
6.1. Mltiples mnimos de una funcin no convexa. . . . . . . . . . . 145
6.2. Supercie denida por una funcin no lineal no convexa. . . . . 151
6.3. Supercie denida por una funcin no lineal no convexa. . . . . 152
6.4. Sucesin de mnimos locales para el ejemplo mixto-entero. . . . 153
ii
ndice de Figuras
7.1. Coste de produccin. . . . . . . . . . . . . . . . . . . . . . . . . 156
7.2. Coste de arranque. . . . . . . . . . . . . . . . . . . . . . . . . . 157
7.3. Curva de demanda de potencia. . . . . . . . . . . . . . . . . . . 163
7.4. a) Matriz de optimizacin, b) Elementos de llenado . . . . . . . 167
7.5. a) Matriz de optimizacin reordenada, b) Elementos de llenado . 167
7.6. a) Matriz de optimizacin, b) Elementos de llenado . . . . . . . 170
7.7. a) Matriz de optimizacin reordenada, b) Elementos de llenado . 170
7.8. Operador de cruce por las . . . . . . . . . . . . . . . . . . . . 175
7.9. Operador de cruce por columnas . . . . . . . . . . . . . . . . . 175
7.10. Evolucin del mejor individuo para caso test. . . . . . . . . . . . 176
7.11. Evolucin del mejor individuo para caso realista. . . . . . . . . . 176
7.12. Tiempo de ejecucin segn actividades . . . . . . . . . . . . . . 177
A.1. rbol de regresin con 151 reglas. . . . . . . . . . . . . . . . . . 195
A.2. Modelos lineales en cada hoja del rbol de regresin formado
por 151 reglas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 215
A.3. rbol de regresin con 53 reglas. . . . . . . . . . . . . . . . . . 218
A.4. Modelos lineales en cada hoja del rbol de regresin formado
por 53 reglas. . . . . . . . . . . . . . . . . . . . . . . . . . . . . 221
iii
ndice de Tablas
2.1. Dimensin del problema. . . . . . . . . . . . . . . . . . . . . . . 40
4.1. Porcentaje de vecinos falsos segn distancias. . . . . . . . . . . . 75
4.2. Porcentaje de vecinos falsos segn distancias. . . . . . . . . . . . 82
4.3. Media y desviacin estndar del conjunto test. . . . . . . . . . . 88
4.4. Errores segn distancias. . . . . . . . . . . . . . . . . . . . . . . 92
4.5. Errores segn distancias. . . . . . . . . . . . . . . . . . . . . . . 97
4.6. Inuencia de la distancia en la optimizacin de los distintos tipos
de errores. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 98
4.7. Resumen de los errores de la prediccin. . . . . . . . . . . . . . 101
4.8. Errores obtenidos con ambos mtodos. . . . . . . . . . . . . . . 102
5.1. Porcentaje de vecinos falsos segn distancias. . . . . . . . . . . . 110
5.2. Media y desviacin estndar del conjunto test. . . . . . . . . . . 113
5.3. Errores diarios de la mejor y la peor prediccin semanal. . . . . 117
5.4. Errores segn distancias. . . . . . . . . . . . . . . . . . . . . . . 119
5.5. Exponentes de Lyapunov. . . . . . . . . . . . . . . . . . . . . . 126
5.6. Transformacin de atributos no numricos en variables binarias. 128
5.7. Comparacin de los errores de la prediccin de la demanda usan-
do ambos mtodos. . . . . . . . . . . . . . . . . . . . . . . . . . 131
7.1. Vericacin de una restriccin lgica. . . . . . . . . . . . . . . . 159
7.2. Secuencia de mnimos locales. . . . . . . . . . . . . . . . . . . . 172
7.3. Secuencia de mnimos locales. . . . . . . . . . . . . . . . . . . . 172
7.4. Secuencia de mnimos locales. . . . . . . . . . . . . . . . . . . . 173
7.5. Comparacin de resultados para el caso test. . . . . . . . . . . . 178
7.6. Comparacin de resultados para el caso realista. . . . . . . . . . 178
B.1. Caractersticas tcnicas de las centrales trmicas del caso test. . 224
B.2. Costes de las centrales trmicas del caso test. . . . . . . . . . . . 224
B.3. Demanda para el caso test. . . . . . . . . . . . . . . . . . . . . . 224
i
ndice de Tablas
B.4. Caractersticas tcnicas de las centrales trmicas del caso rea-
lista (Centrales 1 a 25). . . . . . . . . . . . . . . . . . . . . . . . 225
B.5. Caractersticas tcnicas de las centrales trmicas del caso rea-
lista (Centrales 26 a 49). . . . . . . . . . . . . . . . . . . . . . . 226
B.6. Costes de las centrales trmicas del caso realista (Centrales 1 a
25). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 227
B.7. Costes de las centrales trmicas del caso realista (Centrales 26
a 49). . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 228
B.8. Demanda para el caso realista. . . . . . . . . . . . . . . . . . . . 229
C.1. Matriz de acoplamiento de la mejor solucin para el caso test
por: a) el mtodo propuesto, b) el Algoritmo Gentico. . . . . . 232
C.2. Potencias (MW) de la mejor solucin para el caso test por: a)
el mtodo propuesto, b) el Algoritmo Gentico. . . . . . . . . . 233
C.3. Matriz de acoplamiento de la mejor solucin para el caso realista
por el mtodo propuesto (Horas 1 a 18). . . . . . . . . . . . . . 234
C.4. Matriz de acoplamiento de la mejor solucin para el caso realista
por el mtodo propuesto (Horas 19 a 24). . . . . . . . . . . . . . 235
C.5. Potencias (MW) de la mejor solucin para el caso realista por
el mtodo propuesto (horas 1 a 8). . . . . . . . . . . . . . . . . 236
C.6. Potencias (MW) de la mejor solucin para el caso realista por
el mtodo propuesto (horas 9 a 16). . . . . . . . . . . . . . . . . 237
C.7. Potencias (MW) de la mejor solucin para el caso realista por
el mtodo propuesto (horas 17 a 24). . . . . . . . . . . . . . . . 238
C.8. Matriz de acoplamiento de la mejor solucin para el caso realista
por el Algoritmo Gentico (Horas 1 a 18). . . . . . . . . . . . . 239
C.9. Matriz de acoplamiento de la mejor solucin para el caso realista
por el Algoritmo Gentico (Horas 19 a 24). . . . . . . . . . . . . 240
C.10.Potencias (MW) de la mejor solucin para el caso realista por
el Algoritmo Gentico (horas 1 a 8). . . . . . . . . . . . . . . . . 241
C.11.Potencias (MW) de la mejor solucin para el caso realista por
el Algoritmo Gentico (horas 9 a 16). . . . . . . . . . . . . . . . 242
C.12.Potencias (MW) de la mejor solucin para el caso realista por
el Algoritmo Gentico (horas 17 a 24). . . . . . . . . . . . . . . 243
ii
Resumen
Esta tesis est enmarcada bsicamente dentro de dos campos de investiga-
cin, la minera de datos y la optimizacin. Principalmente tiene un carcter
aplicado, ya que se han investigado tanto tcnicas de prediccin como de op-
timizacin con el objetivo de ser aplicadas a problemas que aparecen en el
campo de Ingeniera Elctrica. No obstante, los algoritmos desarrollados se
podrn aplicar a problemas similares en futuras lneas de investigacin.
Un primer objetivo de la tesis ha sido el anlisis, desarrollo y mejora de
tcnicas que ayuden a descubrir las principales caractersticas de una serie
temporal con el objetivo principal de predecir su comportamiento en un fu-
turo cercano. La investigacin ha estado centrada principalmente en series
temporales nancieras que se modelen a travs de reglas de mercado, debido a
la dicultad que tienen este tipo de series en lo que respecta a reconocimiento
de patrones, clasicacin y prediccin.
Estas tcnicas se han aplicado a la prediccin de los precios de la energa
elctrica en el Mercado Elctrico Espaol en el que, debido a su reciente libe-
ralizacin son poco usuales en la literatura, siendo un campo de investigacin
actualmente en estudio. De igual forma, se han aplicado a la demanda de ener-
ga elctrica y los resultados obtenidos han sido comparados con los existentes
de la aplicacin de otras tcnicas.
Hoy da, los mtodos ms usados para la prediccin de los precios y la de-
manda de la energa en el mercado elctrico son, a grandes rasgos, los distintos
tipos de Redes Neuronales Articiales (RNA) y los mtodos estadsticos tra-
dicionales, siendo en este contexto la primera vez que se aplica un clasicador
basado en los vecinos ms cercanos.
El segundo objetivo es consecuencia directa del primero, puesto que el ob-
jeto ltimo de realizar una prediccin siempre es la planicacin o explotacin
ptima de algn sistema teniendo en cuenta la prediccin realizada anterior-
mente. As, la segunda parte de la tesis se enmarca dentro del amplio campo
de la optimizacin y consiste en el desarrollo de un algoritmo de optimizacin
que explote tcnicas globales de bsqueda de mnimos, ya que actualmente en
la literatura los algoritmos clsicos de optimizacin usan tcnicas locales de
bsqueda. En los ltimos aos, las tcnicas de Punto Interior han sido usadas
en un nmero amplio de problemas de optimizacin local de distintas reas de
conocimiento, debido a los buenos resultados obtenidos.
As se ha desarrollado una herramienta capaz de recorrer una trayectoria de
mnimos locales cada vez mejores sin quedar atrapado en el primer mnimo
que encuentre. La herramienta desarrollada tiene un bajo coste computacional
y presenta un tiempo de ejecucin inferior a cualquier tcnica computacional
evolutiva, que son una de las nicas alternativas a este tipo de problemas.
Esta nueva herramienta es totalmente novedosa y para validarla se ha apli-
cado a un problema real de planicacin denominado Programacin Horaria
de Centrales Trmicas (PHCT), que consiste en determinar el plan de aco-
plamiento y la generacin de energa elctrica de las centrales para satisfacer
la demanda a coste mnimo. Para resolver este problema de planicacin es
necesario tener una prediccin de la demanda (primera parte de la tesis).
Captulo 1
Introduccin
La prediccin de eventos futuros siempre ha fascinado al gnero humano
y se puede decir que las tcnicas de prediccin existen desde que ste existe.
Sin embargo, con el paso del tiempo estas tcnicas se han ido sosticando y se
han aplicado en distintas reas, con nes cientcos y econmicos, como en la
prediccin del tiempo, en la prediccin del cambio entre monedas...
Hoy da, se puede decir que estamos en la era de la tecnologa y la infor-
macin, ya que en la mayora de las actividades se generan grandes bancos de
datos que son almacenados en bases de datos. Gracias a la tecnologa estos
datos se pueden manejar y usar para sacar algn rendimiento de ellos, ya que
debido al gran volumen de informacin es imposible de analizar e interpre-
tar manualmente. Esto hace que desde nales de los aos 90 los conceptos de
Descubrimiento del Conocimiento en Bases de Datos (Knowledge Discovery in
Databases, KDD) o Minera de Datos (Data Mining, MD) [32] hayan incre-
mentado su importancia dando lugar a campos de investigacin actualmente
emergentes. La minera de datos es el proceso de inferir conocimiento, a prio-
ri desconocido, que sea til y comprensible, a partir de grandes cantidades
de datos, con el objetivo de predecir de una manera automtica tendencias y
comportamientos y describir modelos que simulen el sistema.
Anteriormente al desarrollo de la minera de datos, la prediccin de la
evolucin en el tiempo de alguna variable, es decir la prediccin de una serie
temporal, se llevaba a cabo mediante la elaboracin de modelos a travs de
mtodos estadsticos, los cuales estiman los valores actuales de la variable en
funcin de los valores de dicha variable en el pasado. Sin embargo, aunque la
ventaja de estos mtodos es su inherente simplicidad no muestran resultados
satisfactorios cuando se trata de predecir series temporales del mundo real,
puesto que las dependencias que existen entre las variables son no lineales.
En las ltimas dcadas, el diseo de algoritmos de aprendizaje automtico
3
Captulo 1 Introduccin
(Machine Learning, ML) ha constitudo una de las ramas de mayor inters
para los investigadores de MD. De esta manera, se disean las RNA como
mtodo capaz de aprender las relaciones no lineales entre las variables de en-
trada (principalmente valores pasados de la serie y valores de otras variables
que inuyen en la serie) y las variables de salida (valores futuros de la serie).
stas han sido aplicadas a la prediccin de series temporales dando lugar a
resultados ms ecientes que los mtodos clsicos, sin embargo presentan una
desventaja que es el tiempo de aprendizaje que requieren.
En la primera parte de esta tesis se presenta una tcnica, basada en la
tcnica de los vecinos ms cercanos, para la prediccin de series temporales,
que presenta las ventajas de una red neuronal en lo que respecta al aprendizaje
de las relaciones no lineales existentes entre las variables y que mejora el tiempo
de aprendizaje puesto que ste es mnimo. Estas tcnicas se han aplicado a la
prediccin de dos series temporales del mundo real: los precios de la energa
en el nuevo mercado elctrico y la demanda de energa elctrica.
El objetivo principal y ltimo de cualquier prediccin de un evento futuro
siempre es la optimizacin, puesto que la optimizacin es un proceso que se
nutre de las predicciones realizadas para obtener algn benecio, como por
ejemplo reducir costes en el caso de los clientes de un servicio o incrementar
benecios en el caso de una empresa. De esta forma, el obtener una prediccin
simplemente proporciona ayuda para elaborar las estrategias necesarias y las
decisiones adecuadas siempre con vistas a optimizar algn objetivo.
En el caso de los precios de la energa en el mercado elctrico, una vez
obtenida la prediccin, las compaas elctricas deben determinar la progra-
macin de generacin de energa horaria para maximizar el benecio obtenido
por la venta de energa. El problema de obtener la planicacin ptima de
la produccin de energa para una compaa de generacin se puede modelar
como un problema de optimizacin que se detalla a continuacin [21].
Funcin objetivo:
La funcin objetivo viene dada por:
B
T
=
24
t=1
t
P
t
C
T
(1.1)
C
T
= C(P
t
) U
t
+CA(S
t
) Y
t
+CP Z
t
(1.2)
donde:
B
T
es el benecio total de la compaa de generacin.
t
es la prediccin del precio de la energa en el mercado en la hora t.
4
Introduccin
P
t
es la potencia media generada en la hora t.
C
T
es el coste total formado por los costes de produccin, C(P
t
), los
costes de arranque, CA(S
t
), que dependen del nmero de horas que el
generador lleve apagado, S
t
, y los costes de parada, CP.
U
t
es una variable binaria que es igual a 1 si el generador est funcio-
nando en la hora t, y Y
t
y Z
t
son variables binarias que son igual a 1 si
el generador se enciende o se apaga al principio de la hora t, respectiva-
mente.
Restricciones:
Las restricciones del problema de optimizacin son las siguientes:
La limitacin mxima y mnima de la generacin:
P
m
U
t
P
t
P
M
U
t
(1.3)
donde P
M
y P
m
son las potencias mximas y mnimas del generador,
respectivamente.
Las rampas de subida y bajada:
P
t
= mn{P
M
(U
t
Z
t+1
) +SD Z
t+1
,
P
t1
+RS U
t1
+SU Y
t
} (1.4)
P
t
= m ax {P
m
, P
t1
RB U
t
} (1.5)
donde P
t
y P
t
son la potencia mnima y mxima disponible generada en
la hora t, RS y RB son las rampas mximas de subida y bajada, y SU
y SD son las rampas mximas de arranque y parada, respectivamente.
Tiempos mnimos de funcionamiento y parada:
(X
t
UT) (U
t1
U
t
) 0 (1.6)
(X
t
+DT) (U
t
U
t1
) 0 (1.7)
donde X
t
es el nmero de horas que el generador ha estado encendido
o apagado al nal de la hora t y UT y DT son los tiempos mnimos de
funcionamiento y parada del generador, respectivamente.
5
Captulo 1 Introduccin
Restricciones lgicas:
Y
t
Z
t
= U
t
U
t1
(1.8)
Y
t
+Z
t
1 (1.9)
En un mercado liberalizado las herramientas de prediccin son muy importan-
tes, ya que en base a una prediccin de precios, las compaas de generacin
elaboran sus estrategias de ofertas para maximizar los benecios obtenidos por
la venta de energa en el mercado.
En el caso de la demanda de energa elctrica, una vez obtenida la predic-
cin, las empresas elctricas deben planicar la produccin de energa de las
centrales elctricas de manera que se satisfaga la demanda predicha a coste
mnimo. El problema de la programacin horaria de centrales (PHC), descrito
brevemente en la seccin 2.4 y de una manera ms detallada en el Captulo 7,
tiene por objeto determinar los arranques y paradas de las centrales trmicas
y la programacin conjunta de potencia generada por los grupos trmicos e
hidrulicos durante un horizonte temporal de corto plazo, normalmente 24 ho-
ras, de manera que se satisfaga la demanda horaria, en base a una prediccin,
y se minimice el coste de explotacin del sistema.
Una gran variedad de problemas, que aparecen en campos como la Inge-
niera o la Economa, basados en casos reales, se pueden modelar como un
problema de optimizacin. Existen distintas clasicaciones de los problemas
de optimizacin segn el criterio que se elija. Los problemas de optimizacin
se pueden clasicar dentro de dos grandes grupos: Programacin Lineal y Pro-
gramacin no Lineal, donde tanto la funcin objetivo como las ecuaciones que
modelan las restricciones del problema son lineales o no lineales, respectiva-
mente. A su vez dependiendo de si existen algunas variables enteras, estos
dos grupos de subdividen en otros dos: Programacin Lineal Entera Mixta y
Programacin no Lineal Entera Mixta. Atendiendo a la convexidad de la fun-
cin objetivo y las restricciones, tambin se pueden clasicar en Programacin
Convexa o Programacin No Convexa.
La principal caracterstica de los problemas de optimizacin no lineales
y no convexos, tanto continuos como discretos, es la presencia de mltiples
mnimos locales. Hoy da, la mayora de los algoritmos aplicados a este tipo de
problemas obtienen un mnimo local pero no se puede asegurar que el mnimo
local encontrado sea un mnimo global, por tanto el mnimo encontrado puede
distar de la mejor solucin del problema.
La segunda parte de esta tesis, se centra en la resolucin de problemas de
optimizacin con mltiples mnimos locales y presenta un algoritmo novedoso
que resuelve de forma eciente y satisfactoria este tipo de problemas de una
6
Introduccin
forma simple. Este algoritmo bsicamente consiste en resolver una sucesin de
problemas de optimizacin obteniendo una sucesin decreciente de mnimos
locales. Aunque no se puede asegurar que el mejor mnimo local encontrado
sea el mnimo global, esta tcnica consigue recorrer una trayectoria de mnimos
locales cada vez mejores sin quedar atrapado en el primer mnimo local que
se encuentre.
1.1. Motivacin de la Investigacin
La principal motivacin de la realizacin de esta investigacin es la apli-
cacin de las mejoras obtenidas tanto en las tcnicas de prediccin como de
optimizacin a la resolucin de problemas reales.
Todos los avances en el desarrollo de sistemas inteligentes, y tcnicas de
extraccin de conocimiento para la decisin, control y prediccin de series
temporales, en el campo de MD, se han aplicado a la demanda de energa
elctrica y a los precios de la energa en el Mercado Elctrico Espaol.
Existen una amplia variedad de centrales elctricas: trmicas, hidrulicas,
de bombeo, elicas. Es importante conocer la demanda con anticipacin para
decidir, en funcin de su capacidad y costes, qu centrales suministrarn la
energa necesaria, de manera que el sistema sea seguro, econmico, able y se
usen de manera eciente los recursos energticos tanto de nuestra regin como
importados. Mejoras en la exactitud de la estimacin de la demanda puede
conducir a un mayor desarrollo econmico de una regin.
En los ltimos aos, las empresas elctricas que, haban funcionado en rgi-
men de monopolio, estn tendiendo progresivamente a un contexto liberalizado
con el objeto de que, al eliminar el rgimen de monopolio, se genere compe-
tencia en el mercado, lo que debera llevar consigo un efecto benecioso sobre
los consumidores, tanto en calidad de servicio como en precios. El Sector Elc-
trico Espaol desde 1998 ha puesto en marcha un proceso de reestructuracin
siguiendo criterios de libre competencia, al igual que un gran nmero de pases
en el mundo. En este nuevo mercado, las herramientas de prediccin son muy
importantes, ya que en base a una estimacin de precios, los consumidores y
generadores elaboran sus ofertas de compra/venta de energa a coste mnimo.
Debido a la reciente liberalizacin del mercado elctrico, las tcnicas de pre-
diccin aplicadas a los precios de la energa son bastante innovadoras y poco
usuales en la literatura actual, siendo un campo de investigacin actualmente
en alza. En lo que respecta a la literatura sobre tcnicas de prediccin aplica-
das a la demanda elctrica y a los precios de la energa, no se han encontrado
referencias en las cuales se haya aplicado una tcnica basada en los vecinos ms
7
Captulo 1 Introduccin
cercanos para predecir ambas series, aunque s se han encontrado aplicaciones
de tcnicas basadas en los vecinos ms cercanos a otras series temporales.
El problema de la optimizacin en sistemas elctricos de potencia surge a
partir del momento en que dos o ms unidades de generacin deben alimentar
varias cargas, obligando al operador a decidir cmo se reparte la carga. Hist-
ricamente, los primeros esfuerzos se hicieron respecto al control de la potencia
activa [136], lo que se conoce hoy da con el nombre de Despacho Econmi-
co, en el cual el objetivo es determinar la potencia a generar por las distintas
unidades minimizando los costes de generacin. En los ltimos aos [30, 137],
las tcnicas de Punto Interior se han constituido en una alternativa prctica
y viable para la resolucin de problemas de optimizacin en el marco de los
sistemas elctricos de potencia.
Por este motivo, se ha desarrollado e implementado un algoritmo basado
en tcnicas de Punto Interior para resolver el problema de la PHCT. En la
literatura este problema no ha sido resuelto de una manera satisfactoria [82,
40], debido principalmente al carcter no lineal y no convexo proporcionado
por las variables discretas que aparecen al modelar el arranque y parada de
las centrales trmicas. Los resultados obtenidos son de gran relevancia, debido
al papel crucial que tienen los algoritmos de optimizacin en la explotacin y
control de la red de transporte de energa elctrica, con vistas a asegurar un
suministro de energa a la vez able, de calidad y lo ms econmico posible.
1.2. Objetivos de la Tesis
Los objetivos concretos de la presente tesis son:
Desarrollar un mtodo, basado en tcnicas de vecinos, para la predic-
cin de series temporales, principalmente series temporales nancieras
que presentan unas caractersticas peculiares como la no linealidad, no
estacionariedad y la presencia de un alto porcentaje de valores inusuales.
Aplicar el mtodo de prediccin desarrollado a la prediccin de dos series
temporales reales: la demanda de energa elctrica y los precios de la
energa en el nuevo Mercado Elctrico Espaol. Se han elegido estas dos
series debido al papel importante que tienen en el sector elctrico hoy
da.
Comparar el comportamiento del mtodo desarrollado ante la prediccin
de las dos series anteriores. Esto llevar a establecer una comparacin
cualitativa entre ambas series.
8
Introduccin
Comparar los resultados obtenidos de la aplicacin de la tcnica desarro-
llada a la demanda de energa elctrica, con los obtenidos de la aplicacin
de un rbol de regresin obtenido con el algoritmo M5.
Desarrollar una RNA para la prediccin de los precios de la energa, de-
bido a que actualmente en un entorno liberalizado como el espaol, la
prediccin de los precios son un factor determinante para la gestin pti-
ma de ofertas de compra y venta de energa por parte de los consumidores
y empresas de generacin.
Comparar los resultados obtenidos de la aplicacin de la tcnica desarro-
llada a los precios de la energa, con los obtenidos de la aplicacin de la
red neuronal.
Desarrollar un algoritmo para la resolucin de problemas de optimiza-
cin no lineales no convexos, basado en tcnicas de Punto Interior, que
resuelva de manera satisfactoria, eciente y robusta este tipo de proble-
mas. Teniendo en cuenta que estos problemas presentan mltiples m-
nimos locales y que la principal desventaja de los algoritmos existentes
en la literatura para resolver este tipo de problemas es la obtencin de
un mnimo local que puede distar mucho del mnimo global, se propone
mejorar esto obteniendo al menos una sucesin de mnimos locales cada
vez mejores que tiendan al mnimo global.
Aplicar el algoritmo desarrollado para problemas no lineales no conve-
xos al problema de la PHCT, el cual cumple esas caractersticas de no
linealidad y no convexidad, debido principalmente a las variables discre-
tas que modelan los arranques y paradas de las centrales. Para resolver
este problema se necesita primero una prediccin de la demanda, que se
obtiene como se describe en la primera parte de la tesis.
Desarrollar un Algoritmo Gentico (AG) para la resolucin del problema
de la PHCT. Este problema es relevante tanto para el operador de un
sistema de energa elctrica como para las compaas de generacin. La
programacin horaria es un problema de optimizacin no lineal, entero-
mixto, combinatorio y, para sistemas de tamao realista, de gran dimen-
sin. Estas caractersticas hacen que no haya ningn mtodo que sea
capaz de obtener su solucin exacta. Los algoritmos genticos son tc-
nicas de resolucin que pueden modelar cualquier tipo de restriccin y
cualquier no linealidad o no convexidad, por lo que son buenos candidatos
para obtener la solucin de este problema.
9
Captulo 1 Introduccin
Comparar los resultados obtenidos de la aplicacin del algoritmo desarro-
llado a dos casos de estudio basados en el parque de generacin espaol,
un sistema test de pequea dimensin y un sistema realista de gran di-
mensin, con los obtenidos de la aplicacin del AG.
1.3. Principales Contribuciones
En el marco de las series temporales, se ha diseado un algoritmo de pre-
diccin, basado en la tcnica de los vecinos ms cercanos, que ha sido aplicado
a la prediccin de dos series temporales: la demanda de energa elctrica y los
precios de la energa. En este algoritmo se aporta un estudio exhaustivo del
clculo ptimo de todos los parmetros que afectan al rendimiento del algorit-
mo y un anlisis de cundo el error cometido con este mtodo de prediccin es
mnimo. Los resultados obtenidos de su aplicacin a ambas series son compara-
dos con los obtenidos de la aplicacin de otras tcnicas como redes neuronales
y rboles de regresin. Por ltimo, para demostrar la importancia de obtener
una buena prediccin se ha hecho un anlisis de cmo afectan los errores de
la prediccin de la demanda en la planicacin de la produccin de energa
elctrica y los errores de la prediccin de los precios en la gestin ptima de
las ofertas de compra y venta de energa por parte de los consumidores y com-
paas de generacin, respectivamente. En lo que respecta a la literatura sobre
prediccin de estas series, ha sido la primera vez que se ha aplicado un m-
todo de estas caractersticas obtenindose resultados competitivos con otras
tcnicas e incluso en algunos casos mejores.
Estos resultados han dado lugar a las siguientes publicaciones:
Algoritmo de prediccin basado en los vecinos ms cercanos aplicado a
la prediccin de los precios. En este algoritmo la mtrica elegida es la
distancia eucldea ponderada por unos pesos, los cuales son determinados
mediante un algoritmo gentico a partir de un conjunto de entrenamien-
to. Los resultados obtenidos de su aplicacin son comparados con los
obtenidos de la aplicacin de una regresin multivariable, donde los co-
ecientes son actualizados cada vez que se predice un da del conjunto
test.
A Comparison of Two Techniques for Next-Day Electricity Price
Forecasting. IDEAL Intelligent Data Engineering and Automated
Learning. Lecture Notes in Computer Science. Vol. 2412, pp. 384-
390, Agosto 2002. Ed. Springer-Verlag. ISSN 0302-9743.
10
Introduccin
RNA aplicada a la prediccin de los precios. Los resultados obtenidos
de su aplicacin son comparados con los obtenidos de la aplicacin de
un algoritmo de prediccin basado en los vecinos ms cercanos, donde
la mtrica elegida es la distancia eucldea ponderada por unos pesos los
cuales son determinados mediante un algoritmo gentico a partir de un
conjunto de entrenamiento.
Electricity Market Price Forecasting: Neural Networks versus
Weighted-Distance k Nearest Neighbours. DEXA Database and Ex-
pert Systems Applications. Lecture Notes in Computer Science.
Vol. 2453, pp. 321-331, Septiembre 2002. Ed. Springer-Verlag. ISSN
0302-9743.
Estudio de los parmetros que afectan al algoritmo de prediccin basado
en los vecinos ms cercanos para mejorar la prediccin obtenida de los
precios de la energa y anlisis heurstico de cundo el error cometido
con este mtodo es mnimo.
Prediccin de Series Temporales Econmicas: aplicacin a los Pre-
cios de la Energa en el Mercado Elctrico Espaol. IBERAMIA
2002 VIII Iberoamerican Conference on Articial Intelligence. Works-
hop de Minera de Datos y Aprendizaje. pp. 1-11, Sevilla, Noviembre
2002. ISBN 84-95499-88-6.
Algoritmo de prediccin basado en los vecinos ms cercanos aplicado
a la prediccin de la demanda. Un estudio de los parmetros ptimos
que afectan al mtodo es analizado antes de realizar la prediccin. Los
resultados obtenidos de su aplicacin son comparados con los obtenidos
de la aplicacin de una regresin multivariable, donde los coecientes son
actualizados cada vez que se predice un da del conjunto test.
Prediccin de Series Temporales: Aplicacin a la Demanda de Ener-
ga Elctrica en el Corto Plazo. X Conferencia de la Asociacin
Espaola sobre Inteligencia Articial (CAEPIA03), San Sebastin,
Noviembre, 2003. pp. 79-88. ISBN 84-8373-564-4.
Time-Series Prediction: Application to the Short-Term Electric
Energy Demand. Lecture Notes in Articial Intelligence. Vol. 3040,
pp. 577-586, Junio 2004. ISSN 0302-9743. Edicin de trabajos se-
leccionados de CAEPIA03.
11
Captulo 1 Introduccin
Anlisis del efecto de los errores cometidos en la prediccin de los precios
en la gestin ptima de ofertas de compra/venta de energa por parte de
los clientes o compaas de generacin, respectivamente.
Inuence of ANN-Based Energy Price Forecasting Uncertainty on
Optimal Bidding. 14th Power Systems Computation Conference.
Sevilla, Junio 2002.
Anlisis del efecto de los errores cometidos en la prediccin de la de-
manda en la programacin ptima de centrales. Algoritmo de prediccin
basado en los vecinos ms cercanos, donde los resultados obtenidos de su
aplicacin son comparados con los obtenidos de la aplicacin de un rbol
de regresin (algoritmo M5 [49, 98])
Inuence of kNN-Based Load Forecasting Errors on Optimal Energy
Production. EPIA Portuguese Conference on Articial Intelligen-
ce. Lecture Notes in Articial Intelligence. Vol. 2902, pp. 189-203,
Diciembre 2003. ISSN 0302-9743.
En el marco de la optimizacin, se ha resuelto el problema de la PHCT con
un algoritmo novedoso propuesto en esta tesis, y un AG. En el AG se aporta
una nueva forma de generar la poblacin inicial para disminuir el nmero
de individuos no factibles en lo que respecta a las restricciones de rampas
de subida y bajada. La restriccin de potencia mnima ha sido modelada de
forma dinmica para considerar factibles aquellos individuos que se encuentran
en estados intermedios, arrancando o parando, estados que en la mayora
de la literatura se modelan con nuevas variables binarias. Por tanto en este AG
se usa el mnimo nmero de variables binarias, slo las correspondientes a los
estados: arrancado y parado. La evaluacin de los individuos consiste en la
resolucin de un problema de optimizacin cuadrtico mediante un algoritmo
de Punto Interior. Dado que la evaluacin de los individuos es una de las
causas del elevado coste computacional de un AG, se ha implementado el
algoritmo de Punto Interior haciendo una reordenacin de los elementos de la
matriz del sistema lineal que hay que resolver, para as disminuir el nmero de
elementos de llenado que surgen al factorizar sta y as disminuir el tiempo de
computacin del AG.
Este AG ha sido utilizado para establecer una comparacin con los resul-
tados obtenidos de la aplicacin del algoritmo que se propone en esta tesis,
al problema de la PHCT. En este algoritmo novedoso se aporta una nueva
tcnica de bsqueda global de la solucin de un problema de optimizacin no
lineal no convexo, obtenindose una sucesin decreciente de mnimos locales
del problema.
12
Introduccin
Estas contribuciones han dado lugar a las siguientes publicaciones:
Programa de optimizacin basado en un algoritmo de Punto Interior
aplicado a la PHCT, suponiendo la programacin de arranques y paradas
conocida, es decir sin variables discretas. Los resultados obtenidos de la
aplicacin de este algoritmo a un sistema real son comparados con los
obtenidos de la aplicacin de un algoritmo de Punto Interior Predictor-
Corrector [138].
Despacho Econmico de Centrales Trmicas e Hidrulicas en el
Corto Plazo Mediante Tcnicas de Punto Interior. 7
a
Jornadas
Hispano-Lusas de Ingeniera Elctrica. Madrid, 2001. Vol. III, pp.
261-266. ISBN 84-95821-03-6.
Algoritmo evolutivo aplicado a la PHCT para determinar la programa-
cin de arranques y paradas. La evaluacin de los individuos se obtiene
mediante la resolucin de un problema de optimizacin con un algoritmo
de Punto Interior donde todas las variables son continuas.
Short-term Hydro-thermal Coordination Based on Interior Point
Nonlinear Programming and Genetic Algorithms. IEEE Power Te-
ch2001 Conference. Oporto, Portugal, 2001. Vol. 3, PSO2-267. ISBN
0-7803-7139-9.
Aplicacin de Tcnicas de Computacin Evolutiva a la Planica-
cin ptima de la Produccin de Energa Elctrica en el Corto Pla-
zo. V Jornadas de Transferencia Tecnolgica de Inteligencia Arti-
cial (TTIA03), San Sebastin, Noviembre, 2003. pp. 419-428. ISBN
84-8373-564-4
Application of Evolutionary Computation Techniques To Optimal
Short-Term Electric Energy Production Scheduling. Lecture Notes
in Articial Intelligence. Vol. 3040, pp. 656-665, Junio 2004. ISSN
0302-9743. Edicin de trabajos seleccionados de TTIA03.
Algoritmo para la resolucin de problemas de optimizacin no lineales y
no convexos con mltiples mnimos locales.
Finding Improved Local Minima of Power System Optimization
Problems by Interior-Point Methods. IEEE Transactions on Power
System. Vol. 18, n
o
1, pp. 238-244, Febrero 2003. ISSN 0885-8950.
13
Captulo 1 Introduccin
1.4. Estructura de la Memoria
La memoria de esta tesis se organiza como sigue:
En el Captulo 2, en primer lugar se hace un recorrido por las contribuciones
ms relevantes que han aparecido en la literatura sobre anlisis y prediccin
de series temporales. Los mtodos ms utilizados para la prediccin de series
temporales se pueden clasicar a grandes rasgos en dos grupos: los mtodos es-
tadsticos clsicos y las tcnicas de aprendizaje automtico. Entre los mtodos
estadsticos se han destacado los modelos ARMA y ARIMA y las tcnicas de
aprendizaje automtico descritas han sido los rboles de regresin, los sistemas
de prediccin basados en reglas, la programacin gentica, las redes neurona-
les articiales y los vecinos ms cercanos. De una forma paralela, se analizan
trabajos donde se usan estas tcnicas aplicadas a la prediccin de los precios y
la demanda de energa elctrica. En segundo lugar, se describen los algoritmos
de optimizacin ms conocidos en la literatura y se hace un breve recorrido
por las contribuciones que han aparecido de su aplicacin a la PHCT.
La tcnica de clasicacin y reconocimiento de patrones basada en la bs-
queda de los vecinos ms cercanos aplicada a la prediccin de una serie tem-
poral es descrita en el Captulo 3. Primero, se analiza cul es la forma ptima
de representar el conjunto de datos de entrada y se estudia la inuencia de dos
parmetros que afectan a dicho algoritmo: el nmero de vecinos, es decir el
nmero de ejemplos que sern usados en el momento de efectuar la prediccin,
y la mtrica elegida como medida de similitud entre dos ejemplos del conjunto
de datos. Despus, se analiza de forma heurstica cul es el error mnimo que
se comete en la prediccin de una serie temporal con este mtodo.
En los Captulos 4 y 5 se presentan los resultados obtenidos al aplicar el
mtodo descrito en el Captulo 3 a dos series temporales reales: los precios
y la demanda de energa en el Mercado Elctrico Espaol. En primer lugar,
se obtienen los modelos de prediccin para ambas series, que consiste bsica-
mente en determinar la estructura ptima del conjunto de datos de entrada
y los parmetros que afectan al mtodo. En segundo lugar, se presentan los
resultados obtenidos de la prediccin de ambas series, comparndose con los
resultados obtenidos de la aplicacin de una red neuronal en el caso de la serie
temporal formada por los precios y los obtenidos de la aplicacin de un rbol
de regresin en el caso de la serie temporal formada por la demanda.
El objeto del Captulo 6 es la resolucin de problemas de optimizacin con
restricciones, donde la funcin objetivo y las restricciones tanto de igualdad
como de desigualdad son no lineales y no convexas. En primer lugar, se describe
el modelo matemtico de un problema de estas caractersticas cuando todas
las variables son reales y varan de una forma continua, y se propone un nuevo
14
Introduccin
mtodo que resuelve el problema de manera eciente, con una ventaja frente
a los mtodos existentes: su habilidad de escapar de un mnimo local. En
segundo lugar, se describe el modelo matemtico cuando las variables son reales
y enteras y se propone un mtodo de resolucin que consiste bsicamente en
relajar el carcter discreto de las variables y aplicar el mtodo propuesto en el
caso anterior. Por ltimo, se presentan dos ejemplos tutoriales para ilustrar el
comportamiento de los mtodos presentados en este captulo.
En el Captulo 7 se aplica el mtodo propuesto en el Captulo 6 a un
problema real: la planicacin de la produccin de energa elctrica. Primero,
el problema es modelado dando lugar a un problema no lineal no convexo, el
cual es resuelto haciendo especial nfasis en la reordenacin de las matrices
resultantes para mejorar el tiempo de computacin del algoritmo. Por ltimo,
se presentan resultados obtenidos de la aplicacin del mtodo propuesto en el
Captulo 6 a dos casos de estudio basados en el parque de generacin espaol,
un sistema test de pequea dimensin y un sistema realista de gran dimensin.
Los resultados obtenidos se comparan con los obtenidos de la aplicacin de un
AG.
Por ltimo, el Captulo 8 recoge las principales conclusiones del traba-
jo realizado en el mbito de la presente tesis, proponiendo asimismo futuros
desarrollos y lneas de investigacin.
A continuacin se incluyen los siguientes apndices:
En el Apndice A se muestran los rboles de regresin y los modelos lineales
obtenidos en las hojas de los rboles mediante el algoritmo M5 con y sin
seleccin de atributos.
El Apndice B muestra los datos de entrada utilizados en los casos de
estudio presentados en el Captulo 7.
El Apndice C presenta las programaciones de arranques y paradas y las
potencias de salida de las mejores soluciones obtenidas de la aplicacin del AG
desarrollado en el Captulo 7, y la aplicacin del procedimiento propuesto en
el Captulo 6 de esta tesis basado en tcnicas de Punto Interior al problema
de la PHCT para los dos casos de estudio analizados, cuyos datos de entrada
se describen en el Apndice B.
El Apndice D muestra las ecuaciones y la estructura por bloques de la
matriz del sistema lineal resultante de la aplicacin de un algoritmo Primal-
Dual de Punto Interior a los subproblemas, tanto continuos como discretos,
que aparecen de la aplicacin del mtodo propuesto en el Captulo 6 a la
planicacin de la produccin de energa elctrica.
15
Captulo 1 Introduccin
16
Captulo 2
Estado del Arte
En este captulo se hace un recorrido por las contribuciones ms relevan-
tes que han aparecido en la literatura sobre anlisis y prediccin de series
temporales y su aplicacin a la prediccin de los precios y la demanda de ener-
ga elctrica, y sobre algoritmos de optimizacin y su aplicacin a la PHCT,
respectivamente.
2.1. Minera de Datos
Aunque la idea de MD parece estar generalmente aceptada en la comuni-
dad cientca, no existe una denicin clara de este trmino. Informalmente,
podramos denir la minera de datos como el anlisis de bases de datos con el
n de descubrir o extraer informacin inherente a los datos objeto de anlisis,
de modo que sea de utilidad en la toma de decisiones. Tal informacin puede
venir representada como patrones, relaciones, reglas, asociaciones, dependen-
cias o incluso excepciones entre los datos analizados. El desarrollo tecnolgico
ha permitido que la creciente cantidad de informacin que diariamente se ge-
nera en el mundo, pueda ser transferida de forma casi instantnea, as como
almacenada en grandes bases de datos. La competitividad existente hoy da en
campos como la economa, el comercio, la industria y la propia ciencia entre
otros, ha fomentado el aprovechamiento de esta informacin para la toma de
decisiones. Tradicionalmente, la estadstica ha cubierto este campo, ofrecien-
do resmenes de los datos en forma de medias, desviaciones, distribuciones,
correlaciones, entre otras muchas medidas. Sin embargo, el simple estudio es-
tadstico de esta cantidad de informacin resulta insuciente para la toma de
decisiones, pues aporta un conocimiento muy limitado del comportamiento de
los datos. Adems de las medidas estadsticas, la informacin oculta patrones
y relaciones inherentes de gran utilidad y que la minera de datos se encarga de
17
Captulo 2 Estado del Arte
extraer mediante un algoritmo de aprendizaje automtico adecuado. La gura
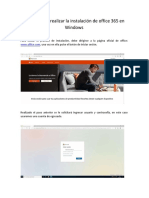
2.1 muestra un esquema ms detallado sobre las fases existentes en MD.
Algoritmo
de
Aprendizaje
MODELO
Validacin
APRENDIZAJE
Datos
de
Entrada
P
R
E
D
I
C
C
I
O
N
MINERA
xx xx xxxxx
xx xx xxxxx
xx xx xxxxx
xx xx xxxxx
Figura 2.1: Fase de Minera de Datos
El Aprendizaje Automtico (Machine Learning) es la rama de la Inteligen-
cia Articial que estudia el desarrollo de tcnicas para extraer de forma auto-
mtica conocimiento subyacente en los datos. Uno de los modelos de aprendi-
zaje ms estudiados es el aprendizaje inductivo, el cual engloba todas aquellas
tcnicas que aplican inferencias inductivas sobre un conjunto de datos para
adquirir el conocimiento inherente a ellos. Existen principalmente dos tipos de
aprendizaje inductivo: supervisado y no supervisado. En el aprendizaje super-
visado, los casos pertenecientes al conjunto de datos tienen a priori asignada
una clase o categora, siendo el objetivo encontrar patrones o tendencias de los
casos pertenecientes a una misma clase. Sin embargo, el aprendizaje no super-
visado no goza de una agrupacin de los casos previa al aprendizaje, por lo que
se limita a buscar la regularidades entre stos. Los mtodos de prediccin que
se analizan en esta seccin se clasican bsicamente en dos grandes grupos: las
tcnicas de aprendizaje supervisado y las tcnicas estadsticas.
2.2. Preprocesado de Series Temporales
Esta seccin se centra en la etapa previa a la prediccin de una serie tempo-
ral conocida como etapa de preprocesado en la cual se aplican tcnicas espec-
cas para estudiar la calidad de los datos. Una serie temporal es una sucesin
de observaciones de una variable en distintos momentos de tiempo. Aunque
el tiempo es una variable continua, en la prctica se usan mediciones en pe-
riodos equidistantes. El anlisis de series temporales ha sido un campo de
18
Estado del Arte
investigacin desde principios del siglo XX, actualmente en alza con el reciente
desarrollo de las tcnicas de aprendizaje automtico. Los aspectos claves en el
anlisis de series temporales son el preprocesado de datos y la obtencin del
modelo de prediccin. En la preparacin de los datos se pueden destacar la
reduccin del ruido mediante la deteccin de outliers, la reduccin de datos
mediante tcnicas de seleccin de atributos y la discretizacin de valores conti-
nuos. A continuacin se describen brevemente en qu consisten estas tcnicas
que tienen lugar en la etapa previa de preparacin de los datos.
Deteccin de outliers: Los outliers son valores de la serie temporal que
se alejan de los patrones de comportamiento del resto de la serie. Estas des-
viaciones pueden ser debidas bien a la ocurrencia de algn hecho no previsible
o bien a mecanismos de mercado como es el caso de las series temporales eco-
nmicas o nancieras. Para mitigar los efectos del ruido en el aprendizaje se
aplican las denominadas tcnicas de suavizado (smoothing). El mtodo de sua-
vizado ms sencillo, conocido como binning, consiste en reemplazar los outliers
por la media, mediana o moda de los valores precedentes y siguientes. En [2]
se describe un detector automtico de distintas caractersticas que suelen pre-
sentar las series temporales como los outliers, el nivel de las discontinuidades,
los cambios en la tendencia... Para la deteccin de los outliers se observan las
segundas diferencias de los valores de la serie, un valor grande para alguna
de estas segundas diferencias indica la presencia de un outlier en ese punto o
en el punto precedente. Los patrones de los residuos de una regresin pueden
conrmar la presencia de un outlier, puesto que la presencia de un incremento
o decremento abrupto en los residuos justo en el punto precedente al punto
donde las diferencias de segundo orden son grandes indica la presencia de un
outlier. Una vez detectados los outliers son reemplazados por la media de los
valores precedentes y siguientes de la serie.
Tcnicas de Reduccin: Los algoritmos de seleccin de caractersticas e
indexado tienen dos objetivos principales: reducir el coste computacional aso-
ciado tanto al aprendizaje como al propio modelo de conocimiento generado
(eliminando atributos irrelevantes o redundantes) y aumentar la precisin de
dicho modelo (eliminando atributos perjudiciales para el aprendizaje). En [89]
se presenta un modelo que permite determinar de manera dinmica qu valo-
res previos inuyen en el valor actual observado en una serie temporal. Una
de las ventajas del modelo propuesto es que permite capturar la existencia de
distintas relaciones temporales en cada hora. El modelo de seleccin de va-
riables descrito se ha aplicado a un problema real para determinar las horas
previas que inuyen en el valor de radiacin solar sobre supercie recibido en
una hora determinada. En [108] se presenta una tcnica de seleccin de atri-
butos que utiliza una medida basada en proyecciones para guiar la seleccin
19
Captulo 2 Estado del Arte
de los atributos que sean relevantes. Esta tcnica tiene algunas caractersticas
interesantes como su bajo coste computacional y su aplicabilidad a conjuntos
de datos que contengan tanto variables continuas como discretas. En [62] se
presenta un algoritmo de indexado que da lugar a una reduccin de la dimen-
sionalidad lo que hace que se pueda efectuar una bsqueda ms rpida de la
similaridad entre dos curvas. Esta tcnica de reduccin de datos se muestra en
el siguiente ejemplo: sea X una serie temporal formada por 8 valores, es decir:
X = (1, 2, 1, 0, 2, 1, 1, 0) (2.1)
Entonces la serie temporal se divide en un nmero determinado de subcon-
juntos y se proyecta en esos subconjuntos usando para ello las medias de los
valores que corresponden a cada subconjunto. En este caso la serie temporal
se proyecta en dos dimensiones de la siguiente forma:
X = (1, 1) (2.2)
donde -1 es la media de los 4 primeros valores de la serie y 1 es la media de
los 4 ltimos valores de la serie.
Discretizacin: Un gran nmero de algoritmos de aprendizaje operan ex-
clusivamente con espacios discretos. Sin embargo, muchas bases de datos con-
tienen atributos de dominio continuo, lo que hace imprescindible la aplicacin
previa de algn mtodo que reduzca la cardinalidad del conjunto de valores,
dividiendo su rango en un conjunto nito de intervalos. Esta trasformacin de
atributos continuos en discretos se denomina discretizacin. En [88] se propo-
nen dos mtodos de discretizacin dinmicos y cualitativos para transformar
los valores continuos de una serie temporal en valores discretos. Estos mtodos
son dinmicos puesto que el valor discreto asociado a un determinado valor
continuo puede cambiar con el paso del tiempo, es decir el mismo valor con-
tinuo puede ser discretizado con distintos valores dependiendo de los valores
previos de la serie y son cualitativos porque slo aquellos cambios los cuales son
cualitativamente signicativos aparecen en la serie discretizada. Un mtodo se
basa en el t-estadstico ya que se pretende usar toda la informacin estadstica
de los valores previos observados de la serie para seleccionar los valores dis-
cretos que corresponden a un nuevo valor continuo de la serie. El otro mtodo
propuesto se basa en la denicin de una distancia que mide la relacin entre
valores consecutivos de la serie. Entonces dos valores continuos consecutivos
corresponden al mismo valor discreto cuando la distancia entre ellos es menor
que un determinado umbral. A continuacin se har un breve recorrido por los
mtodos ms usados en la literatura para la prediccin de series temporales,
centrando la atencin en aquellos que han sido usados para la prediccin de
los precios de la energa y la prediccin de la demanda de energa elctrica.
20
Estado del Arte
2.3. Mtodos de Prediccin
La mayora de los mtodos de prediccin estn basados en el descubrimiento
de patrones regulares que ayuden a la obtencin de un modelo para realizar
predicciones de futuro sobre el comportamiento de una serie. El descubrimiento
de patrones ha estado sujeto a una gran investigacin en las ltimas dcadas
[60]. Sin embargo la alta correlacin entre los atributos, la alta dimensionalidad
y la gran cantidad de ruido que caracteriza a las series temporales ha hecho
que la mayora de los investigadores se centren en encontrar una nueva medida
de la similaridad entre dos curvas para mejorar un algoritmo de clustering ya
existente [61]. En [94] para descubrir patrones de comportamiento similares
en un conjunto de series temporales se propone un algoritmo de aprendizaje
incremental que intenta identicar en qu conjuntos se distingue una serie
temporal de otra habiendo sido las dos generadas a partir del mismo proceso.
2.3.1. Prediccin basada en reglas
En general, una regla de decisin es una regla del tipo Si P Entonces
C, donde P es un predicado lgico sobre los atributos, cuya evaluacin cierta
implica la clasicacin con etiqueta de clase C. Desde el punto de vista de la
interpretacin humana, esta representacin del conocimiento resulta a menudo
ms clara que los rboles de decisin, sobre todo en aplicaciones reales donde el
nmero de nodos de stos tiende a aumentar. Esto es debido tanto a la propia
estructura como a las tcnicas utilizadas para generar stas. La construccin
de los rboles de decisin se basa en una estrategia de divisin, esto es, dividir
el conjunto de datos en dos subconjuntos considerando un nico atributo selec-
cionado por una heurstica particular. Por el contrario, el aprendizaje de reglas
sigue una estrategia de cobertura, esto es, encontrar condiciones de reglas te-
niendo en cuenta todos los atributos de forma que se cubra la mayor cantidad
de ejemplos de una misma clase, y la menor del resto de las clases. Existe
una extensa literatura sobre cmo generar reglas para posteriormente usarlas
en un problema de prediccin. Algunas contribuciones estn relacionadas con
la forma de generarlas [38] y otras se centran en la estructura a partir de la
cual se generan, bien un rbol de regresin [49] bien a partir de la etapa de
entrenamiento de una red neuronal [111]. La teora de conjuntos difusos relaja
el concepto de pertenencia de un elemento a un conjunto. En la teora tradi-
cional, un elemento simplemente pertenece o no a un conjunto. Sin embargo,
en la teora de conjuntos difusos, un elemento pertenece a un conjunto con un
cierto grado de certeza. Aplicando esta idea, el uso de la lgica difusa permite
un mejor tratamiento de la informacin cuando sta es incompleta, imprecisa
21
Captulo 2 Estado del Arte
o incierta. Por ello, ha sido aplicada por muchos autores en tareas de predic-
cin y deteccin de fallos, usando a menudo reglas difusas como representacin
del conocimiento [6]. Estos sistemas son denominados tradicionalmente Fuzzy
Rule-Based Classication Systems. En la literatura se pueden encontrar al-
gunas aplicaciones a la prediccin de series nancieras usando reglas difusas
extradas a partir de algoritmos genticos. En [64] se propone un mtodo de
prediccin basado en un conjunto de reglas difusas para series caticas y no
estacionarias. En una primera etapa se genera mediante un algoritmo genti-
co un conjuntos de reglas difusas que cubran el nmero mximo de ejemplos
del conjunto de entrenamiento. En una segunda etapa las funciones miembro
del conjunto de reglas obtenidas en la etapa previa se ajustan mediante un
algoritmo gentico de manera que el error de prediccin sea mnimo. Estas dos
etapas son repetidas para distintas particiones del conjunto de entrenamiento
obteniendo as un conjunto de predictores difusos. Finalmente, la prediccin de
un valor de la serie es una combinacin lineal de las predicciones obtenidas a
partir del conjunto de predictores difusos ponderada por unos pesos que vienen
dados por:
w
i
=
1
|P|
j=1
1
j
(2.3)
donde |P| es el nmero de predictores difusos y
i
es la desviacin estndar
del error de prediccin obtenido a partir del predictor difuso i. Este mtodo se
ha aplicado a la serie temporal catica de Mackey-Glass y a la prediccin del
cambio del franco suizo frente al dlar.
2.3.2. Mtodos Lineales
Los mtodos de prediccin lineales son aquellos que intentan modelar el
comportamiento de una serie temporal mediante una funcin lineal. Entre estos
mtodos se destacan los modelos ARMA y ARIMA y los rboles de regresin.
2.3.2.1. Metodologa de Box and Jenkins
En esta seccin se describen dos modelos lineales para el anlisis de series
temporales: el modelo ARMA y el modelo ARIMA. Estos modelos son una
clase de procesos estocsticos y tienen una metodologa comn, cuya aplicacin
al anlisis de series temporales se debe a Box y Jenkins [13]. Para construir
ambos modelos se siguen los pasos siguientes:
1. Identicacin del modelo bajo ciertas hiptesis
2. Estimacin de parmetros
22
Estado del Arte
3. Validacin del modelo
4. Prediccin
2.3.2.1.1. Modelos ARMA
Un proceso estacionario es aquel cuya media, varianza y covarianza son cons-
tantes. Los modelos de prediccin de series temporales estn diseados para
procesos estacionarios, aunque en el mundo real la mayora de las series tempo-
rales, sobre todo las nancieras, no son estacionarias. Un proceso estocstico
estacionario con una componente autoregresiva (AR) y una componente de
medias mviles (MA) se puede modelar como sigue:
(B)X
t
= (B)
t
(2.4)
donde:
X
t
es la variable que se quiere predecir en la hora t, es decir, se trata de
una serie horaria.
t
es un ruido blanco en la hora t, que representa los errores y otorga el
carcter aleatorio a la serie.
(B) y (B) son funciones polinomiales del operador de retardos B que
vienen denidos por:
(B) = 1
n
l=1
l
B
l
(2.5)
(B) = 1
m
l=1
l
B
l
(2.6)
B
l
X
t
= X
tl
(2.7)
donde n es el orden del proceso Autoregresivo (AR) y m es el orden del
proceso de Medias Mviles (MA).
Una vez determinado el modelo se trata de determinar los parmetros n, m,
l
y
l
. Tradicionalmente, los parmetros n y m se calculan mediante la funcin de
autocorrelacin y la funcin de autocorrelacin parcial [128] y los parmetros
l
y
l
se hallan mediante la resolucin de un problema de optimizacin donde
la funcin objetivo es el error cuadrtico medio cometido en la prediccin. Co-
mo esta funcin objetivo tiene mltiples mnimos locales no se garantiza que
el mnimo encontrado sea el mnimo global. Para evitar esto, algunos autores
23
Captulo 2 Estado del Arte
[141] han usado algoritmos evolutivos en la fase de estimacin de parmetros
tanto para determinar
l
y
l
como los rdenes n y m para la prediccin
de la demanda de energa elctrica. En otras reas, como la biomedicina, la
bsqueda de los parmetros ptimos de un modelo ARMA se ha basado en
tcnicas geomtricas [71]. Una vez determinados todos los parmetros, el mo-
delo es validado mediante algunos test estadsticos y observando la funcin de
autocorrelacin y la funcin de autocorrelacin parcial de los residuos.
2.3.2.1.2. Modelos ARIMA
Cuando una serie temporal no es estacionaria se suelen aplicar una serie de
transformaciones que hagan que la serie sea estacionaria. Entre estas transfor-
maciones, una de las ms simples es aplicar el operador diferencias tantas veces
como haga falta. As, un modelo ARIMA tradicional consiste en aplicar un mo-
delo ARMA a la serie temporal
d
X
t
donde
d
son las diferencias de orden d.
El parmetro d se determina de tal forma que la serie
d
X
t
sea estacionaria.
El resto de parmetros se determinan como se ha descrito anteriormente en
los modelos ARMA. Los modelos ARIMA y algunas modicaciones de estos
modelos han sido muy usados para la prediccin de la demanda de energa elc-
trica, dando una especial importancia a la prediccin de las horas en las que
la demanda es alta (horas punta). En [5] se presenta una modicacin de un
modelo ARIMA para predecir la demanda horaria y la demanda en las horas
punta del sistema Iran. Esta modicacin consiste en aadir un nico trmino
al modelo el cual representa una primera aproximacin de la prediccin de
la demanda y se obtiene a travs de un operador tcnico. As la estimacin
de la demanda que hace el operador es incluida en el modelo ARIMA como
un trmino ms y en la fase de clculo de parmetros este nuevo trmino se
trata como un dato de entrada. Adems antes de aplicar el modelo ARIMA
se hace una clasicacin de la demanda iran a partir de un estudio estads-
tico obteniendo modelos ARIMA distintos segn el tipo de da que se quiera
predecir. Desde un punto de vista matemtico, esta modicacin consiste en
usar la estimacin de los operadores como una prediccin inicial lo que hace
que se obtengan mejores resultados que los obtenidos con un modelo ARIMA
clsico. La demanda horaria y la demanda de las horas punta del sistema ira-
n en el ao 1998 se predicen con un error absoluto medio en porcentaje de
1.7 % y 4.65 % respectivamente. Tanto a los modelos ARMA como ARIMA se
les pueden aadir variables exgenas que inuyan en la serie temporal, como
por ejemplo la temperatura cuando se trata de predecir la demanda de ener-
ga elctrica o la demanda de energa elctrica cuando se trata de predecir los
precios de la energa. En [141] se presenta un modelo ARMA para predecir la
demanda de Taiwan en algunas semanas del ao 1992. En este modelo se usan
24
Estado del Arte
como datos de entrada la temperatura actual y la temperatura de horas ante-
riores. Para el clculo de los rdenes del proceso autoregresivo y del proceso de
medias mviles y para determinar el nmero de valores pasados de la tempe-
ratura que se necesitan en el modelo se implementa un algoritmo gentico. La
estimacin de los parmetros tambin se lleva a cabo mediante un algoritmo
gentico. El clculo de los parmetros ptimos se obtiene minimizando el error
cuadrtico obtenido al realizar la prediccin en un conjunto de entrenamiento.
La principal desventaja de esta funcin error es la presencia de mltiples m-
nimos lo que hace que los mtodos de optimizacin basados en el gradiente no
obtengan un modelo adecuado puesto que pueden obtener como solucin un
ptimo local. Para solucionar esto se usa un algoritmo evolutivo que hace una
bsqueda global del espacio, no necesita que la funcin que se minimiza sea
diferenciable y es capaz de converger asintticamente hacia el ptimo global.
Se presentan los resultados de la prediccin de la demanda en cuatro sema-
nas laborables de distintas estaciones del ao: desde el da 10 hasta el da 14
de agosto, desde el da 27 hasta el da 31 de Enero, desde el da 12 hasta el
da 16 de Octubre y desde el da 23 hasta el da 27 de marzo, obteniendo en
esas semanas unos errores relativos medios de 1.5 %, 1.17 %, 1.28 % y 0.98 %
respectivamente. En [93] se presentan dos modelos para obtener la prediccin
de los precios de la energa en el Mercado Elctrico Espaol y en el Merca-
do Elctrico Californiano. Ambos modelos incluyen como variable exgena la
demanda de energa y son obtenidos mediante una regresin dinmica y una
funcin de transferencia, respectivamente. Los resultados se muestran en dos
semanas concretas del ao 2000 con el n de semana incluido para el mercado
elctrico espaol: una semana tpica de demanda baja (desde el 21 hasta el 27
de agosto) y una semana tpica de demanda alta (desde el 13 hasta el 19 de
noviembre) y para el mercado elctrico californiano los resultados se muestran
en una semana de abril (desde el da 3 hasta el 9). En las semanas elegidas
para validar ambos modelos se obtienen unos errores relativos medios de 5 %
en el mercado espaol y de 3 % en el mercado californiano, no existiendo un
mejor comportamiento de un modelo frente al otro. Cuando una serie no es es-
tacionaria pero el valor esperado de la serie s tiene un comportamiento cclico,
se dice que la serie es estacional. Por ejemplo, una serie horaria es estacional
si toma valores similares a las 8 de la maana de todos los das. Un modelo
ARIMA estacional consiste en un modelo ARIMA multiplicado por factores
de la forma (1 B
s
) donde s es un parmetro que indica la estacionalidad de
la serie (24 en el caso de estacionalidad diaria, 168 en el caso de estacionalidad
mensual...). Los modelos ARIMA estacionales han sido aplicado recientemente
a la serie temporal formada por los precios de la energa en el Mercado Elc-
trico Espaol y Californiano. En [31] se presentan tres mtodos aplicados a la
25
Captulo 2 Estado del Arte
prediccin de los precios de la energa en ambos mercados elctricos: una re-
gresin dinmica, una funcin de transferencia y un modelo ARIMA estacional
en el que se usa como una variable exgena la demanda de energa. Los resul-
tados se muestran en dos semanas concretas del ao 2001 con el n de semana
incluido para el mercado elctrico espaol: una semana tpica de demanda ba-
ja (desde el 25 hasta el 31 de agosto) y una semana tpica de demanda alta
(desde el 11 hasta el 17 de mayo) y para el mercado elctrico californiano los
resultados se muestran en una semana de abril del ao 2000 (desde el da 3
hasta el 9). En las semanas elegidas para validar los tres mtodos se obtienen
en el mercado espaol unos errores relativos medios de 5 % cuando se usa una
regresin dinmica o funcin de transferencia y unos errores relativos medios
de 8 % cuando se usa un modelo ARIMA estacional sin variable exgena. En el
mercado californiano se obtienen unos errores relativos medios de 3 % cuando
se usa una regresin dinmica o funcin de transferencia y unos errores rela-
tivos medios de 5 % cuando se usa un modelo ARIMA estacional sin variable
exgena. Tambin se muestran los resultados obtenidos en el mercado espaol
al predecir los precios de la energa en la ltima semana de los primeros 10
meses del ao 2000 con dos modelos ARIMA estacionales, uno que no usa va-
riables exgenas y otro que usa como variables exgenas: la demanda, el agua
almacenada y la produccin de energa disponible por las centrales hidruli-
cas. En este caso ambos modelos se comportan de una manera parecida ya
que se obtienen errores relativos medios de 10.89 % sin ningn tipo de variable
adicional y 10.45 % aadiendo las variables exgenas anteriormente citadas.
En [22] la prediccin de los precios de la energa se basa en modelos ARIMA
estacionales tanto con variables explicativas como sin ellas. Para el mercado
espaol los resultados se muestran en tres semanas concretas elegidas del ao
2000 y en la ltima semana de los primeros 10 meses del ao 2000 dando lugar
a unos errores medios relativos de 10 % independientemente de que se usen o
no se usen algunas variables adicionales.
2.3.2.2. rboles de Regresin
Un rbol de regresin se puede interpretar como una regresin lineal por
trozos ya que las hojas de estos rboles contienen distintas rectas de regresin.
Por tanto, un ejemplo recorrer el rbol hasta alcanzar una determinada hoja
y la recta de regresin que sta contenga ser el modelo de prediccin usa-
do para estimar el atributo deseado. Los problemas de clasicacin donde los
valores de los atributos son etiquetas han sido resueltos mediante algoritmos
de aprendizaje que generan rboles de decisin los cuales han resultado ser
robustos, ecientes y simples [99]. En un rbol de decisin, cada nodo interno
26
Estado del Arte
establece una condicin o conjunto de condiciones sobre uno o varios atributos,
representando en cada rama saliente el cumplimiento de una de esas condicio-
nes. Cada hoja contiene una etiqueta de clase indicando la clasicacin. La
clasicacin de un ejemplo se lleva a cabo recorriendo el rbol desde la raz
hasta una de las hojas, siguiendo el camino determinado por el cumplimiento
de las condiciones. El ejemplo se clasica con la etiqueta contenida en el nodo
hoja alcanzado nalmente. En la ltima dcada se ha intentado extender los
algoritmos de aprendizaje que generan rboles de decisin para predecir valores
de atributos cuando stos son numricos. As, surgen los rboles de regresin
que son rboles de decisin pero dieren de stos en que en las hojas del rbol
en lugar de tener clases tienen valores, el algoritmo ms popular que construye
rboles de regresin es conocido como CART [14], en el cual el valor de la pre-
diccin en cada hoja es el valor medio de todos los ejemplos de un conjunto de
entrenamiento que alcanzan esa hoja. Basndose en los rboles de regresin, el
algoritmo M5 [98] construye rboles en cuyas hojas tiene modelos lineales de
varias variables, lo que se conoce con el nombre de model tree. Estos rboles
son as anlogos a funciones lineales a trozos y el algoritmo M5 extiende al
algoritmo CART en el sentido de que ste es un caso particular de estos rbo-
les cuando las funciones lineales consideradas son constantes. Bsicamente, los
algoritmos CART y M5 construyen un rbol inicial mediante un algoritmo de
induccin de rboles de decisin. Sin embargo, en los rboles de decisin los
cortes se determinan maximizando la ganancia de informacin mientras que
en estos algoritmos los puntos de corte se determinan maximizando la reduc-
cin de la varianza puesto que es ms apropiado en un problema de prediccin
numrica. En [118] se aplica el algoritmo M5 a la prediccin de cinco series
temporales industriales obteniendo los doce siguientes valores de dichas series
con unos errores absolutos medios de 21.5, 1.39, 4.46, 263.08 y 242.35 respecti-
vamente. Estos resultados muestran muy buena aproximacin para la segunda
serie temporal frente a los malos resultados obtenidos para las dos ltimas se-
ries. Estas series industriales son muy pequeas pues estn formadas por 100
ejemplos lo cual es una desventaja ya que el nmero tan pequeo de ejemplos
puede afectar a la capacidad de aprendizaje del algoritmo. En [132] se describe
un algoritmo, llamado M5, que se basa en el algoritmo M5, ya que tambin
construye un rbol en cuyas hojas se obtiene una funcin lineal de los atributos
y se presentan resultados donde se establece una comparacin entre ambos al-
goritmos mostrando el algoritmo M5 una mayor capacidad de prediccin que
el algoritmo M5. El algoritmo M5 combina la idea de construccin de un rbol
adoptada del algoritmo M5 con un mtodo para el tratamiento de los valores
perdidos y un mtodo para la transformacin de atributos cuyos valores son
etiquetas en atributos cuyos valores sean 0 1, puesto que ambas caracters-
27
Captulo 2 Estado del Arte
ticas tanto la presencia de atributos sin valor como la mezcla de atributos no
numricos con atributos numricos se suelen dar en las series temporales reales.
Los algoritmos para tratar estas dos caractersticas de las series han sido adop-
tados del algoritmo CART. El algoritmo M5 ha sido usado en esta tesis para
establecer una comparacin entre los resultados obtenidos de su aplicacin con
los obtenidos de la aplicacin del mtodo de prediccin propuesto basado en
los vecinos ms cercanos a la prediccin de la demanda de energa elctrica. En
[90] se genera un rbol de regresin cuyos cortes en los nodos se determinan
asignando dos funciones difusas al valor de corte determinado por el algoritmo
CART y que representan los lados izquierdo y derecho del subrbol que cuelga
de ese nodo. Estos rboles de regresin difusos clasican los datos de entrada
de una red neuronal con la que se predice la demanda maxima diaria para los
meses comprendidos entre junio y septiembre del ao 1999 obtenindose un
error medio de 1.67 % y un mximo error de 4.20 %.
2.3.3. Mtodos no Lineales
Los mtodos de prediccin no lineales son aquellos que intentan modelar el
comportamiento de una serie temporal mediante una funcin no lineal. Esta
funcin no lineal suele ser combinacin lineal de funciones no lineales cuyos
parmetros hay que determinar.
2.3.3.1. Mtodos Globales
Los mtodos globales se basan en encontrar una funcin no lineal que mode-
le los datos de salida en funcin de los datos de entrada. Dentro de los mtodos
globales no lineales se encuentran las RNA que presentan la ventaja de que no
necesitan conocer la distribucin de los datos de entrada y la Programacin
Gentica (PG) donde se puede elegir qu tipo de funcin no lineal modela el
comportamiento de los datos.
2.3.3.1.1. Redes Neuronales Articiales
La teora de redes neuronales est inspirada en los conocimientos existentes
del funcionamiento del sistema nervioso de los seres vivos. A partir de ste,
surgen modelos que intentan simular el proceso de aprendizaje de las neuronas
interconectadas en el cerebro. Para ello se denen una serie de capas, donde
cada una tiene un nmero determinado de nodos que se relacionan con la capa
anterior. La primera capa se llama vector de entrada, que toma los datos del
chero de aprendizaje y la ltima capa se denomina vector de salida. Las redes
se pueden dividir segn el tipo de aprendizaje en tres grupos: con aprendizaje
28
Estado del Arte
supervisado, redes auto-organizadas con aprendizaje no supervisado y redes
hbridas que tratan de explotar las ventajas de los dos modelos anteriores.
Los paradigmas ms extendidos dentro de cada uno de estos tipos de apren-
dizaje son: el perceptrn multicapa [107] donde el algoritmo de aprendizaje
utiliza una tcnica de bsqueda por gradiente y los pesos de la funcin que
relaciona el vector de salida con el de entrada se calculan con un algoritmo de
retropropagacin (feedforward) [109], las redes auto-organizadas [65] y la red
de funcin de base radial (Radial Basis Function, RBF) [87]. Recientemente
distintas arquitecturas y tipos de redes neuronales han sido aplicadas al pro-
blema de la prediccin de la demanda [46] y los precios [143] para las 24 horas
del da siguiente. En [110] se implementa una red neuronal perceptron mul-
ticapa con dos capas intermedias para la prediccin del pico de demanda en
el sistema elctrico indio. En el aprendizaje de esta red se emplean distintas
tcnicas de descenso del gradiente conjugado: mtodo del gradiente conjugado
de Fletcher-Reeves, mtodo del gradiente conjugado de Polak-Ribiere, mto-
do del gradiente conjugado de Powell-Beale y mtodo del gradiente conjugado
escalado. El nmero de datos de entrada de la red son 28 y este nmero es
reducido hasta 11 mediante un anlisis de componentes principales. Los nme-
ros de neuronas de la primera y segunda capa intermedia son 5. Los resultados
muestran un mejor comportamiento del mtodo del gradiente conjugado de
Powell-Beale frente al resto. En [114] se usa una red neuronal perceptron mul-
ticapa para la prediccin del precio de la energa en el mercado elctrico de
Victoria (Australia) para la hora siguiente. La red implementada tiene una
capa intermedia con 15 neuronas. El nmero de datos de entrada de la red son
15, donde 9 corresponden a valores pasados de la demanda, la reserva y los
precios y 6 corresponden a variables relacionadas con el tiempo que inuyen
en la demanda. Para el entrenamiento de la red utiliza los meses compren-
didos entre octubre del ao 1996 y mayo del ao 1997. Los resultados de la
prediccin de los precios en una semana (desde el 14 de mayo hasta el 20 de
mayo del ao 1997) muestran un error cuadrtico medio en esa semana de
1.37 %. En [67, 19] se usan redes hbridas para predecir la demanda de das
anmalos en el sistema elctrico italiano. En una primera etapa, mediante un
aprendizaje no supervisado se hace un clustering de la demanda obteniendo as
una clasicacin de los tipos de das. Esta clasicacin se usa en una segunda
etapa en la que se realiza la prediccin mediante un aprendizaje supervisado
con un modelo de red perceptrn multicapa. En [67] se implementa una red
neuronal con una capa intermedia compuesta de 31 neuronas. El vector de
entrada est formado por 51 valores, los 48 valores pasados de la demanda que
se quiere predecir y tres variables binarias que codican la relacin entre los
dos das previos al que se quiere predecir y ste. La red devuelve como salida
29
Captulo 2 Estado del Arte
la demanda de las 24 horas del da siguiente. Para los meses de diciembre y
abril considerados meses anmalos por el gran nmero de das festivos que
comprenden se obtienen unos errores mximos diarios de 7.7 % en diciembre
y 2.7 % en abril. En [19] los resultados obtenidos de la aplicacin de una red
de funcin de base radial a la prediccin del 30 de diciembre de 1997 y 25 de
abril de 1997 (esta nacional en Italia) muestran unos errores relativos medios
de 4 %. En [76] han sido usadas este tipo de redes hbridas tambin para la
prediccin de la demanda horaria del da siguiente en el sistema elctrico es-
paol. El clasicador de Kohonen obtiene 15 clusters y una red neuronal es
aplicada para cada clase obtenida. El conjunto de entrenamiento est formado
por los das comprendidos entre el 1 de enero del ao 1989 y el 31 de diciembre
del ao 1996. El conjunto test est formado por los das comprendidos entre
el 1 de enero del ao 1997 y el 17 de febrero de 1999. Los resultados mues-
tran un error relativo medio de 1.45 % para los das laborables de la semana,
un 1.46 % para los sbados, un 1.62 % para los domingos, un 1.65 % para los
lunes y un 1.87 % para los das de la semana santa. En [102] se usan dos redes
neuronales para la prediccin de los precios de la energa en Inglaterra y en el
pas de Gales, una red neuronal para los das festivos y otra para los nes de
semana, obteniendo unos errores medios de 9.40 % para los sbados, un 8.93 %
para los domingos y un 12.19 % para los das festivos. Recientemente para la
prediccin de la demanda y los precios se han usado redes neuronales difusas
donde se combinan tcnicas conocidas con el nombre de lgica difusa con redes
neuronales. El mdulo de lgica difusa se encarga de generar reglas del tipo
Si-Entonces cuyos parmetros se determinan con el propio aprendizaje de la
red y a la vez alimentan a sta [1], o mediante algn algoritmo evolutivo [63],
y las reglas obtenidas se usan despus de obtener una prediccin provisional
con la red neuronal para modicar sta en base a la temperatura, tipo de da,
etc.
2.3.3.1.2. Programacin Gentica
La PG [66] es una rama de los AG [43] cuya principal diferencia con stos se
basa en la codicacin de los individuos. En los AG la solucin es representa-
da por una cadena lineal mientras que en la PG los individuos son funciones
que se representan en estructura de rbol cuyas hojas representan constantes
y variables y el resto de nodos representan operadores y funciones matem-
ticas. Uno de los aspectos ms importantes en la PG es la representacin de
los individuos ya que inicialmente hay que elegir el tamao mximo de los
individuos (profundidad del rbol) y la forma de la funcin que se busca, es
decir elegir las funciones matemticas, operadores, constantes y variables que
van a formar los nodos internos y las hojas del rbol. Por ejemplo si se eligen
30
Estado del Arte
los operadores +, -, *, /, las variables x, y y z y como conjunto de constantes
los nmeros enteros, un posible individuo puede ser la funcin (3z +y x) 2z
cuya representacin en rbol se muestra en la gura 2.2. El algoritmo bsico
*
- *
*
z 2 x +
z 3
y
Figura 2.2: Representacin de un individuo.
es como sigue:
1. Se genera una poblacin inicial formada por composiciones aleatorias de
funciones, operadores, constantes y variables.
2. Clculo de la medida de la calidad de cada individuo.
3. Creacin de una nueva poblacin.
Copia de los mejores individuos.
Seleccin de los padres aleatoriamente. Los padres son cruzados
para crear nuevos individuos.
Los individuos son mutados.
4. Si no se alcanza el nmero mximo de generaciones, ir al paso 2.
En el caso de aplicar PG a un problema de prediccin de una serie temporal
la funcin que mide la calidad de un individuo obviamente sera la inversa
del error medio de prediccin cometido al usar ese individuo para predecir los
ejemplos de un conjunto de entrenamiento. El operador cruce consiste en la
seleccin aleatoria de un nodo interior en el rbol padre y otro en el rbol
madre, intercambiando los subrboles que cuelgan de los nodos seleccionados.
31
Captulo 2 Estado del Arte
Ntese que no hay ningn inconveniente en aplicar el operador cruce a padres
iguales, lo cual es un aspecto importante de la PG, la habilidad que presenta de
crear dos individuos a partir de uno slo. El operador mutacin es otra carac-
terstica importante de la PG. La mutacin puede consistir en reemplazar un
nodo hoja y un operador o funcin seleccionados aleatoriamente por otro nodo
hoja y por otro operador o funcin. Tambin se puede reemplazar un subrbol
seleccionado aleatoriamente por otro subrbol cualquiera. Los estudios sobre
PG se pueden dividir en dos grandes grupos, aqullos que intentan mejorar
la eciencia de la PG y aqullos que aplican la PG para obtener un modelo
cualitativo que explique el comportamiento del sistema en funcin de los datos
de entrada y as poder usar el modelo obtenido para predecir en un futuro.
En [33] se propone una codicacin lineal de longitud ja para los individuos
en lugar de individuos no lineales de distinto tamao y forma. En [103] se
reduce el espacio de bsqueda de las soluciones mediante una PG dirigida por
una gramtica simple. Existen algunas aplicaciones de la PG a la prediccin
de series temporales. En [54] se presenta una medida de probabilidad de la
predecibilidad de una serie temporal. Esta medida viene dada por:
= 100 (1
SSE
Y
SSE
S
) (2.8)
donde Y
t
es la serie temporal que se pretende predecir, S
t
es la serie tempo-
ral que se obtiene a partir de Y
t
haciendo una reordenacin aleatoria de sta,
SSE es la suma de los errores cuadrticos para el mejor individuo obtenido
de la aplicacin de PG a una serie temporal determinada y SSE es la media
de los errores cuadrticos obtenidos para los mejores individuos en un nmero
determinado de ejecuciones del algoritmo de PG. Si la serie temporal Y
t
es es-
tocstica entonces la PG no tiene poder predictivo ya que la serie temporal no
se puede modelar mediante una funcin y en este caso, al menos tericamente,
el cociente SSE
Y
/SSE
S
es aproximadamente 1. Entonces es aproximada-
mente cero, lo cual quiere decir que la serie temporal Y
t
no es predecible. Si
la serie temporal Y
t
es determinista, se tiene que SSE
Y
< SSE
S
y mientras
ms pequeo sea el error SSE
Y
mayor ser la medida y por tanto la pre-
decibilidad de la serie. En [55] se predice la serie temporal mensual formada
por el precio del crudo utilizando tres tcnicas distintas: PG, RNA y un cami-
no aleatorio. Como conjunto de entrenamiento usa los valores mensuales del
precio del crudo para los aos comprendidos entre 1993 y 1997 (60 datos). El
conjunto test est formado por los valores mensuales del ao 1999 (12 datos).
El ao 1998 no es considerado ni en el entrenamiento ni en el test debido a
que en este ao tuvo lugar la Guerra del Golfo. Los resultados que se obtienen
de la aplicacin de estas tcnicas muestran un mejor comportamiento de la
32
Estado del Arte
PG frente a la RNA y al camino aleatorio ya que los errores relativos medios
son de 7 % para la PG, 7.6 % para el camino aleatorio y 9.4 % para la RNA.
En [36] se predice el color del ocano utilizando PG. Para predecir el color
del ocano basta con predecir la concentracin de toplancton que hay en el
ocano. Para ello se busca una funcin que depende de las concentraciones de
otras sustancias que inuyen en la concentracin de toplancton.
2.3.3.2. Mtodos Locales: Vecinos
Dada la complejidad de encontrar una funcin no lineal que modele el siste-
ma, surgen los modelos locales como mtodos de aprendizaje para la prediccin
de series temporales. Estos modelos consisten en predecir un punto usando slo
los puntos vecinos de los datos de entrada. Dentro de los mtodos locales no li-
neales se encuentran las tcnicas de los vecinos ms cercanos que suelen generar
predicciones ms aproximadas que los mtodos globales. Las tcnicas de veci-
nos ms cercanos (NN, Nearest Neighbours) basan su criterio de aprendizaje en
la hiptesis de que los miembros de una poblacin suelen compartir propieda-
des y caractersticas con los individuos que los rodean, de modo que es posible
obtener informacin descriptiva de un individuo mediante la observacin de
sus vecinos ms cercanos. En 1967 Cover y Hart [25] enuncian formalmente la
regla del vecino ms cercano y la desarrollan como herramienta de clasica-
cin de patrones. Desde entonces, este algoritmo se ha convertido en uno de
los mtodos de clasicacin ms usados [23, 24, 27]. La regla de clasicacin
NN se resume bsicamente en el siguiente enunciado: Sea D = {e
1
, . . . , e
N
} un
conjunto de datos con N ejemplos etiquetados, donde cada ejemplo e
i
contiene
m atributos (e
i1
, . . . , e
im
), pertenecientes al espacio mtrico E
m
, y una clase
C
i
{C
1
, . . . , C
d
}. La clasicacin de un nuevo ejemplo e
cumple que
e
C
i
j = i d(e
, e
i
) < d(e
, e
j
) (2.9)
donde e
C
i
indica la asignacin de la etiqueta de clase C
i
al ejemplo e
; y
d expresa una distancia denida en el espacio m-dimensional E
m
. As, un
ejemplo es etiquetado con la clase de su vecino ms cercano segn la mtrica
denida por la distancia d. La eleccin de esta mtrica es primordial, ya que
determina qu signica ms cercano. La aplicacin de mtricas distintas sobre
un mismo conjunto de entrenamiento puede producir resultados diferentes. Sin
embargo, no existe una denicin previa que indique si una mtrica es buena o
no. Esto implica que es el experto quien debe seleccionar la medida de distancia
ms adecuada. En el caso de clases continuas, la regla NN puede generalizarse
calculando los k vecinos ms cercanos y asignando una media ponderada de las
etiquetas continuas de esos vecinos. Tal generalizacin se denomina k-NN. Este
33
Captulo 2 Estado del Arte
algoritmo necesita la especicacin a priori de k, que determina el nmero de
vecinos que se tendrn en cuenta para la prediccin. Al igual que la mtrica,
la seleccin de un k adecuado es un aspecto determinante. El problema de
la eleccin del parmetro k ha sido ampliamente estudiado en la bibliografa.
Existen diversos mtodos para la estimacin de k [134]. Otros autores [28]
han abordado el problema incorporando pesos a los distintos vecinos para
mitigar los efectos de la eleccin de un k inadecuado. Otras alternativas [104]
intentan determinar el comportamiento de k en el espacio de caractersticas
para obtener un patrn que determine a priori cul es el nmero de vecinos
ms adecuado para clasicar un ejemplo concreto dependiendo de los valores
de sus atributos. En un estudio ms reciente [34] se desarrolla un algoritmo
de clasicacin NN no parametrizado que adapta localmente el valor k. El
algoritmo k-NN se engloba dentro de las denominadas tcnicas de aprendizaje
perezoso (lazy learning), ya que no genera una estructura de conocimiento
que modele la informacin inherente del conjunto de entrenamiento, sino que
el propio conjunto de datos representa el modelo. Cada vez que se necesita
clasicar un nuevo ejemplo, el algoritmo recorre el conjunto de entrenamiento
para obtener los k vecinos y predecir su clase. Esto hace que el algoritmo
sea computacionalmente costoso tanto en tiempo, ya que necesita recorrer la
totalidad de los ejemplos en cada prediccin, como en espacio, por la necesidad
de mantener almacenado todo el conjunto de entrenamiento. Para reducir el
coste computacional de la bsqueda del vecino ms cercano en el ao 2000
Ramasubramanian y Paliwal [100] proponen un esquema de bsqueda por
aproximacin y eliminacin que se resume como sigue:
Se selecciona un candidato a vecino ms cercano de entre los ejemplos
de un conjunto de entrenamiento (aproximacin).
Se calcula la distancia d de este candidato a la muestra
Si esa distancia es menor que la del vecino ms cercano hasta el momento,
se actualiza el vecino ms cercano y se eliminan del conjunto de entrena-
miento aquellos ejemplos que no puedan estar ms cerca de la muestra
que el vecino cercano actual. Para determinar si un ejemplo puede es-
tar ms cerca de la muestra que el vecino ms cercano actual hace falta
calcular su distancia a la muestra, por lo que muchos algoritmos lo que
hacen es obtener de alguna manera una cota inferior de dicha distancia
y eliminar aquellos ejemplos cuya cota inferior sea mayor que d.
Estos autores se basan en el algoritmo AESA [130] que se caracteriza princi-
palmente por calcular un nmero reducido de distancias que no depende del
34
Estado del Arte
tamao del conjunto de entrenamiento. Esta caracterstica es interesante cuan-
do el clculo de la distancia entre dos elementos es muy costoso, por ejemplo si
los elementos son representados en una estructura de rbol y para computar la
distancia hay que recorrer el rbol. El algoritmo AESA tiene un inconveniente,
en la etapa de preprocesado hay que calcular una matriz de distancias donde
se almacenan todas las distancias entre todos los ejemplos del conjunto de en-
trenamiento por lo que la complejidad espacial de este algoritmo es cuadrtica.
De esta forma surge el algoritmo LAESA [85] que supera el problema de la
complejidad espacial cuadrtica. Para ello, en la etapa de preprocesado se elige
a partir del conjunto de entrenamiento un conjunto B de ejemplos base, se cal-
cula la distancia de cada ejemplo base a todos los dems ejemplos del conjunto
de entrenamiento y se almacena en una matriz que ya no es cuadrada. As, la
complejidad espacial del LAESA es lineal con respecto al tamao del conjunto
de entrenamiento. Pese a los numerosos inconvenientes respecto a la eciencia
(coste computacional) y la ecacia (eleccin de la mtrica y el k adecuados),
k-NN tiene en general un buen comportamiento. Cover y Hart [25] demostra-
ron que, cuando el nmero de ejemplos tiende a innito, el error asinttico de
NN est acotado superiormente por el doble del error de Bayes, considerado el
error ptimo. La tcnica de los vecinos ms cercanos y algunas variantes han
sido aplicadas a la prediccin de series temporales. En [52] se presenta una
nueva estrategia para la eleccin del nmero de vecinos cercanos que se usa
en la prediccin de una serie temporal formada por datos hidrolgicos. Esta
estrategia consiste en estimar la varianza del error en funcin del nmero de
vecinos. Entonces el mejor modelo para predecir es aquel que da lugar a la
menor varianza. Por tanto la estrategia consiste en determinar el nmero de
vecinos que hace la varianza mnima. En [81] se presenta un modelo local para
la prediccin de series temporales donde algunos parmetros que afectan a la
aproximacin del modelo son determinados minimizando el error mediante un
algoritmo de optimizacin basado en el descenso del gradiente. El error que
se minimiza es el error de cross-validacin dejando uno fuera (Leave-One-Out
Cross Validation) el cual se obtiene de la siguiente manera: se entrena con to-
dos los ejemplos del conjunto de entrenamiento para determinar el modelo de
prediccin dejando un ejemplo fuera para realizar el test y se calcula el error
obtenido de la prediccin de este ejemplo test. Esto se repite con todos los
ejemplos y la media de todos los errores obtenidos es el error que se minimiza.
La tcnica de bsqueda basada en el gradiente tiene el inconveniente de que
puede alcanzar un mnimo local de la funcin error lo que afectara a la aproxi-
macin del modelo. En [9] se presenta un algoritmo evolutivo para determinar
la longitud de la ventana ptima la cual es uno de los parmetros necesarios
para poder reconstruir la dinmica del sistema a partir de una serie temporal.
35
Captulo 2 Estado del Arte
Es decir, para la prediccin de una serie temporal X
t
se pretende encontrar
una funcin f tal que los valores futuros se estimen en funcin de los valores
pasados de la serie de la siguiente forma:
X
t+
f([X
t
, X
t1
, X
t2
, . . . , X
t(m1)
]) (2.10)
La longitud de la ventana, es decir, el parmetro m, inuye en la aproxima-
cin del modelo de prediccin obtenido. En [112] se presenta un mtodo de
prediccin basado en el vecino ms cercano para predecir las ventas de cuatro
productos de una compaa localizada en el suroeste de Inglaterra. Para me-
dir la proximidad entre dos puntos y
i
y y
n
de la serie temporal se dene una
funcin difusa dada por:
=
1
(d(y
i
, y
n
)/F
d
)
Fe
(2.11)
donde F
d
y F
e
son constantes determinadas mediante experimentos y d es la
distancia Eucldea entre los puntos y
i
y y
n
. Entonces dos puntos se consideran
vecinos cercanos si esta funcin miembro es mayor que un umbral que se de-
termina mediante experimentos. En [41] se aplica el algoritmo de los vecinos
ms cercanos a la prediccin de series temporales articiales y datos reales
procedentes de una planta dedicada al tratamiento de aguas residuales de Ge-
rona. En este trabajo se denen dos distancias, una distancia donde los valores
exactos son relevantes y otra donde la forma de la curva que forman los va-
lores es lo importante a la hora de decidir si dos puntos son vecinos. En [45]
se presenta un mtodo de prediccin basado en las trayectorias vecinas ms
cercanas y una vez determinadas las trayectorias ms cercanas se determinan
los vecinos ms cercanos localizados en estas trayectorias. La mtrica usada
para el clculo tanto de las trayectorias vecinas como de los vecinos ms cer-
canos en estas trayectorias es la distancia Eucldea ponderada por unos pesos
exponenciales de la forma
i
. Los pesos y el nmero de trayectorias vecinas se
determinan mediante un algoritmo de optimizacin cuya funcin objetivo es
el error de cross-validacin.
2.4. Tcnicas de Optimizacin
Una gran variedad de problemas, que aparecen en campos como la Inge-
niera o la Economa, basados en casos reales, se pueden modelar como un
problema de optimizacin. Existen distintas clasicaciones de los problemas
de optimizacin segn el criterio que se elija. Los problemas de optimizacin
36
Estado del Arte
se pueden clasicar dentro de dos grandes grupos: Programacin Lineal y Pro-
gramacin no Lineal, donde tanto la funcin objetivo como las ecuaciones que
modelan las restricciones del problema son lineales o no lineales, respectiva-
mente. A su vez dependiendo de si existen algunas variables enteras, estos dos
grupos de subdividen en otros dos: Programacin Lineal Entera Mixta y Pro-
gramacin no Lineal Entera Mixta. Atendiendo a la convexidad de la funcin
objetivo y las restricciones, tambin se pueden clasicar en Programacin Con-
vexa o Programacin No Convexa. En esta seccin se describe brevemente el
problema de la PHC y las tcnicas de optimizacin existentes en la literatura
que han sido aplicadas para la resolucin de dicho problema destacando las
principales ventajas y desventajas de cada tcnica. El problema de la PHC
consiste en determinar los arranques y paradas de las centrales trmicas (Unit
Commitment) y la produccin de energa elctrica de los grupos trmicos e hi-
drulicos (Coordinacin Hidrotrmica) durante un horizonte temporal de corto
plazo, normalmente 24 horas, de manera que se satisfaga la demanda horaria,
estimada en base a una prediccin, y se minimice el coste de explotacin del
sistema. La formulacin matemtica de este problema se detalla a continua-
cin. Funcin Objetivo: La funcin objetivo a minimizar representa el coste
total del sistema y esta formado por los costes de produccin y los costes de
arranque y parada de las centrales. El coste total viene dado por:
C
T
=
nt
t=1
ng
i=1
C
i,t
U
i,t
+CA
i,t
(S
i,t
) Y
i,t
+CP
i
Z
i,t
(2.12)
donde
C
T
es el coste total.
n
t
es el nmero de horas del horizonte de programacin y n
g
el nmero
de centrales trmicas.
U
i,t
es una variable binaria que es igual a 1 si el generador i est acoplado
en la hora t.
Y
i,t
y Z
i,t
son variables binarias que son igual a 1 si el generador i se
acopla o se desacopla al principio de la hora t, respectivamente.
C
i,t
son los costes de produccin dados por la siguiente curva cuadrtica:
C
i,t
= C(P
i,t
) = a
i
P
2
i,t
+b
i
P
i,t
+c
i
(2.13)
37
Captulo 2 Estado del Arte
CA
i,t
(S
i,t
) son los costes de arranque que dependen del nmero de horas,
S
t
, que el generador lleva apagado.
CP
i
son los costes de parada que se consideran independientes del tiempo.
Restricciones: Las distintas restricciones que aparecen en el problema de la
PHC son las restricciones propias de las centrales y las restricciones del sistema
entre las que se encuentran las restricciones de demanda y las de reserva.
Restricciones de las centrales: Las restricciones tcnicas de las centrales
que se imponen al problema son:
Lmites mximos y mnimos sobre la produccin de energa horaria de
las centrales trmicas e hidrulicas.
P
m
i
P
i,t
P
M
i
i = 1, . . . , n
g
t = 1, . . . , n
t
(2.14)
PH
m
h
PH
h,t
PH
M
h
h = 1, . . . , n
h
t = 1, . . . , n
t
(2.15)
donde n
h
es el nmero de centrales hidrulicas, PH
h,t
es la produccin
de energa generada por la central hidrulica h en la hora t y P
m
i
, P
M
i
,
PH
m
h
y PH
M
h
son los lmites sobre la produccin de energa de la central
trmica i y de la central hidrulica h, respectivamente.
Las rampas de subida y bajada. Las centrales trmicas no pueden aumen-
tar o disminuir la produccin de energa de una hora a la siguiente ms
de una determinada cantidad.
RB
i
P
i,t
P
i,t1
RS
i
i = 1, . . . , n
g
t = 1, . . . , n
t
(2.16)
donde RS
i
y RB
i
son las rampas mximas de subida y de bajada de la
central trmica i respectivamente.
Limitacin del agua disponible. Las centrales hidrulicas tienen restric-
ciones de combustible, ya que su combustible, el agua, es un recurso
limitado. As la energa hidrulica de una central est limitada por el
volumen de agua disponible en el embalse asociado a sta. A su vez la
capacidad de cada embalse est sujeta a lmites de capacidad, es decir:
V H
m
h
V H
h,t
V H
M
h
h = 1, . . . , n
h
t = 1, . . . , n
t
(2.17)
donde V H
h,t
es el volumen de agua del embalse h, asociado a la central
h, en la hora t; V H
m
h
y V H
M
h
son los lmites mnimos y mximos sobre el
volumen del embalse asociado a la central hidrulica h, respectivamente.
38
Estado del Arte
Acoplamiento entre volmenes. Al tratarse de centrales situadas en una
cuenca hidrulica, existe un acoplamiento espacio-tiempo entre las dis-
tintas centrales de la cuenca, pues parte del agua que turbina una central
para generar energa es usada por la central situada justo aguas abajo
cuando llega a su embalse con un cierto retraso temporal. Esto se modela
como sigue:
V H
h,t
= V H
h,t1
PH
h,t
+
sig(k)=h
PH
k,tret(k)
+W
h
(2.18)
donde ret(h) es el tiempo en horas desde que se vierte el agua turbinada
en la central h hasta que llega al siguiente embalse, sig(h), situado aguas
abajo de la central h y W
h
son las aportaciones externas de agua en el
embalse asociado a la central h.
Tiempo mnimo de parada y funcionamiento. El tiempo mnimo de fun-
cionamiento , UT
i
, es el nmero mnimo de horas que una central debe
permanecer acoplada una vez que se pone en funcionamiento. De forma
anloga, el tiempo mnimo de parada, DT
i
, representa el nmero mnimo
de horas que una central debe mantenerse desacoplada una vez que deja
de funcionar. Esto se modela como sigue:
(X
i,t
UT
i
) (U
i,t1
U
i,t
) 0 (2.19)
(S
i,t
+DT
i
) (U
i,t
U
i,t1
) 0 (2.20)
donde X
i,t
es una variable que indica el nmero de horas que lleva aco-
plada la central i al nal de la hora t.
Restricciones del sistema:
La produccin total de energa horaria debe ser igual a la demanda de
energa en esa hora, D
t
, estimada en base a una prediccin.
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
= D
t
t = 1, ..., n
t
(2.21)
La reserva, R
t
, es la energa que el sistema debe ser capaz de proporcionar
de forma rpida en caso de fallo en alguna central o algn incidente no
previsto.
ng
i=1
P
M
i
U
i,t
+
n
h
h=1
PH
M
h
D
t
+R
t
t = 1, ..., n
t
(2.22)
39
Captulo 2 Estado del Arte
La PHC es un problema de naturaleza combinatoria, no lineal, no convexo,
entero-mixto y de gran dimensin cuando se trata de un sistema realista. La
tabla 2.1 muestra el nmero de restricciones, variables binarias y variables con-
tinuas que establecen la complejidad computacional del problema. Por ejemplo,
para un sistema formado por 49 centrales trmicas, una cuenca hidrulica for-
mada por dos centrales y un horizonte de programacin de 24 horas se obtienen
2642 restricciones, 1176 variables binarias y 1272 variables continuas. En las
Nmero de Variables
Nmero de Restricciones Binarias Continuas
(2 n
g
+ 3 n
h
+ 2) n
t
+ 2 n
g
n
g
n
t
(n
g
+ 2 n
h
) n
t
Tabla 2.1: Dimensin del problema.
siguientes secciones se describen los algoritmos de optimizacin ms relevantes
que han sido aplicados para la resolucin del problema de optimizacin descrito
anteriormente.
2.4.1. Programacin Dinmica
La solucin de problemas de optimizacin mediante esta tcnica se basa
en el llamado principio de optimalidad enunciado por Bellman en 1957 [11]
y que dice: En una secuencia ptima de decisiones toda subsecuencia ha de
ser tambin ptima. Obsrvese que aunque este principio parece evidente no
siempre es aplicable y por tanto es necesario vericar que se cumple para el
problema en cuestin. Para que un problema pueda ser abordado por esta
tcnica ha de cumplir dos condiciones:
La solucin al problema ha de ser alcanzada a travs de una secuencia
de decisiones, una en cada etapa.
Dicha secuencia de decisiones ha de cumplir el principio de optimalidad.
En grandes lneas, el diseo de un algoritmo de Programacin Dinmica (PD)
consta de los siguientes pasos:
Planteamiento de la solucin como una sucesin de decisiones y verica-
cin de que sta cumple el principio de optimalidad.
Denicin recursiva de la solucin.
Clculo del valor de la solucin ptima mediante una tabla en donde se
almacenan soluciones a problemas parciales para reutilizar los clculos.
40
Estado del Arte
Construccin de la solucin ptima haciendo uso de la informacin con-
tenida en la tabla anterior.
La esencia de la PD aplicada al problema de la PHCT, conocido en la literatura
como Unit Commitment (UC) [136], consiste en que la potencia generada por
la unidad N debe ser tal que la demanda total menos esa potencia sea generada
por las N 1 unidades restantes a coste mnimo. Las aproximaciones basadas
en PD fueron de los primeros algoritmos de optimizacin que se usaron en
la resolucin de la PHCT [113, 51]. La principal ventaja de esta tcnica es
su capacidad de resolver problemas de distintos tamaos y su facilidad de
modicacin para modelar algunas caractersticas especcas. Es relativamente
fcil aadir restricciones que afectan a una hora determinada aunque resulta
ms difcil aadir restricciones que afecten a una unidad [69], sin embargo hace
un tratamiento subptimo de las restricciones de rampas de subida y bajada
y de los costes de arranques cuando stos dependen del tiempo [70].
2.4.2. Programacin Lineal Entera-Mixta: Ramicacin
y Cota
Un problema de programacin lineal entera mixta [92] es un problema de
programacin lineal en el que algunas variables son enteras. El mtodo de
solucin ms habitualmente empleado en la resolucin de problemas de pro-
gramacin lineal entera mixta es el denominado ramicacin y cota (branch
and bound). El mtodo de ramicacin y cota resuelve un problema de progra-
macin lineal entera mixta mediante la resolucin de mltiples problemas de
programacin lineal, es decir, problemas en los que se relajan las restricciones
relacionadas con las variables enteras. Estos problemas incluyen restricciones
adicionales en cada paso del procedimiento de resolucin, por lo que estn ca-
da vez ms restringidos. Estas restricciones adicionales separan la regin de
factibilidad en subregiones complementarias. El procedimiento de ramicacin
y cota establece inicialmente una cota superior y otra cota inferior al valor p-
timo de la funcin objetivo del problema a resolver. Mediante procedimientos
de ramicacin, el valor de la cota superior se reduce y el de la cota inferior
se aumenta de forma sistemtica a medida que se generan mejores soluciones
factibles del problema de programacin lineal entera mixta. La diferencia entre
el valor de la cota superior y el de la cota inferior es una medida de la proxi-
midad de la cota superior al valor ptimo de la funcin objetivo del problema.
En [68] y [20] se resuelve el problema de la PHCT mediante un algoritmo de
ramicacin y cota en el cual se incorporan todas las restricciones que depen-
den del tiempo y no requiere una ordenacin de las unidades trmicas. En
41
Captulo 2 Estado del Arte
[50] se modela el problema de la PHCT como un problema de programacin
con restricciones lgicas y se resuelve con una tcnica de ramicacin y cota
dando lugar a una solucin eciente. Otros problemas en la literatura han sido
modelados como un problema de optimizacin lineal entera mixta. En [7] se
formula el problema de la programacin ptima de una central trmica en un
mercado de electricidad liberalizado mediante un problema de programacin
lineal entera mixta. Los costes de operacin no diferenciables y no convexos,
los costes de arranques que dependen del tiempo, las restricciones de tiempo
mnimo de parada y funcionamiento de la central y la restriccin de reser-
va teniendo en cuenta las restricciones de rampas se modelan de una manera
rigurosa mediante ecuaciones lineales.
2.4.3. Relajacin Lagrangiana
La Relajacin Lagrangiana (RL) [10] es una tcnica que permite determi-
nar la solucin de un problema de optimizacin general denominado problema
primal mediante la resolucin de un problema alternativo de ms fcil solucin
denominado problema dual. Basado en la teora de la dualidad, el mtodo de
RL busca aquellos valores de los multiplicadores de Lagrange que maximicen
la funcin objetivo del problema dual. Sin embargo, debido a la no convexi-
dad de la mayora de los problemas de optimizacin, la solucin ptima del
problema dual no coincide exactamente con la solucin ptima del problema
primal. A la diferencia entre el mnimo del problema primal y el mximo del
problema dual se le llama agujero de dualidad. El ptimo del problema dual
es un lmite inferior del valor ptimo de la funcin objetivo del problema pri-
mal, debido a la relajacin de las restricciones. La principal desventaja de la
relajacin lagrangiana es que la solucin ptima del problema dual puede pro-
porcionar una solucin infactible para el problema primal. Esto implica que
las variables del problema dual deben modicarse mediante estrategias heu-
rsticas para obtener una solucin primal factible. Mediante la tcnica de la
relajacin lagrangiana se obtienen una cota superior y una cota inferior del
ptimo del problema primal. La cota superior se obtiene de la mejor solucin
factible encontrada para el problema primal, y la cota inferior se obtiene de la
solucin del problema dual. Tpicamente, para sistemas de tamao realista, la
diferencia relativa entre estos dos valores es un pequeo tanto por ciento. Los
mtodos ms utilizados para actualizar los multiplicadores del problema dual
han sido el mtodo del subgradiente [97] y el mtodo de los planos cortantes y
variantes [58, 47, 53]. Esta tcnica es mucho ms reciente que la PD y presenta
un buen comportamiento en problemas con un gran nmero de variables ya
que el grado de suboptimalidad, que es su principal desventaja, tiende a cero
42
Estado del Arte
cuando el nmero de variables aumenta. En el problema de la PHCT, la me-
todologa de relajacin lagrangiana emplea multiplicadores de Lagrange para
incorporar las restricciones de carga (demanda y reserva rodante) a la funcin
objetivo para formar la funcin lagrangiana. La restriccin de demanda con-
siste en la igualdad entre la energa que se genera y la energa que se consume
y la restriccin de reserva consiste en la potencia que el sistema debe ser capaz
de proporcionar de forma rpida en caso de fallo en alguna central. Para ello
se impone que la suma de los mrgenes de potencia disponibles sea mayor o
igual que una cantidad determinada llamada reserva. Para unos valores jos de
los multiplicadores de Lagrange la funcin lagrangiana es separable por cen-
tral. Por lo tanto, la minimizacin de la funcin lagrangiana se descompone en
problemas de minimizacin ms pequeos, uno por cada central. Existen en la
literatura algunas mejoras y reduccin de la complejidad de esta tcnica. En
[116] se propone la resolucin de un problema entero-mixto para obtener una
solucin del problema de la PHCT a partir de una solucin factible ptima
obtenida por RL. La idea principal que motiva esta mejora es el hecho de que
usando RL las programaciones de arranques y paradas de las unidades trmicas
se repiten despus de unas cuantas iteraciones. Adems cuando los multiplica-
dores se actualizan tampoco se obtienen nuevas programaciones de arranques
y paradas, sino que se intenta obtener una solucin factible combinacin lineal
de soluciones factibles ya existentes. Incluso aunque en las ltimas iteraciones
se generen nuevas programaciones de arranques y paradas su contribucin a la
calidad de la solucin es mnima. Por tanto despus de las primeras iteraciones
la solucin obtenida mediante RL es mejorada mediante un problema de op-
timizacin entero-mixto. En [18] se mejora el mtodo de RL incorporando un
algoritmo gentico para actualizar los multiplicadores, ya que una dicultad
de los mtodos basados en RL es que su comportamiento depende del mtodo
de actualizacin de los multiplicadores de la funcin de Lagrange.
2.4.4. Mtodos de Punto Interior
En los ltimos aos los mtodos de Punto Interior [119, 133, 42, 44, 73]
han sido adaptados para resolver problemas de optimizacin no lineales, debi-
do principalmente a su eciencia en la resolucin de problemas lineales de gran
dimensin. Una de sus principales ventajas es su capacidad en lo que respecta
al tratamiento de las restricciones de desigualdad [137, 30]. En 1984 Karmarkar
[56] demostr que estos algoritmos eran de un tiempo de computacin polino-
mial para problemas lineales, mientras que el mtodo del simplex no lo es. En
1992 Mehrotra [84] desarroll una variante conocida como algoritmo de Punto
Interior Predictor-Corrector, cuya principal diferencia est en la resolucin del
43
Captulo 2 Estado del Arte
sistema de ecuaciones. El sistema lineal se resuelve en dos pasos, despreciando
en primer lugar los trminos de penalizacin y calculando a continuacin un
mejor valor de la penalizacin antes de volver a resolver el sistema, incluyendo
ahora trminos de segundo orden. El resolver dos sistemas en cada iteracin
no es mucho ms costoso computacionalmente puesto que la matriz en los dos
sistemas es la misma, con lo que la factorizacin se realiza slo una vez. Es-
ta variante ha sido usada en muchas aplicaciones [138, 78]. Muchas mejoras
han sido propuestas para extender la aplicacin de los mtodos de Punto In-
terior a problemas no lineales no convexos. Estas mejoras estn relacionadas
con el control del tamao del paso [139, 140], tcnicas de bsqueda en lnea
para forzar la convergencia hacia un mnimo local desde un punto inicial ar-
bitrario [37, 129] y uso de regiones de conanza [16]. Las tcnicas de Punto
Interior bsicamente consisten en optimizar mediante Penalizacin de Barrera
Logartmica.
Se trata de convertir las restricciones de lmites en ecuaciones mediante la
introduccin de variables de holgura y asegurar la positividad de estas variables
penalizando la funcin objetivo a travs de trminos logartmicos ponderados
por el factor de penalizacin . En lo que sigue, por simplicidad de notacin,
se describir el algoritmo de Punto Interior para un problema de una nica
variable sujeta a lmites con slo una restriccin de igualdad. Se considera el
problema siguiente,
_
_
Minimizar f(x)
sujeto a h(x) = 0
x
m
x x
M
(2.23)
donde x es una variable, x
m
es una cota inferior, x
M
es un cota superior, f(x)
es la funcin objetivo a minimizar y h(x) es una restriccin de igualdad. Se
denen las variables de holgura:
x
s
= x
M
x (2.24)
x
i
= x x
m
(2.25)
De esta manera en vez de resolver el problema (2.23) se pretende resolver el
siguiente problema:
_
_
Minimizar f(x)
sujeto a h(x) = 0
x
s
+x x
M
= 0
x
i
x +x
m
= 0
x
s
, x
i
0
(2.26)
44
Estado del Arte
As se ha pasado de un problema con restricciones de desigualdad a un pro-
blema con restricciones de igualdad salvo la condicin de no negatividad de
las variables de holgura que se han introducido. Estas condiciones de no ne-
gatividad se tratan aadiendo a la funcin objetivo una funcin de barrera
logartmica. Bsicamente, consiste en penalizar una funcin que tome valores
cada vez mayores cuando estas variables de holgura se vayan acercando a cero.
As el problema (2.26) se transforma en:
_
_
Minimizar f(x) (ln x
s
+ ln x
i
)
sujeto a h(x) = 0
x
s
+x x
M
= 0
x
i
x +x
m
= 0
(2.27)
donde es un parmetro, factor de penalizacin, que tiende a cero cuando
el algoritmo converge al ptimo. Como se pone de maniesto la penalizacin
logartmica asegura que todas las variables permanezcan dentro de sus lmites
(Punto Interior). El problema (2.27) slo tiene restricciones de igualdad y se
le puede aplicar el Mtodo de los Multiplicadores de Lagrange. Se dene la
funcin Lagrangiana:
L
= f(x) +h(x) +z
s
(x
s
+x x
M
) +z
i
(x
i
x +x
m
) (ln x
s
+ ln x
i
) (2.28)
donde , z
s
y z
i
son los Multiplicadores de Lagrange o variables duales. Deri-
vando respecto a cada variable e igualando a cero, se obtienen las condiciones
de optimalidad siguientes:
x
L
= f
(x) +h
(x) z
i
+z
s
= 0
xs
L
xs
+z
s
= 0 = x
s
z
s
=
x
i
L
x
i
+z
i
= 0 = x
i
z
i
=
zs
L
= x
s
+x x
M
= 0
z
i
L
= x
i
x +x
m
= 0
= h(x) = 0
El algoritmo de Punto Interior (Algoritmo Primal-Dual de Barrera Logartmi-
ca) consiste en resolver iterativamente las ecuaciones de optimalidad reducien-
do al mismo tiempo el factor de penalizacin . Las ecuaciones de optimalidad,
debido a su carcter no lineal, se resuelven con el Mtodo de Newton. Apli-
cando el Mtodo de Newton a las ecuaciones de optimalidad, las correcciones
45
Captulo 2 Estado del Arte
a las variables del problema vienen dadas por el sistema de ecuaciones:
_
_
a(x, )x +h
(x) +z
s
z
i
= b(x, )
h
(x)x = h(x)
x +x
s
= (x
s
+x x
M
)
x +x
i
= (x
i
x +x
m
)
z
i
x
i
+x
i
z
i
= (x
i
z
i
)
z
s
x
s
+x
s
z
s
= (x
s
z
s
)
donde
a(x, ) = f
(x) +h
(x) (2.29)
b(x, ) = f
(x) +h
(x) z
i
+z
s
(2.30)
De la tercera y cuarta ecuacin se tiene:
x
s
= (x
s
+x x
M
) x
x
i
= (x
i
x +x
m
) + x.
(2.31)
Sustituyendo estas expresiones de x
s
y x
i
en la quinta y sexta ecuacin se
obtiene:
z
s
=
1
xs
+
zs
xs
(x x
M
) +
zs
xs
x
z
i
=
1
x
i
+
z
i
x
i
(x
m
x)
z
i
x
i
x.
(2.32)
Introduciendo estas expresiones en la primera ecuacin el sistema que hay que
resolver es:
a
(x, )x +h
(x) = b
(x, )
h
(x)x = h(x)
(2.33)
donde
a
(x, ) = a(x, ) +
z
i
x
i
+
z
s
x
s
(2.34)
b
(x, ) = b(x, ) +(
1
x
i
1
x
s
) +
z
i
x
i
(x
m
x) +
z
s
x
s
(x
M
x) (2.35)
Matricialmente,
_
a
(x, ) h
(x)
h
(x) 0
_
_
x
_
=
_
b
(x, )
h(x)
_
(2.36)
46
Estado del Arte
De esta manera el problema se reduce a resolver un sistema de ecuaciones lineal,
cuya matriz es simtrica y en general no es denida positiva. Una vez resuelto
el sistema para los incrementos x y se obtienen el resto de variables
de las ecuaciones (2.31) y (2.32). El sistema se resuelve con slo una nica
iteracin del Mtodo de Newton, pues las condiciones de optimalidad que hay
que resolver cambian al actualizar . As el Algoritmo de Punto Interior se
puede describir de una manera general como sigue:
1) Inicializacin de variables primales y duales, x, , x
s
, x
i
, z
s
, z
i
.
Inicializacin de .
2) Resolucin del sistema de ecuaciones, obteniendo como solucin: x, ,
x
s
, x
i
, z
s
, z
i
.
3) Actualizacin de variables primales y duales, teniendo en cuenta que se
tienen que mantener dentro de la regin factible, en este caso positivas.
Para asegurar esto, se calcula una longitud de avance que multiplica a
todos los incrementos obtenidos en el paso 2. Actualizacin del factor de
penalizacin.
4) Test de parada. Si ste no se cumple, ir al paso 2.
Se han propuesto mltiples tcnicas para reducir sucesivamente en cada
iteracin [119, 82, 140], pero la ms inmediata viene dada por las condiciones
de optimalidad. Si se dene el Error de Dualidad como el producto siguiente:
E
l
= z
l
x
l
(2.37)
donde x
l
es cualquier variable de holgura y z
l
su variable dual asociada, se
tiene que:
= E
l
(2.38)
Luego se calcula el factor de penalizacin proporcional al error de dualidad
medio en cada iteracin, una vez que se han actualizado las variables:
=
L
L
l=1
E
l
, 0 1 (2.39)
donde L es el nmero de variables de holgura introducidas para resolver el
problema. La gura 2.3 describe de una manera general la estructura de un
algoritmo de Punto Interior. En lo que respecta a la resolucin del problema de
47
Captulo 2 Estado del Arte
Inicializacin
Clculo del Error Dual y
Gradiente
Clculo del factor de
penalizacin
Convergencia?
Actualizacin de
variables
Clculo del avance
Solucin del sistema
lineal
Solucin
ptima
SI
NO
Figura 2.3: Algoritmo de Punto Interior
la PHCT existen numerosos trabajos basados en algoritmos de Punto Interior.
En [83] se comparan distintos cdigos comerciales y sus principales ventajas.
En [82] se aplica una tcnica de clipping-o que consiste en resolver el proble-
ma relajando las variables de naturaleza discreta. Una vez resuelto el problema
relajado la mayora de las variables binarias alcanzan sus lmites excepto un
nmero reducido, las cuales se determinan mediante un procedimiento heurs-
tico.
2.4.5. Algoritmos Genticos
Un algoritmo gentico [48, 43, 86] es una tcnica de optimizacin de prop-
sito general basada en principios inspirados en la evolucin biolgica, es decir,
48
Estado del Arte
la seleccin natural, recombinacin gentica y supervivencia de los mejores de
la especie. La bsqueda comienza con un conjunto (poblacin) sucientemente
grande de soluciones (individuos) generadas aleatoriamente. Este conjunto de
soluciones forma la primera generacin. Mediante procesos de seleccin, cruce
y mutacin se obtienen nuevas generaciones de soluciones del problema. Las
caractersticas del conjunto inicial de soluciones mejoran en trminos de la
funcin objetivo de generacin en generacin. Tras un nmero suciente de ge-
neraciones se obtienen soluciones consideradas buenas. Recientemente [35], se
ha demostrado la convergencia asinttica al ptimo de esta tcnica de optimi-
zacin. Un programa evolutivo es un algoritmo probabilista que converge tras
una serie de iteraciones. Este algoritmo mantiene una poblacin de individuos
en cada iteracin, donde cada individuo representa una solucin potencial del
problema a resolver y en cualquier tcnica se implementa o codica como una
estructura de datos ms o menos compleja. Cada solucin es evaluada para
tener una medida de su calidad en trminos de la funcin objetivo. A con-
tinuacin, se forma una nueva poblacin escogiendo a los mejores individuos
segn el ndice de calidad anteriormente denido. Para producir nuevas solu-
ciones e introducir diversidad en el espacio de bsqueda, algunos miembros de
la nueva poblacin se ven sometidos a determinadas transformaciones en su
estructura por medio de los llamados operadores genticos. Este proceso se re-
pite durante una serie de iteraciones (denominadas generaciones por analoga
con la naturaleza), de forma que la calidad de las soluciones va mejorando ite-
racin a iteracin. Otra caracterstica comn a todas las tcnicas evolutivas es
la independencia entre el mtodo de bsqueda y la naturaleza de la funcin ob-
jetivo, as como su exibilidad en el modelado. Las tcnicas convencionales de
optimizacin tales como la programacin lineal entera-mixta, la programacin
dinmica, los mtodos de punto interior o la relajacin lagrangiana requieren
que la funcin objetivo y las restricciones renan una serie de caractersticas de
diferenciabilidad, convexidad, linealidad o independencia del tiempo. Es decir,
cualquier problema, aunque no pueda ser resuelto por ninguna tcnica conven-
cional de forma directa, es resoluble por una tcnica evolutiva. Las diferencias
que presentan los distintos programas evolutivos residen en: tipos de opera-
dores genticos empleados, nmero de individuos en la poblacin, codicacin
empleada, etc. Es decir, una representacin natural de las soluciones del proble-
ma junto con un grupo de operadores genticos compatibles con la naturaleza
del problema son las cualidades determinantes para que una tcnica evolutiva
concreta sea elegida para resolver el problema en cuestin. Existen numerosos
trabajos de la aplicacin de algoritmos genticos al problema de la PHCT en
los cuales la factibilidad de las restricciones es tratada a travs de penalizacio-
nes. En [57] se presenta un algoritmo gentico para resolver el problema de la
49
Captulo 2 Estado del Arte
PHCT. En este algoritmo gentico la factibilidad de las restricciones se asegura
aadiendo a la funcin objetivo una penalizacin proporcional a la cantidad
necesaria para que cada restriccin infactible se cumpla. El factor de penali-
zacin usado es dinmico, puesto que este factor crece cuando el nmero de
generaciones aumenta y es despreciable durante las primeras generaciones. De
esta manera en las ltimas generaciones los individuos de la poblacin que no
cumplen una determinada restriccin son altamente penalizados. Para evitar
una convergencia prematura hacia una solucin cuasi-ptima o una diversidad
excesiva en la poblacin que convierta la bsqueda en un proceso completa-
mente aleatorio, las probabilidades de ocurrencia de los operadores genticos
se modican adaptndose a la situacin existente. En [74] se propone un al-
goritmo gentico para la PHCT en el que tambin se emplean penalizaciones,
aunque aqu se denominan costes de las restricciones. Si se produce algn tipo
de infactibilidad, sta se introduce en la funcin objetivo mediante lo que en
este trabajo se llaman costes de restricciones, que representan lo que el siste-
ma estara dispuesto a pagar en caso de incumplimiento de alguna restriccin.
El operador mutacin se aplica con una probabilidad que aumenta exponen-
cialmente con el nmero de generaciones. En esta contribucin se desarrollan
nuevos operadores heursticos de mutacin. Una de las principales desventajas
de las tcnicas evolutivas es el tiempo de CPU que requieren. Sin embargo,
son algoritmos fcilmente paralelizables lo que reduce el tiempo de clculo. En
[142] se han desarrollado dos implementaciones paralelas de un algoritmo gen-
tico para as reducir el tiempo de clculo de ste. En la primera se ha empleado
una conguracin maestro-esclavo, en la que cada procesador esclavo lleva a
cabo los operadores de cruce y mutacin sobre un subconjunto de la pobla-
cin y el procesador maestro realiza la seleccin proporcional a las medidas de
calidad. En la segunda implementacin, llamada de anillo bidireccional, cada
procesador lleva a cabo la evolucin completa de una subpoblacin y, al cabo
de un nmero determinado de generaciones, los mejores individuos de cada
procesador son transferidos a las poblaciones que se encuentran a su derecha e
izquierda en el anillo de procesadores. En [91] se presentan algoritmos genticos
paralelos aplicados a la PHCT. A cada procesador se le asigna una subpobla-
cin a la que se le aplican los operadores genticos. Una vez que el algoritmo
gentico ha convergido en una subpoblacin los mejores individuos migran a
los cuatro procesadores adyacentes sustituyendo a los peores individuos de las
poblaciones correspondientes. Este proceso se lleva a cabo de forma asncrona
para evitar que haya procesadores inactivos. Existen numerosos trabajos de
la aplicacin de algoritmos genticos al problema de la PHCT en los cuales
la factibilidad de las restricciones es reparada mediante algn mecanismo de
reparacin. En [8] se propone un algoritmo gentico de reparacin conducido
50
Estado del Arte
mediante heursticas para la resolucin de la PHCT. El algoritmo propues-
to preserva la factibilidad de todos los individuos en todas las generaciones.
La principal ventaja de un algoritmo de reparacin se encuentra en que no
trabaja sobre un espacio de bsqueda amplio, lleno de soluciones infactibles,
sino en espacios de bsqueda acotados compuestos de soluciones factibles. Por
ello, la exploracin es ms reducida y aumenta la eciencia del algoritmo. Sin
embargo, los algoritmos de reparacin requieren un elevado tiempo de clculo
para convertir las soluciones infactibles en factibles. En este trabajo se han de-
sarrollado tres implementaciones paralelas para reducir el tiempo de clculo.
La primera implementacin paralela consiste en una conguracin maestro-
esclavo donde la tarea realizada por los procesadores esclavos es la reparacin
de la factibilidad. En segundo lugar desarrolla una implementacin paralela
de grano grueso, que permite explorar un espacio de bsqueda ms extenso.
Finalmente, estas dos implementaciones paralelas se combinan para dar lugar
al algoritmo gentico paralelo hbrido denitivo que se aprovecha de las ven-
tajas de ambas. En [135] se propone un algoritmo gentico combinado con la
cristalizacin simulada. La principal contribucin de este trabajo, adems de
la combinacin de ambas tcnicas de bsqueda, es el uso de procedimientos de
reparacin de las restricciones de demanda y reserva. La solucin se descarta
si se producen infactibilidades en otras restricciones. En [75] se presenta un
algoritmo gentico de reparacin en el que la matriz de acoplamiento se codi-
ca mediante una cadena para ahorrar espacio de almacenamiento. Se parte
de una poblacin factible de soluciones y el proceso de reparacin slo afecta
a la restriccin de reserva.
51
Captulo 2 Estado del Arte
52
Parte I
Prediccin de Series Temporales
53
Captulo 3
Mtodo basado en los Vecinos ms
Cercanos
En este captulo se describe una tcnica de clasicacin y reconocimiento
de patrones basada en la bsqueda de los vecinos ms cercanos aplicada a
la prediccin de una serie temporal. El criterio de aprendizaje de este tipo
de algoritmos se fundamenta en que los individuos de una poblacin conviven
alrededor de otros que suelen tener unas propiedades y caractersticas similares.
Una vez descrito el mtodo, se analiza cul es la forma ptima de representar
el conjunto de datos de entrada y se estudia la inuencia de dos parmetros
que afectan a dicho algoritmo: el nmero de vecinos, es decir el nmero de
ejemplos que sern examinados en el momento de efectuar la prediccin y la
mtrica elegida como medida de similitud entre dos ejemplos del conjunto de
datos. Por ltimo, se analiza de forma heurstica cul es el error mnimo que
se comete en la prediccin de una serie temporal con este mtodo.
3.1. Representacin de los Datos
Una serie temporal es un conjunto nito de observaciones de una variable
en distintos momentos del tiempo. Aunque el tiempo es una variable continua,
estas observaciones vienen dadas en la prctica en periodos de tiempo discretos
de igual longitud, restriccin que viene impuesta por la naturaleza de la variable
como por ejemplo los precios de la energa en el Mercado Elctrico Espaol
cuyos valores son conocidos hora a hora. Cuando el intervalo discreto de tiempo
es pequeo, como por ejemplo una hora o cinco minutos, la serie se considera
una serie de alta frecuencia lo cual es ventajoso ya que las dependencias a corto
plazo en las observaciones son ms fciles de detectar.
55
Captulo 3 Mtodo basado en los Vecinos ms Cercanos
La prediccin de una serie temporal consiste en calcular los n valores si-
guientes de la variable a partir de sus valores pasados disponibles.
Para predecir el comportamiento de una serie temporal, X
t
, hay que de-
terminar en primer lugar qu variables inuyen en la descripcin del valor de
la serie en el intervalo de tiempo t. Esto no siempre es posible ya que en la
mayora de las aplicaciones reales el nmero de variables que inuyen en la
serie temporal es elevado y gran parte de estas variables son difciles de medir
porque vienen determinadas por factores no predecibles.
Una serie temporal puede ser tratada como un sistema dinmico puesto que
consiste en la evolucin de una variable con el tiempo. Takens [115] demuestra
que, bajo ciertas hiptesis, el estado que explica un sistema dinmico en un
instante de tiempo se puede aproximar por una ventana de longitud nita
formada por los valores anteriores de la variable estado del sistema. La longitud
de la ventana, m, se conoce como dimensin de inyeccin. De esta forma se
busca una relacin funcional f tal que:
X
t+
f(X) (3.1)
donde
X = [X
t
, X
t
, X
t2
, . . . , X
t(m1)
] (3.2)
Este teorema es importante, desde el punto de vista de la prediccin de series
temporales, puesto que implica poder generar predicciones de la variable a
partir de una ventana nita formada por valores pasados de dicha variable.
Por simplicidad de notacin y sin prdida de generalidad, se supondr que
= 1, lo que signica que la frecuencia de los valores de la serie es de una
unidad de tiempo.
Para generar predicciones hay dos tipos de aproximaciones:
1. Prediccin directa: consiste en predecir n valores de la serie temporal a
partir de los mismos datos de entrada. As se tiene una regla de asociacin
entre los valores pasados de la variable que se quiere predecir como puntos
de R
m
, y los valores futuros como puntos de R
n
. Es decir, se construye
un nico modelo para predecir los valores:
X
t+1
, . . . , X
t+n
(3.3)
De esta manera, se trata de hallar f : R
m
R
n
tal que:
[
X
t+1
, . . . ,
X
t+n
] = f([X
t
, X
t1
, X
t2
, . . . , X
t(m1)
]) (3.4)
56
Mtodo basado en los Vecinos ms Cercanos
donde f es una funcin no lineal que relaciona los valores futuros de
la serie temporal con los valores pasados. Este tipo de prediccin tie-
ne el inconveniente de que no tiene en cuenta a la hora de predecir las
posibles relaciones existentes entre las variables X
t+1
, . . . , X
t+n
, sin em-
bargo computacionalmente es menos costoso puesto que se construye un
nico modelo para predecir n valores y no, n modelos, uno para cada
prediccin.
2. Prediccin iterada: este tipo de prediccin consiste en usar un conjun-
to de datos de entrada distinto para predecir cada valor de la serie. As,
la prediccin obtenida forma parte de una nueva ventana para predecir
el valor siguiente, desplazando de esta forma la ventana una unidad de
tiempo en cada prediccin. De esta manera se tiene una relacin entre
valores pasados como puntos de R
m
y valores futuros como puntos de
R. Con este ltimo tipo de prediccin los errores se van acumulando en
el vector de entrada que forma la ventana, sobre todo en los ltimos
periodos de tiempo del horizonte de prediccin. Este mtodo es compu-
tacionalmente ms costoso que el anterior, ya que para predecir n valores
se construyen n modelos, para generar cada uno de los n valores futuros
de la serie en estudio.
De esta manera se tratar de hallar f
i
: R
m
R con i = 1, 2, . . . , n tal
que:
X
t+1
= f
1
([X
t
, X
t1
, X
t2
, . . . , X
t(m1)
]) (3.5)
X
t+2
= f
2
([
X
t+1
, X
t
, X
t1
, . . . , X
t(m2)
]) (3.6)
X
t+3
= f
3
([
X
t+2
,
X
t+1
, X
t
, . . . , X
t(m3)
]) (3.7)
.
.
.
donde f
i
son funciones no lineales que relacionan los valores futuros de la serie
temporal con los valores pasados para cada hora del horizonte de prediccin.
La longitud de la ventana es un parmetro que hay que determinar de manera
ptima mediante el anlisis de los valores pasados de la serie temporal, dispo-
nibles en la base de datos histrica, que ms inuyen en los valores futuros de
la variable que se quiere predecir.
Para determinar de una manera ptima la longitud de la ventana m se
usa el Mtodo de los Falsos Vecinos ms Cercanos (FNN, False Nearest
Neighbours) [59], el cual consiste en calcular la longitud de la ventana que hace
el nmero de falsos vecinos ms cercanos mnimo.
Dos puntos x, y de R
m
, que representan valores de la serie temporal en
el pasado, son vecinos falsos si la distancia entre los puntos f(x) y f(y), que
57
Captulo 3 Mtodo basado en los Vecinos ms Cercanos
Figura 3.1: Vecinos Falsos.
representan las predicciones de sus correspondientes valores futuros (puntos de
R
n
o R segn el tipo de prediccin que se haga), es mayor que la distancia que
hay entre los puntos x e y, como se muestra en la gura 3.1.
Este radio de crecimiento entre valores pasados y futuros segn el tipo de
prediccin que se lleve a cabo se calcula como sigue.
Sean dos puntos de R
m
:
X
t
1
pas
= [X
t
1
, X
t
1
1
, X
t
1
2
, . . . , X
t
1
(m1)
] (3.8)
X
t
2
pas
= [X
t
2
, X
t
2
1
, X
t
2
2
, . . . , X
t
2
(m1)
] (3.9)
1. Prediccin directa:
Se tiene que:
X
t
1
fut
= f(X
t
1
pas
) (3.10)
X
t
2
fut
= f(X
t
2
pas
) (3.11)
Entonces el radio de crecimiento viene dado por:
RADIO =
d
n
(X
t
1
fut
, X
t
2
fut
)
d
m
(X
t
1
pas
, X
t
2
pas
)
(3.12)
donde
Los puntos X
t
1
fut
y X
t
2
fut
son las predicciones obtenidas de los valores
futuros que vienen dadas por:
X
t
1
fut
= [
X
t
1
+1
,
X
t
1
+2
, . . . ,
X
t
1
+n
] (3.13)
X
t
2
fut
= [
X
t
2
+1
,
X
t
2
+2
, . . . ,
X
t
2
+n
] (3.14)
58
Mtodo basado en los Vecinos ms Cercanos
d
i
(, ) es una distancia entre puntos de R
i
con i {n, m}
2. Prediccin iterada:
Se tiene que:
X
t
1
+1
= f(X
t
1
pas
) (3.15)
X
t
2
+1
= f(X
t
2
pas
) (3.16)
Luego
RADIO =
|
X
t
1
+1
X
t
2
+1
|
d
m
(X
t
1
pas
, X
t
2
pas
)
(3.17)
Si RADIO es mayor que un umbral dado, el punto X
t
1
pas
es un vecino falso
de X
t
2
pas
. Se trata entonces de elegir la longitud de la ventana sucientemente
grande para que el nmero de vecinos cercanos considerados falsos sea su-
cientemente pequeo. De esta forma, para encontrar el tamao adecuado de
la ventana se calcula el porcentaje de vecinos falsos en un conjunto de entre-
namiento para longitudes de la ventana que oscilen entre uno y un nmero
mximo prejado, m
max
, eligiendo como longitud aquella que haga que este
porcentaje se aproxime a cero. Como este parmetro se determina a partir de
un conjunto de entrenamiento, donde se conocen los valores futuros reales, las
predicciones no son valores estimados sino valores reales de la base de datos
histrica.
La optimizacin de este parmetro es importante ya que si la longitud de
la ventana es demasiado pequea, el nmero de falsos vecinos es elevado lo que
diculta obtener una buena aproximacin de la prediccin de la serie temporal.
Por otro lado, si este parmetro es demasiado grande, el coste computacional
es elevado en relacin a la mejora obtenida en la aproximacin del error de la
prediccin.
La gura 3.2 muestra cmo disminuye el nmero de vecinos falsos cuando
aumenta el nmero de valores pasados de la serie temporal usados para predecir
los valores siguientes. Como se observa, un nmero determinado de valores
pasados son sucientes para predecir los valores siguientes, ya que el nmero
de vecinos falsos no disminuye de una manera considerable con el uso de ms
valores.
59
Captulo 3 Mtodo basado en los Vecinos ms Cercanos
Dimensin de inyeccin
V
e
c
i
n
o
s
F
a
l
s
o
s
(
%
)
m ptimo
Figura 3.2: Vecinos falsos versus longitud de la ventana.
3.2. Mtodo basado en los Vecinos ms Cerca-
nos
En esta seccin se describe una tcnica aplicada a la prediccin de series
temporales, basada en un algoritmo de bsqueda de los k vecinos ms cercanos
(kNN, k Nearest Neighbours) [27], cuyo aprendizaje consiste en el almacena-
miento de todas las instancias disponibles [3] de las cuales se conocen sus
valores futuros.
Esta prediccin consiste en construir una aproximacin f a partir de un
conjunto de instancias o ejemplos de la base de datos histrica, llamado con-
junto de entrenamiento, los cuales se conservan para compararlos con cada
nuevo ejemplo del que se quieran predecir sus valores siguientes.
Con este mtodo en lugar de construir una aproximacin f vlida para todo
el conjunto de ejemplos, de los que se quieren predecir sus valores siguientes,
se obtienen aproximaciones locales alrededor de subconjuntos del conjunto
de entrenamiento. Estos subconjuntos estn formados por los k vecinos del
ejemplo para el que se quiere predecir su comportamiento en el futuro.
La aproximacin consiste en una media de los valores futuros de los k veci-
nos ms cercanos. Esta media est ponderada con unos pesos que representan
la importancia de cada vecino segn su cercana. A los valores futuros del ve-
cino ms cercano le corresponde un peso mayor que a los valores futuros del
vecino ms lejano.
En el caso de un nico vecino la idea geomtrica se muestra en la gura
3.3.
60
Mtodo basado en los Vecinos ms Cercanos
f(r)
r
f
Figura 3.3: Aproximacin local.
Los valores futuros desconocidos que se quieren estimar:
X
fut
= [X
t+1
, . . . , X
t+n
](puntos de R
n
), (3.18)
y los valores pasados
X
pas
= [X
t
, X
t1
, X
t2
, . . . , X
t(m1)
](puntos de R
m
) (3.19)
estn representados con una circunferencia. Los puntos negros son los vecinos
ms cercanos a los valores pasados, siendo el punto r R
m
aquel cuyos valores
son los ms parecidos. Entonces parece lgico estimar los valores futuros con
los valores futuros del punto r, es decir, los valores f(r).
De esta manera, la prediccin de n valores futuros de una serie temporal
X
t
viene dada por:
X
fut
=
1
k
i=1
i
k
l=1
l
f(v
l
(X
pas
)) (3.20)
donde
v
l
(X
pas
) R
m
son los k vecinos del punto de R
m
formado por los valores
pasados, X
pas
, ordenados desde el ms cercano al ms lejano.
los pesos
l
[28] generalmente vienen dados por algunas de estas dos
expresiones:
61
Captulo 3 Mtodo basado en los Vecinos ms Cercanos
a)
l
=
d(X
pas
, v
k
(X
pas
)) d(X
pas
, v
l
(X
pas
))
d(X
pas
, v
k
(X
pas
)) d(X
pas
, v
1
(X
pas
))
(3.21)
El peso
l
es igual a cero cuando l corresponde al vecino considerado
ms lejano y uno cuando el vecino considerado es el ms cercano.
Por tanto, con estos pesos en realidad se usan k 1 vecinos para
predecir.
b)
l
=
1
d(X
pas
, v
l
(X
pas
))
(3.22)
Con estos pesos se usan exactamente k vecinos para predecir.
Estos pesos dados por a) y b) dan una mayor importancia en la prediccin
a los vecinos ms cercanos, ya que en su clculo slo inuye la distancia
que separa a stos de X
pas
.
En forma matricial,
(
k
i=1
i
)
X
fut
= [
1
, . . . ,
k
]
_
_
f(v
1
(X
pas
))
.
.
.
f(v
k
(X
pas
))
_
_
(3.23)
3.3. La funcin distancia
El uso de diferentes distancias [27, 12] puede dar lugar a mejores aproxima-
ciones en el algoritmo de bsqueda de los k vecinos ms cercanos. El mtodo
descrito en la seccin anterior consiste en estimar la prediccin a partir de una
media local ponderada con unos pesos. Para determinar los valores futuros
f(v
l
(X
pas
)) que forman parte de esta media, basta con calcular los k vecinos
ms parecidos a los valores X
pas
de la serie temporal. Para ello hay que elegir
una distancia que mida la similitud entre puntos de R
m
, formados por valores
cualesquiera de la serie temporal, de una manera adecuada a las caractersticas
especcas de la serie que se est tratando de predecir. Tradicionalmente, la
distancia ms comn usada ha sido la distancia Eucldea, que se dene como
sigue:
d
2
(q, z) =
m
i=1
(q
i
z
i
)
2
(3.24)
62
Mtodo basado en los Vecinos ms Cercanos
donde q y z son dos ejemplos de entrada, m es el nmero de atributos y q
i
y
z
i
los valores de cada atributo.
Existen una gran variedad de distancias para atributos continuos:
Manhattan
d(q, z) =
m
i=1
|q
i
z
i
| (3.25)
Minkowsky
d(q, z) =
_
m
i=1
|q
i
z
i
|
r
_1
r
(3.26)
Mahalanobis
d(q, z) = (det(V ))
1
m
(q z)
T
V
1
(x y) (3.27)
donde V es la matriz de covarianza de los atributos, det(V ) es el deter-
minante de la matriz V y V
1
la inversa de V .
Chebychev
d(q, z) = max
m
i=1
|q
i
z
i
| (3.28)
Sin embargo, muchas aplicaciones del mundo real requieren una distancia
un poco ms exible a la hora de modelar las caractersticas de la serie, como
por ejemplo cualquier distancia entre las denidas anteriormente ponderada
por unos factores de peso w
i
los cuales representan la importancia de cada
atributo, ya que los m atributos del punto del cual se quieren predecir sus
valores siguientes pueden tener distinta relevancia. Tratar los atributos de dis-
tinta forma consiste en distorsionar el espacio de manera que los atributos con
gran inuencia en la prediccin tengan un peso grande y a los atributos que
slo introducen ruido, le corresponda un peso pequeo. Estos factores de peso
se pueden determinar con ejemplos conocidos del conjunto de entrenamiento
mediante: algoritmos genticos [121], criterio de informacin mutua [26]... Una
vez determinados estos factores de peso, incluso se pueden eliminar los atribu-
tos que no se consideren importantes para la prediccin de la serie temporal
determinada.
3.4. Nmero de Vecinos
En el algoritmo kNN un parmetro a determinar es k, el nmero de ejemplos
que se eligen para efectuar la prediccin de un nuevo ejemplo. El valor de k
63
Captulo 3 Mtodo basado en los Vecinos ms Cercanos
tiene un gran impacto en la calidad del modelo y por tanto en la aproximacin
del error de la prediccin de una serie temporal.
Cuando el nmero de vecinos considerado es igual a uno, el algoritmo busca
el ejemplo ms cercano al ejemplo cuyos valores futuros se quieren predecir.
Cuando el ejemplo ms cercano es encontrado, la prediccin consiste en los
valores futuros de ste. Esto sin embargo, es muy sensible al ruido, por lo que
debe determinarse el valor de k ptimo.
Se trata entonces de hallar k de manera que el error de una serie temporal
sea mnimo, es decir, minimizar la funcin objetivo cuadrtica que sigue:
p
j=1
(
X
fut
X
fut
)
2
donde
X
fut
viene dado por (3.20) (3.29)
para un conjunto de entrenamiento formado por p ejemplos.
Generalmente, el valor ptimo de k es independiente del tipo de error (error
cuadrtico, error absoluto, error relativo...) que se tome como funcin objetivo
para minimizar en el conjunto de entrenamiento [127].
3.5. Acotacin del Error
En esta seccin se hace un breve anlisis heurstico de cul es el mnimo
error que se comete en la prediccin de una serie temporal con el mtodo
local descrito anteriormente. Primero se analiza el caso de un solo vecino y
nalmente se concluye para el caso ms general de k vecinos ms cercanos.
La prediccin del punto X
fut
, se estima con los valores futuros del punto
que tuvo los valores ms parecidos a los valores pasados, es decir los valores
futuros del vecino ms cercano de X
pas
:
X
fut
= f(v(X
pas
)) donde v(X
pas
) es tal que d(X
pas
, v(X
pas
)) es mnima (3.30)
El error mnimo de la prediccin se cometer cuando la prediccin de los
valores futuros sea estimada con los valores ms parecidos a los valores futuros,
es decir:
X
fut
= v(X
fut
) donde v(X
fut
) es tal que d(X
fut
, v(X
fut
)) es mnima (3.31)
64
Mtodo basado en los Vecinos ms Cercanos
Entonces el error es mnimo cuando se tiene la condicin siguiente:
v(X
fut
) = f(v(X
pas
)) (3.32)
Es decir, los valores futuros del vecino ms cercano del punto formado por
valores pasados coincide con el vecino ms cercano del punto formado por
valores futuros.
Esto se puede ver grcamente mediante el diagrama siguiente:
v(X
pas
)
f
X
fut
X
r
f
v(X
fut
)
(3.33)
Si f es una inyeccin, se tiene que cumplir:
X
r
= v(X
pas
) (3.34)
Es decir, el vecino ms cercano de X
pas
es un punto X
r
tal que la prediccin
de sus valores futuros los cuales vienen dados por f(X
r
) coincide con el vecino
ms cercano de X
fut
.
Como el clculo del vecino ms cercano depende de la distancia considera-
da, se puede obtener el error mnimo en la prediccin de una serie temporal
mediante este mtodo basado en los vecinos ms cercanos, si se pudiera encon-
trar una medida de distancia d tal que cumpliera la condicin (3.34). Si esta
condicin se cumple, la prediccin mediante (3.30) dara lugar al mnimo error
posible que se puede cometer con este mtodo.
En el caso de k vecinos ms cercanos, razonando de manera anloga, el
error es mnimo cuando:
v(X
fut
) =
1
k
i=1
i
k
l=1
l
f(v
l
(X
pas
)) (3.35)
Es decir, el error es mnimo cuando la suma ponderada de los valores futuros
de los k vecinos ms cercanos de los valores pasados de la serie es proporcional
al vecino ms cercano de los valores futuros. La constante de proporcionalidad
es
1
+. . . +
k
, donde
l
vienen dados por (3.21) o (3.22).
Obsrvese que para predecir de forma ptima los valores futuros de la serie
temporal, se necesita calcular f(X
r
) minimizando la distancia a los valores
que se quieren predecir, luego este anlisis es til para saber si el error que se
ha cometido despus de haber predicho localmente con este mtodo se desva
mucho del error ptimo que se pudiera haber obtenido.
65
Captulo 3 Mtodo basado en los Vecinos ms Cercanos
Vase tambin que cuando la prediccin por este mtodo se aleja de ser la
ptima, es decir, d(f(v(X
pas
)), X
fut
) es sucientemente grande, X
pas
y v(X
pas
)
son vecinos falsos. Adems la diferencia entre el error obtenido y el error ptimo
da una idea intuitiva de la divergencia media que sufren las trayectorias que
son vecinas en el pasado pero dejan de serlo en el futuro, como se muestra en
la gura 3.1.
El Error Absoluto (EA) al predecir de manera ptima viene dado por:
EA =
n
i=1
|
X
fut
X
fut
| =
n
i=1
|v(X
fut
) X
fut
| (3.36)
De (3.36) se deduce que el EA es mnimo si se elige como mtrica la distancia
Manhattan, puesto que v es tal que d(X
fut
, v(X
fut
)) es mnima. Es decir,
si la distancia elegida para el clculo del vecino ms cercano es la distancia
Manhattan, al predecir de manera ptima, el error absoluto ser menor que el
obtenido con cualquier otra distancia. Lo mismo ocurre con el error cuadrtico
si se elige la distancia Eucldea.
66
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Para demostrar la efectividad del mtodo basado en los vecinos ms cerca-
nos presentado anteriormente, en este Captulo se aplica a la prediccin en el
corto plazo de una serie temporal real: los precios de la energa en el Mercado
Elctrico Espaol. En primer lugar, se presentan grcamente las principales
caractersticas de esta serie. En segundo lugar, se determinan todos los pa-
rmetros que afectan al mtodo, como la longitud de la ventana, el nmero
de vecinos, la distancia... tanto si se realiza una prediccin iterada como si se
realiza una prediccin directa, usando para ello un conjunto de entrenamiento.
Una vez determinado el conjunto de parmetros ptimo y el tipo de prediccin
que proporciona los errores ms pequeos, se obtienen resultados de la predic-
cin sobre un conjunto test y se comparan con los obtenidos si la prediccin se
hiciese de manera ptima sobre ese mismo conjunto. Finalmente, los resultados
obtenidos de la aplicacin del mtodo, basado en los vecinos ms cercanos, son
comparados con los obtenidos de la aplicacin de una red neuronal.
4.1. Precios. Optimizacin de Venta/Compra de
Energa
En los ltimos quince o veinte aos las empresas elctricas estn tendiendo
progresivamente a la privatizacin, con el objeto de que al eliminar el rgimen
de monopolio se genere competencia en el mercado, lo que se supone que
lleva consigo un efecto benecioso sobre los consumidores, tanto en calidad de
servicio como en precios. El Sector Elctrico Espaol desde 1998 ha puesto en
marcha un proceso de reestructuracin siguiendo criterios de liberalizacin y
67
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
competencia, al igual que un gran nmero de pases en el mundo como Noruega,
Suecia, Finlandia, Portugal, etc. De esta manera en el sistema Espaol surgen
dos nuevas guras que hacen posible el funcionamiento de las nuevas reglas que
rigen el Mercado [17]: el operador del mercado, encargado de la determinacin
de los precios de la energa cada hora y el operador del sistema, encargado de
la gestin de la red de transporte de electricidad.
En un mercado liberalizado, las herramientas de prediccin son muy impor-
tantes, ya que en base a una prediccin de precios, los agentes que participan
en el mercado, como las compaas de generacin, elaboran sus estrategias de
ofertas para maximizar los benecios que obtienen por la venta de energa en
el mercado [77, 21].
Sin embargo debido a la reciente liberalizacin del mercado elctrico las
tcnicas de prediccin aplicadas a los precios de la energa son bastantes re-
cientes y poco usuales en la literatura actual, siendo un campo de investigacin
actualmente en estudio. Hoy da, los mtodos ms usados para la prediccin de
los precios de la energa en un mercado competitivo son los distintos tipos de
RNA [114, 143, 101, 39], siendo en este contexto la primera vez que se aplica
el mtodo basado en los vecinos ms cercanos descrito en el captulo anterior.
En general, las series econmicas, entre ellas la serie de los precios de la
energa en un mercado liberalizado, presentan las caractersticas siguientes:
1. Generalmente las series temporales disponibles son cortas, excepto las
series de alta frecuencia. La serie temporal formada por los precios de la
energa es de alta frecuencia puesto que la frecuencia de los precios es de
una hora.
2. La prediccin de los valores de la serie temporal son generalmente difciles
de medir con precisin, ya que hay factores imprevisibles que responden a
mecanismos de mercado. Debido a esto, son series con un alto porcentaje
de valores inusuales y con un comportamiento catico.
3. No son estacionarias, es decir no tienen media y varianza constante.
4. Son series no lineales con componentes estocsticos.
Para ilustrar de una manera visual el comportamiento, propiedades y evo-
lucin de la serie temporal formada por los precios de la energa se han elegido
los meses comprendidos entre marzo y agosto del ao 2001. Los nes de sema-
na y das festivos no son incluidos debido a que presentan un comportamiento
distinto a los das laborables.
El precio medio de la serie es 2.79 cntimos de euros por kWh y la desvia-
cin estndar respecto de la media 1.14, lo cual es un primer indicador de la
dispersin que presentan los precios de la energa.
68
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
1 3 5 7 9 11 13 15 17 19 21 23
Horas
C
n
t
i
m
o
s
/
k
W
h
Media
Media + s. d.
Media - s. d.
Figura 4.1: Media horaria de los precios.
La gura 4.1 muestra el valor medio horario de los precios de la energa
para los das laborables de marzo del ao 2001. Se puede observar que las horas
en las que los precios son superiores a 2 cent/kWh son aqullas en las que la
demanda suele ser alta (horas punta) y corresponden a la punta de la maana
(desde las 10 horas hasta las 14 horas) y la punta de la tarde (desde las 20
horas hasta las 22 horas). Excepto para unas cuantas de horas en las que la
demanda es baja (horas valle), la desviacin estndar supera el 20 % del valor
medio, alcanzando incluso el 40 % a las 20 horas y 21 horas.
[3,4]
16%
[2,3]
38%
[1,2]
23%
> 4
21%
< 1 2%
Figura 4.2: Distribucin de los precios.
69
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
La gura 4.2 muestra la distribucin de los precios para los meses com-
prendidos entre marzo y agosto del ao 2001. Ntese que el 21 % de los precios
tienen valores mayores que 4 cntimos por kWh y el 2 % valores menores que
1 cntimo por kWh. Estos precios son considerados inusuales, y su alto por-
centaje diculta obtener una buena prediccin.
En la gura 4.3 se muestran los histogramas de los precios en el ao 2000
y 2001 para comparar el comportamiento de estos dos aos. Se puede observar
que tanto la distribucin del ao 2000 como la del ao 2001 dista mucho de
ser una distribucin normal indicada en la gura con una curva. Adems,
mientras que en el ao 2001 la mayora de las horas los precios estn entre 2
y 3 cntimos el kWh, en el ao 2000 son menores que 1 cntimo el kWh. Esto
puede ser debido a que en el ao 2000 la liberalizacin del mercado era an
muy reciente y el mercado por consecuencia era ms inestable.
Precios (Cent/kWh)
0 1 2 3 4 5 6 7
10%
20%
30%
40%
50%
Precios (Cent/kWh)
0 1 2 3 4 5 6 7
10%
20%
30%
40%
50%
Figura 4.3: Histograma de los precios del ao 2000 y 2001.
La gura 4.4 muestra los precios horarios que tuvieron lugar el jueves 1 de
marzo del ao 2001 y el viernes 30 de marzo del ao 2001. Estos dos das han
sido elegidos debido a las diferencias signicativas de precios que hay en las
horas punta las cuales no se pueden explicar por un cambio en el perl de la
demanda pudindose atribuir dichas diferencias a mecanismos de mercado de
tipo oligopolista.
70
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
0
1
2
3
4
5
6
1 3 5 7 9 11 13 15 17 19 21 23
Horas
C
n
t
i
m
o
s
/
k
W
h
viernes 30 de marzo
jueves 1 de marzo
Figura 4.4: Precios de dos das de marzo.
La gura 4.5 muestra el coeciente de correlacin entre los precios de la
energa en una hora y los precios correspondientes a las veinticuatro horas
anteriores. Como se puede ver, las horas pasadas ms inuyentes en la hora
actual son justo la hora uno y la veinticuatro, que coinciden con la hora anterior
y con la misma hora que la actual pero del da anterior, respectivamente.
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 3 5 7 9 11 13 15 17 19 21 23
N de horas anteriores
C
o
e
f
i
c
i
e
n
t
e
d
e
C
o
r
r
e
l
a
c
i
n
Figura 4.5: Coeciente de correlacin.
71
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Una vez ilustradas de forma visual las principales caractersticas y el com-
portamiento de los precios de la energa en el Mercado Elctrico Espaol se
procede a denir el problema de prediccin que se va a resolver y a mostrar su
resolucin mediante la aplicacin del mtodo expuesto en el captulo anterior.
4.2. Descripcin del problema
Las ofertas de venta y compra de energa para el da siguiente se presentan
por parte de los agentes del mercado al Operador de Mercado en el mercado
diario. El Operador de Mercado incluye esta ofertas en un procedimiento de
casacin obteniendo as el precio de la energa para el horizonte diario de
programacin correspondiente al da siguiente. De esta manera, el problema
consiste en predecir los precios de la energa en el corto plazo, es decir, las
veinticuatro horas del da siguiente.
4.3. Obtencin del modelo
Para predecir los precios horarios del da siguiente se usa una ventana
deslizante formada por los precios horarios de das anteriores disponibles en
la base de datos histrica. A continuacin se determinar la longitud de esta
ventana con el mtodo de los falsos vecinos ms cercanos, descrito en el captulo
anterior, tanto si se va a realizar una prediccin directa como iterada.
4.3.1. Con prediccin directa
Con este tipo de prediccin la estructura de los patrones es la siguiente:
P
1,1
P
1,24
P
m,1
P
m,24
P
m+1,1
P
m+1,24
P
2,1
P
2,24
P
m+1,1
P
m+1,24
P
m+2,1
P
m+2,24
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(4.1)
donde los atributos P
d,h
representan el precio de la energa elctrica del da d
en la hora h. As, los precios de las 24 horas de un da se predicen a partir
de los vecinos ms cercanos de los precios horarios de los m das anteriores al
que se quiere predecir. El nmero de atributos que se usan para predecir los
24 atributos correspondientes a los precios del da siguiente se determina de
manera que el radio de crecimiento de las trayectorias de dos puntos cercanos
en el pasado sea mnimo.
El radio de crecimiento de las trayectorias viene dado por el cociente de
dos distancias como se muestra en la gura 4.6, donde:
72
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
A
B
C
D
2
l
1
l
Figura 4.6: Vecinos falsos.
l
1
es la distancia entre los puntos A y C que vienen dados por:
A = (P
i,1
, . . . , P
i,24
, . . . , P
m+(i1),1
, . . . , P
m+(i1),24
) i 1 (4.2)
C = (P
j,1
, . . . , P
j,24
, . . . , P
m+(j1),1
, . . . , P
m+(j1),24
) j 1 (4.3)
l
2
es la distancia entre los puntos B y D que vienen dados por:
B = (P
m+i,1
, . . . , P
m+i,24
) i 1 (4.4)
D = (P
m+j,1
, . . . , P
m+j,24
) j 1 (4.5)
As el radio se puede expresar como sigue:
R =
d
24
(B, D)
d
24m
(A, C)
=
l
2
l
1
(4.6)
donde d
l
es una distancia cualquiera, elegida para medir la similitud entre dos
puntos de R
l
.
En este caso el pseudocdigo del algoritmo de los falsos vecinos ms cerca-
nos se describe como sigue:
73
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Entrada: Base de datos y parmetros num_dias_maximo y R
max
Salida: Numero de vecinos falsos y radio de crecimiento
FalsosVecinosCercanos()
desde num_dias = 1 hasta num_dias = num_dias_maximo
longitud_ventana = 24 num_dias
num_falsos_vecinos = 0
Para todo dia Conjunto de Entrenamiento
Clculo del punto formado por los precios horarios de los num_dias
das anteriores al da dia
Clculo del vecino ms cercano del punto anterior
Clculo del radio de crecimiento R
dia
segn (4.6)
Si R
dia
> R
max
//El vecino calculado es un vecino falso
num_falsos_vecinos = num_falsos_vecinos + 1
Inclusin de los precios del da dia en la base de datos
Fin FalsosVecinosCercanos
Figura 4.7: Pseudocdigo del algoritmo FNN para la serie temporal Precios.
Este algoritmo ha sido aplicado a la base de datos formada por los precios
de la energa, tomando como conjunto de entrenamiento los das laborables
comprendidos entre marzo y agosto del ao 2001. El nmero mximo de das
anteriores (parmetro num_dias_maximo), usado para el clculo de los ve-
cinos ms cercanos que son falsos, ha sido igual a 25, lo cual corresponde
aproximadamente con el nmero de das laborables de un mes completo. El
parmetro R
max
, que representa el umbral a partir del cual un punto consi-
derado vecino ms cercano de otro punto va a ser un vecino falso, ha sido
elegido igual a 1. De esta manera, se consideran buenos vecinos aquellos que
no incrementan su distancia inicial a lo largo del tiempo, es decir o bien la
disminuyen o la conservan pero no la aumentan.
Para el clculo de los vecinos ms cercanos es necesario elegir una mtri-
ca que se adapte a las caractersticas de la serie temporal formada por los
precios de la energa elctrica. En este caso, se ha optado por usar dos dis-
tancias bastante comunes, la distancia Eucldea y la distancia Manhattan, y
establecer una comparacin entre los resultados obtenidos usando ambas en lo
que respecta a la calidad del modelo obtenido, una vez determinados los dos
parmetros principales: la longitud de la ventana y el nmero de vecinos.
74
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Vecinos Cercanos Falsos ( %)
Distancia
Nmero de das Eucldea Manhattan
anteriores
1 79.07 79.07
2 56.59 45.74
3 31.78 15.50
4 23.26 3.88
5 20.16 0
6 10.08 0
7 7.75 0
8 2.33 0
9 3.10 0
10 1.55 0
11 0.78 0
12 0 0
13 0 0
14 0.78 0
15 0 0
16 0 0
17 0 0
18 0 0
19 0 0
20 0 0
21 0 0
22 0.78 0
23 0 0
24 0 0
25 0 0
Tabla 4.1: Porcentaje de vecinos falsos segn distancias.
La tabla 4.1 presenta el porcentaje obtenido de vecinos cercanos que son
falsos cuando stos han sido calculados con dos distancias, la distancia Eucldea
y la distancia Manhattan. Como se puede observar el nmero de vecinos falsos
tiende a cero cuando el nmero de das pasados que forman la longitud de la
ventana aumenta. La longitud ptima de la ventana deslizante es de 5 das
cuando se calculan los vecinos con la distancia Manhattan mientras que con la
distancia Eucldea hacen falta buscar los vecinos ms cercanos de los 12 das
75
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
anteriores al que se quiere predecir para que no haya vecinos falsos. Adems
con esta distancia, aparecen vecinos falsos cuando se consideran 14 22 das lo
cual es un comportamiento irregular que puede ser debido al ruido de la serie
temporal.
0
10
20
30
40
50
60
70
80
90
100
1 3 5 7 9 11 13 15 17 19 21 23 25
Nmero de das anteriores
N
m
e
r
o
d
e
v
e
c
i
n
o
s
f
a
l
s
o
s
(
%
)
Distancia Eucldea
Distancia Manhattan
Figura 4.8: Nmero de vecinos cercanos falsos.
La gura 4.8 muestra cmo el porcentaje de vecinos ms cercanos falsos
disminuye cuando el nmero de das anteriores usados para formar la longitud
de la ventana aumenta tanto para la distancia Eucldea como la distancia
Manhattan.
Una vez determinada la longitud de la ventana deslizante hay que deter-
minar tanto el nmero de vecinos que hacen que el error de la prediccin sea
mnimo como la distancia que mejor se adapte a las caractersticas de la serie
temporal formada por los precios de la energa elctrica.
Para calcular el nmero ptimo de vecinos de una manera estricta hay que
encontrar el mnimo de la funcin objetivo cuadrtica que viene dada por:
t
(P
d,t
P
d,t
)
2
(4.7)
donde
P
d,t
son las predicciones horarias de los precios del da d y la hora t
obtenidas segn el mtodo descrito en el captulo anterior. Estas predicciones
consisten en una suma de k trminos, los cuales son exactamente los precios
76
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Entrada: Base de datos y parmetros num_vecinos_max y
longitud_ventana
Salida: Error de la prediccin
NumeroVecinos()
Construccin de los patrones segn (4.1) con m = longitud_ventana
desde num_vecinos = 1 hasta num_vecinos = num_vecinos_max
Para todo dia Conjunto de Entrenamiento
Clculo de la prediccin del da dia
Clculo del error cometido en la prediccin
Inclusin de los precios reales del da dia en la base de datos
Fin NumeroVecinos
Figura 4.9: Pseudocdigo del algoritmo para obtener el nmero de vecinos.
horarios de los das siguientes a los k vecinos ms cercanos a los precios de los
m das anteriores al da que se quiere predecir, ponderados por un factor de
peso.
En la prctica, esta funcin objetivo es una funcin discreta y el clculo
del mnimo se hace de una manera heurstica ya que no se puede aplicar nin-
gn mtodo clsico de optimizacin cuadrtica. El pseudocdigo del algoritmo
aplicado para calcular el nmero ptimo de vecinos, que se utilizar en la pre-
diccin de los precios de la energa para un conjunto de ejemplos cualesquiera,
se muestra en la gura 4.9.
Este algoritmo ha sido aplicado a la base de datos formada por los precios
de la energa, tomando como conjunto de entrenamiento los das laborables
comprendidos entre marzo y agosto del ao 2001. La longitud de la ventana ha
sido de 5 das cuando se ha usado la distancia Manhattan y de 12 das cuando
se ha usado la distancia Eucldea para el clculo de los k vecinos ms cercanos.
El nmero mximo de vecinos (parmetro num_vecinos_max) ha sido igual
a 10, ya que en la prctica slo se necesitan un nmero pequeo de valores
diferentes de k para encontrar el valor ptimo.
La gura 4.10 presenta la inuencia del nmero de vecinos sobre los errores
relativos, absolutos y cuadrticos medios obtenidos en la prediccin de los
precios de la energa horaria para el conjunto de entrenamiento considerado,
siendo la distancia para evaluar la similitud entre los precios de los 12 das
anteriores y los datos histricos, la distancia Eucldea.
Anlogamente a la gura anterior, la gura 4.11 presenta la inuencia del
nmero de vecinos sobre los errores relativos, absolutos y cuadrticos medios
77
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
obtenidos en la prediccin de los precios de la energa horaria para el mis-
mo conjunto de entrenamiento, siendo la distancia para evaluar la similitud
entre los precios de los 5 das anteriores y los datos histricos, la distancia
Manhattan.
0.14
0.16
0.18
0.20
0.22
0.24
0.26
0.28
0.30
0.32
1 2 3 4 5 6 7 8 9 10
Nmero de Vecinos
E
r
r
o
r
A
b
s
o
l
u
t
o
y
C
u
a
d
r
t
i
c
o
M
e
d
i
o
9.9
10.1
10.3
10.5
10.7
10.9
11.1
11.3
11.5
11.7
11.9
E
r
r
o
r
R
e
l
a
t
i
v
o
M
e
d
i
o
(
%
)
Error Absoluto Medio
Error Cuadratico Medio
Error Relativo Medio (%)
Figura 4.10: Nmero ptimo de vecinos usando la distancia Eucldea.
0.14
0.16
0.18
0.20
0.22
0.24
0.26
0.28
0.30
0.32
1 2 3 4 5 6 7 8 9 10
Nmero de Vecinos
E
r
r
o
r
A
b
s
o
l
u
t
o
y
C
u
a
d
r
t
i
c
o
M
e
d
i
o
9.9
10.1
10.3
10.5
10.7
10.9
11.1
11.3
11.5
11.7
11.9
E
r
r
o
r
R
e
l
a
t
i
v
o
M
e
d
i
o
(
%
)
Error Absoluto Medio
Error Cuadratico Medio
Error Relativo Medio (%)
Figura 4.11: Nmero ptimo de vecinos usando la distancia Manhattan.
78
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
De estas guras se pueden obtener, para la serie temporal de los precios de
la energa elctrica en Espaa, las siguientes conclusiones:
1. El nmero ptimo de vecinos es igual a cuatro usando la distancia Eu-
cldea, mientras que es igual a cinco usando la distancia Manhattan.
Consecuentemente, este nmero depende de la distancia elegida para el
clculo de los vecinos ms cercanos.
2. El nmero ptimo de vecinos es independiente del tipo de error usado
como funcin objetivo a minimizar, ya que, por ejemplo, para la distancia
Eucldea, el nmero ptimo es cuatro tanto para el error relativo medio
como para el absoluto y cuadrtico.
Como resultado se han obtenido los modelos siguientes:
Con la distancia Eucldea, se han obtenido mediante el mtodo de los
falsos vecinos ms cercanos los siguientes patrones:
P
1,1
P
1,24
P
12,1
P
12,24
P
13,1
P
13,24
P
2,1
P
2,24
P
13,1
P
13,24
P
14,1
P
14,24
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(4.8)
y el nmero de ejemplos cercanos que se usarn en la prediccin son
cuatro.
Con la distancia Manhattan, se han obtenido mediante el mtodo de los
falsos vecinos ms cercanos los siguientes patrones:
P
1,1
P
1,24
P
5,1
P
5,24
P
6,1
P
6,24
P
2,1
P
2,24
P
6,1
P
6,24
P
7,1
P
7,24
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(4.9)
y el nmero de ejemplos cercanos que se usarn en la prediccin son
cinco.
En ambos casos, la ventana se va desplazando veinticuatro atributos cada vez
que se predicen los precios de la energa para las veinticuatro horas de un da.
4.3.2. Con prediccin iterada
Con este tipo de prediccin la estructura de los patrones es la siguiente:
X
1
X
m
X
m+1
X
2
X
m+1
X
m+2
.
.
.
.
.
.
.
.
.
.
.
.
(4.10)
79
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
As, el precio de una hora se predice a partir de los vecinos ms cercanos de
los precios horarios de las m horas anteriores a la hora que se quiere predecir.
Como el objetivo del problema es predecir los precios de las 24 horas del da
siguiente, es decir, el horizonte de prediccin es de 24 horas, este proceso se
repite hasta que se obtienen los precios de las 24 horas de un da. El nmero
de atributos que se usan para predecir el atributo correspondiente al precio de
la hora siguiente se determina de manera que el radio de crecimiento de las
trayectorias de dos puntos cercanos en el pasado sea mnimo.
El radio de crecimiento de las trayectorias viene dado por el cociente de
dos distancias como se muestra en la gura 4.6, donde:
l
1
es la distancia entre los puntos A y C que vienen dados por:
A = (X
i
, . . . , X
m+(i1)
) i 1 (4.11)
C = (X
j
, . . . , X
m+(j1)
) j 1 (4.12)
l
2
es la distancia entre los puntos B y D que vienen dados por:
B = X
m+i
i 1 (4.13)
D = X
m+j
j 1 (4.14)
As el radio se puede expresar como sigue:
R =
|B D|
d
m
(A, C)
=
l
2
l
1
(4.15)
donde d
m
es una distancia cualquiera, elegida para medir la similitud entre dos
puntos de R
m
y | | es la funcin valor absoluto.
En este caso el pseudocdigo del algoritmo de los falsos vecinos ms cerca-
nos se describe en la gura 4.12.
Bsicamente, la principal diferencia entre los algoritmos FNN (guras 4.7
y 4.12) es que en el primero se hace un tratamiento por das mientras que en
el segundo el tratamiento se hace por horas.
Este algoritmo ha sido aplicado a la base de datos formada por los precios
de la energa, tomando como conjunto de entrenamiento los das laborables
comprendidos entre marzo y agosto del ao 2001. El nmero mximo de horas
anteriores (parmetro num_horas_max), usado para el clculo de los vecinos
ms cercanos que son falsos, ha sido igual a 24, lo cual corresponde con el
nmero de horas de un da completo. El parmetro R
max
, que representa el
umbral a partir del cual un punto considerado vecino ms cercano de otro
punto va a ser un vecino falso, ha sido elegido igual a 1. De esta manera, se
80
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Entrada: Base de datos y parmetros num_horas_max y R
max
Salida: Numero de vecinos falsos y radio de crecimiento
FalsosVecinosCercanos()
desde num_horas = 1 hasta num_horas = num_horas_max
num_falsos_vecinos = 0
Para toda dia Conjunto de Entrenamiento
Para toda hora dia
Clculo del punto formado por los precios de las num_horas
horas anteriores a la hora hora
Clculo del vecino ms cercano del punto anterior
Clculo del radio de crecimiento R
dia
segn (4.15)
Si R
dia
> R
max
//El vecino calculado es un vecino falso
num_falsos_vecinos = num_falsos_vecinos + 1
Inclusin de los precios reales de la hora hora en la base de datos
Fin FalsosVecinosCercanos
Figura 4.12: Pseudocdigo del algoritmo FNN para la serie temporal Precios.
consideran buenos vecinos aquellos que no incrementan su distancia inicial a
lo largo del tiempo, es decir o bien la disminuyen o la conservan, con lo cual
las trayectorias no divergen.
Anlogamente a la prediccin directa, para el clculo de los vecinos ms
cercanos se han usado la distancia Eucldea y la distancia Manhattan, estable-
cindose una comparacin entre los resultados obtenidos usando ambas, en lo
que respecta a la calidad del modelo obtenido, una vez determinados los dos
parmetros principales: la longitud de la ventana y el nmero de vecinos.
La tabla 4.2 presenta el porcentaje obtenido de vecinos cercanos que son
falsos cuando stos han sido calculados con esas dos distancias. Como se puede
observar el nmero de vecinos falsos tiende a cero cuando el nmero de horas
anteriores que forman la longitud de la ventana aumenta. Cuando se calculan
los vecinos tanto con la distancia Manhattan como con la distancia Eucldea,
hacen falta buscar los vecinos ms cercanos de las 24 horas anteriores a la hora
que se quiere predecir, aun obteniendo as un 1.91 % y 2.62 % de vecinos falsos
respectivamente.
81
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Vecinos Cercanos Falsos ( %)
Distancia
Nmero de horas Eucldea Manhattan
anteriores
1 99.77 99.90
2 90.67 95.93
3 77.91 87.60
4 65.08 78.17
5 54.97 68.70
6 43.51 59.40
7 34.75 48.68
8 27.65 37.95
9 21.87 31.10
10 15.63 24.29
11 12.66 17.38
12 9.30 12.79
13 7.27 8.62
14 7.40 8.33
15 10.56 9.98
16 10.98 9.98
17 10.24 8.88
18 8.79 7.24
19 4.81 5.78
20 4.20 6.85
21 4.46 6.78
22 5.20 5.75
23 4.33 4.17
24 2.62 1.91
Tabla 4.2: Porcentaje de vecinos falsos segn distancias.
La gura 4.13 muestra cmo disminuye el porcentaje de falsos precios ve-
cinos cuando aumenta el nmero de precios de horas anteriores usados para
predecir la hora siguiente. Como se observa, veinticuatro horas anteriores son
sucientes para predecir la hora siguiente con ambas distancias, la distancia
Manhattan y la distancia Eucldea, aunque el porcentaje de falsos vecinos
usando las 24 horas anteriores es 1.91 % y 2.62 %, respectivamente. El com-
portamiento irregular en las horas comprendidas entre las 14 horas y 17 horas
puede ser debido al ruido de la serie temporal.
82
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
0
10
20
30
40
50
60
70
80
90
100
1 3 5 7 9 11 13 15 17 19 21 23
Nmero de horas anteriores
N
m
e
r
o
d
e
v
e
c
i
n
o
s
f
a
l
s
o
s
(
%
)
Distancia Manhattan
Distancia Eucldea
Figura 4.13: Nmero de vecinos cercanos falsos.
Una vez determinada la longitud de la ventana deslizante hay que deter-
minar el nmero de ejemplos que se usarn en la prediccin.
Para calcular el nmero ptimo de vecinos de una manera estricta hay que
encontrar el mnimo de la funcin objetivo cuadrtica que viene dada por:
t
(P
d,t
P
d,t
)
2
(4.16)
donde
P
d,t
son las predicciones horarias de los precios del da d obtenidas
segn el mtodo descrito en el captulo anterior. Estas predicciones consisten
en una suma de k trminos, los cuales son exactamente los precios de las horas
siguientes a los k vecinos ms cercanos a los precios de las m horas anteriores
a la hora que se quiere predecir, ponderados por un factor de peso.
En la prctica, el pseudocdigo del algoritmo aplicado para calcular el
nmero ptimo de vecinos, que se utilizar en la prediccin de un conjunto de
ejemplos cualesquiera, se muestra en la gura 4.14.
Este algoritmo ha sido aplicado a la base de datos formada por los precios
de la energa, tomando como conjunto de entrenamiento los das laborables
comprendidos entre marzo y agosto del ao 2001. La longitud de la ventana
ha sido de 24 horas cuando se ha usado la distancia Manhattan y la distancia
Eucldea para el clculo de los k vecinos ms cercanos. El nmero mximo de
vecinos (parmetro num_vecinos_max) ha sido igual a 20.
83
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Entrada: Base de datos y parmetros num_vecinos_max y
longitud_ventana
Salida: Error de la prediccin
NumeroVecinos()
Construccin de los patrones segn (4.10) con m = longitud_ventana
desde num_vecinos = 1 hasta num_vecinos = num_vecinos_max
Para todo dia Conjunto de Entrenamiento
Para toda hora dia
Clculo del punto formado por los precios de las num_horas
horas anteriores a la hora hora
Clculo del vecino ms cercano del punto anterior
Clculo de la prediccin de la hora hora del da dia
Clculo del error cometido en la prediccin
Inclusin del precio real de la hora hora en la base de datos
Fin NumeroVecinos
Figura 4.14: Pseudocdigo del algoritmo para obtener el nmero de vecinos.
La gura 4.15 presenta la inuencia del nmero de vecinos sobre los errores
relativos, absolutos y cuadrticos medios obtenidos en la prediccin de los
precios de la energa horaria para el conjunto de entrenamiento considerado,
siendo la distancia para evaluar la similitud entre los precios del da antes y
los datos histricos, la distancia Eucldea.
Anlogamente a la gura anterior, la gura 4.16 presenta la inuencia del
nmero de vecinos sobre los errores relativos, absolutos y cuadrticos medios
obtenidos en la prediccin de los precios de la energa horaria para el mismo
conjunto de entrenamiento, habiendo usado para el clculo de los vecinos la
distancia Manhattan.
Mediante una prediccin iterada, para los precios de la energa elctrica en
Espaa se obtienen las siguientes conclusiones:
1. El nmero ptimo de vecinos es igual a cinco usando la distancia Eucl-
dea, mientras que es igual a siete usando la distancia Manhattan.
2. El nmero ptimo de vecinos es independiente del tipo de error usado
como funcin objetivo a minimizar.
84
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
0.2
0.22
0.24
0.26
0.28
0.3
0.32
0.34
0.36
1 3 5 7 9 11 13 15 17 19
Nmero de Vecinos
E
r
r
o
r
A
b
s
o
l
u
t
o
y
C
u
a
d
r
a
t
i
c
o
M
e
d
i
o
7.9
8.1
8.3
8.5
8.7
8.9
9.1
E
r
r
o
r
R
e
l
a
t
i
v
o
M
e
d
i
o
(
%
)
Error Absoluto Medio
Error Cuadratico Medio
Error Relativo Medio (%)
Figura 4.15: Nmero ptimo de vecinos usando la distancia Eucldea.
0.2
0.22
0.24
0.26
0.28
0.3
0.32
0.34
0.36
1 3 5 7 9 11 13 15 17 19
Nmero de Vecinos
E
r
r
o
r
A
b
s
o
l
u
t
o
y
C
u
a
d
r
t
i
c
o
M
e
d
i
o
7.9
8.1
8.3
8.5
8.7
8.9
9.1
E
r
r
o
r
R
e
l
a
t
i
v
o
M
e
d
i
o
(
%
)
Error Absoluto Medio
Error Cuadratico Medio
Error Relativo Medio (%)
Figura 4.16: Nmero ptimo de vecinos usando la distancia Manhattan.
Como resultado tanto con la distancia Eucldea como con la distancia Man-
hattan, se han obtenido mediante el mtodo de los falsos vecinos ms cercanos
85
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
los siguientes patrones:
P
1,1
P
1,24
P
2,1
P
1,2
P
2,1
P
2,2
.
.
.
.
.
.
.
.
.
.
.
.
(4.17)
y el nmero de ejemplos cercanos que se usarn en la prediccin son cinco con
la distancia Eucldea y siete con la distancia Manhattan.
En ambos casos, la ventana se desplaza un atributo cada vez que se pre-
dice el precio de la energa para una hora de un da, as hasta obtener las
predicciones para las 24 horas de ese da.
4.4. Prediccin. Resultados
En esta seccin se describe la tcnica basada en los k vecinos ms cercanos
aplicada a la serie temporal formada por los precios de la energa tanto si se
hace un tipo de prediccin directa como iterada.
4.4.1. Con prediccin directa
Esta prediccin consiste en estimar los precios de la energa de maana
como una media de los precios de la energa de los das siguientes a los k
vecinos de los m das anteriores al da de maana, siendo m la longitud de
ventana ptima obtenida en la seccin 4.3.1.
Esta media est ponderada con unos pesos que representan la importancia
de los precios similares segn su mayor o menor parecido. Al precio de la energa
del da siguiente al vecino ms cercano de los m das anteriores a maana le
corresponde un peso mayor que al precio de la energa del da siguiente al
vecino ms lejano de los m das anteriores a maana.
Bsicamente, en este mtodo se usa una media local ponderada con unos
pesos para la estimacin de la prediccin. Y el criterio para determinar los
precios que forman parte de esta media est basado en la similitud entre pre-
cios. De ah la importancia de elegir una distancia que mida la similitud entre
precios de una manera adecuada a las caractersticas especcas de la serie que
se est tratando de predecir.
De esta manera, la prediccin de los precios de la energa del da d+1 viene
dada por:
P
d+1
=
1
1
+... +
k
k
j=1
j
P
v
j
(x(d))+1
(4.18)
86
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
donde v
j
(x(d)) son los k precios vecinos a los precios de los m das anteriores
al da d + 1, ordenados desde el ms cercano al ms lejano y donde los pesos
vienen dados por:
j
=
d(P
x(d)
, P
v
k
(x(d))
) d(P
x(d)
, P
v
j
(x(d))
)
d(P
x(d)
, P
v
k
(x(d))
) d(P
x(d)
, P
v
1
(x(d))
)
(4.19)
El peso
j
es igual a cero cuando j corresponde a los precios considerados ms
lejanos y uno cuando los precios considerados son los ms cercanos.
Estos pesos han sido elegidos porque dan lugar a una buena aproximacin
de la prediccin, sin embargo otras alternativas para proporcionar pesos a los
vecinos sern analizadas en unas futuras lneas de investigacin comparando
los resultados que se obtengan con los resultados obtenidos en esta tesis.
El pseudocdigo del algoritmo de prediccin se muestra en la gura 4.17.
Entrada: Patrones, distancia y parmetros num_vecinos y
longitud_ventana
Salida: Prediccin de todos los das de un conjunto
Prediccion()
Para todo dia Conjunto Test
Construccin del punto formado por los precios de los
longitud_ventana das anteriores al da dia
Clculo de los num_vecinos vecinos ms cercanos segn la distan-
cia elegida
Clculo de los pesos segn (4.19)
Clculo de la prediccin del da dia segn (4.18)
Inclusin de los precios reales del da dia en los patrones
Fin Prediccion
Figura 4.17: Pseudocdigo del algoritmo para obtener predicciones.
Este algoritmo se ha aplicado a la serie temporal formada por los precios
para obtener la prediccin de los das laborables comprendidos entre septiembre
y octubre del ao 2001. El conjunto de datos empleado para la obtencin
y validacin del modelo de prediccin han sido los das comprendidos entre
marzo y octubre del ao 2001. Las dos terceras partes de los datos han sido
elegidas como conjunto de entrenamiento correspondiendo a 6 meses (marzo,
abril, mayo, junio, julio y agosto) y una tercera parte como conjunto de test
correspondiendo a 2 meses (septiembre y octubre). Aunque el conjunto de test
no es un conjunto de test en el sentido clsico, ya que cada vez que se predice
87
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
un da del conjunto de test este da es incluido en la base de datos para predecir
de nuevo el siguiente da del conjunto de test. As se consigue un aprendizaje
incremental en el mtodo de prediccin presentado en esta tesis.
La tabla 4.3 muestra los valores medios y la desviacin estndar de los
precios correspondientes a septiembre y octubre del ao 2001.
Las guras 4.18 y 4.19 presentan la media horaria de la prediccin de los
precios obtenida y la media horaria de los precios reales para los das laborables
del conjunto test seleccionado, tanto si se usa la distancia Eucldea como la
distancia Manhattan, siendo el error medio de la prediccin 7.8 % y 9.25 %,
respectivamente.
Las guras 4.20 y 4.21 presentan la media diaria de la prediccin de los
precios obtenida y la media diaria de los precios reales para los das laborables
del conjunto test seleccionado, tanto si se usa la distancia Eucldea como la
distancia Manhattan, respectivamente.
Las guras 4.22 y 4.23 muestran la media diaria del error relativo cometido
en la prediccin de los precios del conjunto test seleccionado, tanto si se usa
la distancia Eucldea como la distancia Manhattan, respectivamente. Como se
puede observar, cuando se ha usado la distancia Eucldea como mtrica, el da
en el que se ha obtenido el menor y mayor error relativo corresponde con el
18 de septiembre (da 12) y el 26 de octubre (da 39) con un error de 2.1 %
y 18.6 %, respectivamente. Sin embargo, con la distancia Manhattan el da en
el que se ha obtenido el menor y mayor error relativo corresponde con el 6 de
septiembre (da 4) y al 31 de octubre (da 43) con un error de 1.7 % y 20.3 %,
respectivamente. La mala prediccin obtenida para el da 31 de octubre es
debida a que este da es el da anterior a un da festivo en Espaa como es el
da 1 de noviembre, da de todos los santos.
Septiembre Octubre
Precio real medio 3.35 3.996
Desviacin Estndar 0.43 0.606
Tabla 4.3: Media y desviacin estndar del conjunto test.
88
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
2
2.5
3
3.5
4
4.5
5
5.5
1 3 5 7 9 11 13 15 17 19 21 23
Horas
P
r
e
c
i
o
s
(
c
e
n
t
/
k
W
h
)
Prediccin
Precios reales
Figura 4.18: Media horaria de la prediccin usando la distancia Eucldea.
2
2.5
3
3.5
4
4.5
5
5.5
1 3 5 7 9 11 13 15 17 19 21 23
Horas
P
r
e
c
i
o
s
(
c
e
n
t
/
k
W
h
)
Prediccin
Precios reales
Figura 4.19: Media horaria de la prediccin usando la distancia Manhattan.
89
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
3
3.5
4
4.5
5
5.5
1 4 7 10 13 16 19 22 25 28 31 34 37 40
Das
P
r
e
c
i
o
s
(
c
e
n
t
/
k
W
h
)
Prediccin diaria
Precios diarios
Figura 4.20: Media diaria de la prediccin usando la distancia Eucldea.
3
3.5
4
4.5
5
5.5
1 4 7 10 13 16 19 22 25 28 31 34 37 40
Das
P
r
e
c
i
o
s
(
c
e
n
t
/
k
W
h
)
Prediccin diaria
Precios diarios
Figura 4.21: Media diaria de la prediccin usando la distancia Manhattan.
90
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0.18
0.20
0.22
1 4 7 10 13 16 19 22 25 28 31 34 37 40
Das
E
r
r
o
r
r
e
l
a
t
i
v
o
d
i
a
r
i
o
3
3.5
4
4.5
5
5.5
P
r
e
c
i
o
s
d
i
a
r
i
o
s
Error relativo diario
Precios diarios
Figura 4.22: Media diaria del error relativo usando la distancia Eucldea.
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0.18
0.20
0.22
1 4 7 10 13 16 19 22 25 28 31 34 37 40
Das
E
r
r
o
r
r
e
l
a
t
i
v
o
d
i
a
r
i
o
3
3.5
4
4.5
5
5.5
P
r
e
c
i
o
s
d
i
a
r
i
o
s
Error relativo diario
Precios diarios
Figura 4.23: Media diaria del error relativo usando la distancia Manhattan.
91
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Estos resultados se resumen en la tabla 4.4 que se muestra a continuacin.
Distancia Eucldea Distancia Manhattan
Septiembre Octubre Septiembre Octubre
Error Relativo Medio ( %) 6 9.6 8 10.5
Error Absoluto Medio 0.25 0.38 0.33 0.407
Mximo error diario ( %) 18 18.6 19.57 20.3
Mximo error horario ( %) 66.02 88.08 68.9 90.43
Mnimo error diario ( %) 2.07 3.97 1.69 4.458
Mnimo error horario ( %) 0.03 0.0 0.02 0.0
Tabla 4.4: Errores segn distancias.
Como se puede observar en la tabla anterior, el primer modelo obtenido con
la distancia Eucldea en el que se buscan los vecinos de los 12 das anteriores
al da que se quiere predecir y se usan los 4 vecinos ms cercanos para la
prediccin del nuevo ejemplo da lugar a mejores resultados que el segundo
modelo obtenido a partir de la distancia Manhattan, ya que en el mes de
septiembre y octubre se obtienen unas reducciones de un 2 % y un 1 % en el
error relativo medio con respecto a los errores obtenidos en esos meses a partir
del segundo modelo.
4.4.2. Con prediccin iterada
Esta prediccin consiste en estimar el precio de la energa de la hora si-
guiente como una media de los precios de la energa de las horas siguientes a
los k vecinos ms cercanos a las m horas anteriores a la hora que se quiere
predecir, siendo m la longitud de la ventana ptima obtenida en la seccin
4.3.2.
Esta media est ponderada con unos pesos que representan la importancia
de los precios similares segn su mayor o menor parecido.
De esta manera, la prediccin de los precios de la energa en la hora h + 1
viene dada por:
P
h+1
=
1
1
+... +
k
k
j=1
j
P
v
j
(x(h))+1
(4.20)
donde v
j
(x(h)) son los k precios vecinos a los precios de las m horas anteriores
a la hora h+1, ordenados desde el ms cercano al ms lejano y donde los pesos
92
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
vienen dados por:
j
=
d(P
x(h)
, P
v
k
(x(h))
) d(P
x(h)
, P
v
j
(x(h))
)
d(P
x(h)
, P
v
k
(x(h))
) d(P
x(h)
, P
v
1
(x(h))
)
(4.21)
Estos pesos han sido elegidos porque dan lugar a una buena aproximacin
de la prediccin, sin embargo otras alternativas para proporcionar pesos a los
vecinos sern analizadas en unas futuras lneas de investigacin comparando
los resultados que se obtengan con los resultados obtenidos en esta tesis.
El pseudocdigo del algoritmo se muestra en la gura 4.24.
Entrada: Patrones, distancia y parmetros num_vecinos y
longitud_ventana
Salida: Prediccin de todos los das de un conjunto
Prediccion()
Para todo dia Conjunto Test
Para toda hora dia
Construccin del punto formado por los precios de las
longitud_ventana horas anteriores a la hora hora
Clculo de los num_vecinos vecinos ms cercanos segn la dis-
tancia elegida
Clculo de los pesos segn (4.21)
Clculo de la prediccin de la hora hora segn (4.20)
Inclusin de la prediccin de la hora hora en los patrones
Inclusin de los precios reales del da dia en los patrones
Fin Prediccion
Figura 4.24: Pseudocdigo del algoritmo para obtener predicciones.
Este algoritmo se ha aplicado a la serie temporal formada por los precios
para obtener la prediccin de los das laborables comprendidos entre septiembre
y octubre del ao 2001.
Las guras 4.25 y 4.26 presentan la media horaria de la prediccin de los
precios obtenida y la media horaria de los precios reales para los das laborables
del conjunto test seleccionado, tanto si se usa la distancia Eucldea como la
distancia Manhattan, siendo el error medio de la prediccin 9.2 % en ambos
casos.
93
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
2
2.5
3
3.5
4
4.5
5
5.5
1 3 5 7 9 11 13 15 17 19 21 23
Horas
P
r
e
c
i
o
s
(
c
e
n
t
/
k
W
h
)
Prediccion
Precios reales
Figura 4.25: Media horaria de la prediccin usando la distancia Eucldea.
2
2.5
3
3.5
4
4.5
5
5.5
1 3 5 7 9 11 13 15 17 19 21 23
Horas
P
r
e
c
i
o
s
(
c
e
n
t
/
k
W
h
)
Prediccion
Precios reales
Figura 4.26: Media horaria de la prediccin usando la distancia Manhattan.
Las guras 4.27 y 4.28 presentan la media diaria de la prediccin de los
precios obtenida y la media diaria de los precios reales para los das laborables
del conjunto test seleccionado, tanto si se usa la distancia Eucldea como la
distancia Manhattan, respectivamente.
94
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
3
3.5
4
4.5
5
5.5
1 4 7 10 13 16 19 22 25 28 31 34 37 40
Das
P
r
e
c
i
o
s
(
c
e
n
t
/
k
W
h
)
Prediccin diaria
Precios diarios
Figura 4.27: Media diaria de la prediccin usando la distancia Eucldea.
3
3.5
4
4.5
5
5.5
1 4 7 10 13 16 19 22 25 28 31 34 37 40
Das
P
r
e
c
i
o
s
(
c
e
n
t
/
k
W
h
)
Prediccin diaria
Precios diarios
Figura 4.28: Media diaria de la prediccin usando la distancia Manhattan.
Las guras 4.29 y 4.30 muestran la media diaria del error relativo cometido
en la prediccin de los precios del conjunto test seleccionado, tanto si se usa
la distancia Eucldea como la distancia Manhattan, respectivamente. Como
se puede observar, cuando se ha usado la distancia Eucldea como mtrica, el
da en el que se ha obtenido el menor y mayor error relativo corresponde con
el 6 de septiembre (da 4) y el 26 de octubre (da 39) con un error de 3 % y
21.66 %, respectivamente. Sin embargo, con la distancia Manhattan el da en
el que se ha obtenido el menor y mayor error relativo corresponde con el 21
95
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
de septiembre (da 15) y el 26 de octubre (da 39) con un error de 2.89 % y
21.55 %, respectivamente.
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0.18
0.20
0.22
1 4 7 10 13 16 19 22 25 28 31 34 37 40
Das
E
r
r
o
r
r
e
l
a
t
i
v
o
d
i
a
r
i
o
3
3.5
4
4.5
5
5.5
P
r
e
c
i
o
s
d
i
a
r
i
o
s
Error Relativo diario
Precios diarios
Figura 4.29: Media diaria del error relativo usando la distancia Eucldea.
0.00
0.02
0.04
0.06
0.08
0.10
0.12
0.14
0.16
0.18
0.20
0.22
1 4 7 10 13 16 19 22 25 28 31 34 37 40
Das
E
r
r
o
r
r
e
l
a
t
i
v
o
d
i
a
r
i
o
3
3.5
4
4.5
5
5.5
P
r
e
c
i
o
s
d
i
a
r
i
o
s
Error Relativo diario
Precios diarios
Figura 4.30: Media diaria del error relativo usando la distancia Manhattan.
96
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Estos resultados se resumen en la tabla 4.5 que se muestra a continuacin.
Distancia Eucldea Distancia Manhattan
Septiembre Octubre Septiembre Octubre
Error Relativo Medio ( %) 7.3 11 7.11 11.27
Error Absoluto Medio 0.289 0.427 0.282 0.436
Mximo error diario ( %) 15.88 21.66 15.628 21.558
Mximo error horario ( %) 75.9 94.7 88.9 93.3
Mnimo error diario ( %) 3 4.879 2.89 4.49
Mnimo error horario ( %) 0.0 0.0 0.0 0.0
Tabla 4.5: Errores segn distancias.
Como se puede observar en la tabla anterior, tanto el primer modelo obte-
nido con la distancia Eucldea como el segundo modelo obtenido a partir de la
distancia Manhattan, tienen un comportamiento parecido puesto que los erro-
res se encuentran en los mismos rangos. Sin embargo, se puede observar que en
general los resultados obtenidos con una prediccin directa que se muestran en
la tabla 4.4 son mejores que los obtenidos con un tipo de prediccin iterada.
Esto es debido a que los errores de la prediccin se van acumulando en el vector
de entrada sobre todo en las ltimas horas del horizonte de prediccin. Adems
cuando la prediccin se hace hora a hora como ocurre cuando se hace un tipo
de prediccin iterada el coste computacional del mtodo de prediccin basado
en la bsqueda de los vecinos ms cercanos es ms elevado que si la prediccin
se hace da a da, ya que la base de datos es ms grande lo que conlleva recorrer
un mayor nmero de ejemplos para la bsqueda de los vecinos.
4.5. Anlisis heurstico del error
En esta seccin se aplica el estudio del error mnimo descrito en la seccin
3.5 del Captulo 3 a la serie temporal formada por los precios de la energa
elctrica.
La prediccin ptima de los precios de la energa de maana se estima con
los precios ms cercanos a los precios reales de la energa de maana, es decir:
P
d+1
= v(P
d+1
) donde v(P
d+1
) es tal que d(v(P
d+1
), P
d+1
) es mnima (4.22)
La tabla 4.6 muestra los valores de los distintos tipos de errores, obtenidos
mediante la prediccin ptima de los precios de la energa, descrita en esta
97
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
seccin, segn la distancia usada para el clculo de un nico precio vecino.
Ntese que, el error cuadrtico medio mnimo se obtiene cuando se usa la
distancia Eucldea y el error absoluto medio mnimo se obtiene cuando se usa
la distancia Manhattan, como se ha demostrado tericamente.
Prediccin ptima
Distancia Eucldea Distancia Manhattan
Error Cuadrtico Medio 0.114 0.126
Error Absoluto Medio 0.226 0.216
Error Relativo Medio ( %) 5.77 5.55
Tabla 4.6: Inuencia de la distancia en la optimizacin de los distintos tipos
de errores.
Las diferencias entre los errores obtenidos en la prediccin y los errores
ptimos que muestra la tabla 4.6 son aproximadamente un 2.5 % cuando se
usa la distancia Eucldea y un 4 % cuando se usa la distancia Manhattan. Esta
desviacin del error medio ptimo en los meses de septiembre y octubre del
ao 2001 es debida principalmente a los precios que son considerados falsos
vecinos.
4.6. Comparacin con Redes Neuronales
En esta seccin se hace una breve descripcin de los aspectos ms destaca-
dos de la red neuronal perceptron multicapa usada para obtener la prediccin
de los precios de la energa en el Mercado Elctrico Espaol.
4.6.1. Estructura de la red neuronal
Una red neuronal perceptron multicapa est formada por un cierto nmero
de neuronas organizadas en capas, donde cada capa tiene varias entradas y una
nica salida cuyo valor es funcin no lineal de las entradas. Las entradas de
cada capa estn ponderadas por un factor de peso el cual debe ser determinado
durante la fase de entrenamiento. Usualmente en la prediccin de precios, una
red neuronal est formada por tres capas, de entrada, intermedia y de salida,
donde las salidas de una capa son las entradas de la capa siguiente.
Los dos pasos principales en el uso de una red neuronal son los que siguen:
Determinar su topologa, que consiste bsicamente en determinar el n-
mero de neuronas de la capa intermedia.
98
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Obtener los factores de peso de las entradas para una funcin no lineal
determinada en el proceso de entrenamiento.
La red usada en esta tesis se alimenta a travs de una ventana deslizante
formada por los precios correspondientes a 24 horas, lo cual signica que la capa
de entrada est formada por 24 neuronas. En cuanto al nmero de neuronas
de salida se han evaluado dos posibilidades:
a) Una nica salida cuyo valor viene determinado por las 24 horas pre-
vias. Bajo este esquema muy popular en la prediccin de la demanda, la
ventana deslizante es desplazada una hora cada vez.
b) Veinticuatro salidas correspondientes a los precios de un da entero, cuyos
valores vienen determinados por los valores de los das previos. En este
caso la ventana se desliza 24 horas cada vez.
Los resultados han demostrado una mejor aproximacin con el esquema b),
el cual es el nico que se considera en lo que sigue.
Para terminar de denir la estructura de la red neuronal es necesario de-
terminar el nmero de neuronas de la capa intermedia y el nmero de das
requeridos para el proceso de entrenamiento de la red.
0
0.2
0.4
0.6
0.8
1
1.2
1.4
1.6
0 5 10 15 20 25 30 35 40 45
Das
E
r
r
o
r
(
c
e
n
t
/
k
W
h
)
12 neuronas
24 neuronas
36 neuronas
Figura 4.31: Error medio de la prediccin.
La gura 4.31 muestra el error medio cometido en la prediccin de los
precios de la energa correspondientes a los das laborables de febrero del ao
2001, cuando se han usado 12, 24 y 36 neuronas en la capa intermedia frente al
99
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
nmero de das usados para entrenar la red. Se puede observar que 20 das son
sucientes para entrenar la red y que el nmero de neuronas no es demasiado
importante.
En los resultados que se muestran a continuacin se han usado 24 neuronas
en la capa intermedia para obtener la prediccin de los precios de la energa.
4.6.2. Resultados
Los das laborables comprendidos entre enero y febrero del ao 2001 se han
usado en varios experimentos para encontrar y ajustar la topologa de la red,
mientras que los das comprendidos entre marzo y octubre del 2001 se han
elegido para chequear los errores cometidos en la prediccin.
La gura 4.32 presenta el error absoluto de la prediccin de los precios en
el mercado, para los dos das que dan lugar a los mayores y menores errores
medios en el mes de marzo, los cuales corresponden con el lunes 12 de marzo
del ao 2001 y el viernes 23 de marzo del ao 2001 respectivamente.
0.0
0.5
1.0
1.5
2.0
2.5
3.0
1 3 5 7 9 11 13 15 17 19 21 23
Horas
E
r
r
o
r
(
c
e
n
t
/
k
W
h
)
viernes 23
lunes 12
Figura 4.32: Error absoluto de la mejor y peor prediccin.
La gura 4.33 presenta la media horaria de la prediccin de los precios del
mes de marzo y los errores de la prediccin en dicho mes. Los errores de la
prediccin son mayores en las horas punta (horas en las que la demanda de
energa elctrica es alta).
100
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
0
0.5
1
1.5
2
2.5
3
3.5
1 3 5 7 9 11 13 15 17 19 21 23
Horas
c
e
n
t
/
k
W
h
Errores
Prediccin
Figura 4.33: Media horaria de la prediccin de los precios para el mes de marzo.
Finalmente, la tabla 4.7 presenta la media y desviacin estndar (s. d.)
de los precios reales, los errores absolutos y relativos medios y los mximos
errores para las estaciones de primavera y verano y para dos meses de otoo,
septiembre y octubre. Los errores relativos varan desde un 12 % que se comete
en los meses de verano hasta un 15 % obtenido en los meses comprendidos en
la primavera.
Precios Diarios (cntimos/kWh)
marzo-mayo junio-agosto septiembre-octubre
Precio real 2.2588 3.5482 3.673
s. d. 0.7801 1.0597 0.518
Error absoluto medio 0.3464 0.428 0.576
Mximo error horario 2.671 2.0736 2.167
Error relativo medio ( %) 15 12 14
Tabla 4.7: Resumen de los errores de la prediccin.
La tabla 4.8 muestra los errores obtenidos de la aplicacin del mtodo ba-
sado en los vecinos ms cercanos y la red neuronal desarrollada a la prediccin
de los precios de la energa en los meses de septiembre y octubre del ao 2001.
Como se puede observar, los resultados muestran un mejor comportamiento
del mtodo propuesto frente a la red neuronal, ya que los errores cometidos en
101
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
la prediccin son de un 7.8 % mientras que con la red neuronal los errores son
de un 14 %.
Vecinos Red Neuronal
Septiembre Octubre Septiembre Octubre
Error Relativo Medio ( %) 6 9.6 14.75 13.75
Error Absoluto Medio 0.25 0.38 0.60 0.56
Mximo error diario ( %) 18 18.6 20.73 31.18
Mximo error horario ( %) 66.02 88.08 50.21 64.92
Mnimo error diario ( %) 2.07 3.97 5.33 4.28
Mnimo error horario ( %) 0.03 0.0 0.01 0.00
Tabla 4.8: Errores obtenidos con ambos mtodos.
4.7. Conclusiones
En este Captulo se ha presentado un algoritmo basado en tcnicas de
vecinos para la prediccin de la serie temporal formada por los precios de la
energa elctrica en el nuevo mercado elctrico espaol.
Se han obtenido cuatro modelos de prediccin, dependiendo del tipo de
prediccin realizada y de la distancia utilizada para calcular los vecinos. Los
dos primeros modelos se han obtenido con una prediccin directa y los dos
ltimos modelos con una prediccin iterada: en el primer modelo se ha usado
la distancia Eucldea, el nmero de ejemplos usados en la prediccin son 4
y hay que buscar los vecinos de los 12 das anteriores al da que se quiere
predecir para estimar los valores de la prediccin; en el segundo modelo se ha
usado la distancia Manhattan, el nmero ptimo de ejemplos obtenido ha sido
5 y hay que buscar los vecinos de los 5 das anteriores; en el tercer modelo
se ha usado la distancia Eucldea, el nmero ptimo de ejemplos obtenido ha
sido 5 y hay que buscar los vecinos de las 24 horas anteriores a la hora que se
quiere predecir; nalmente el cuarto modelo se ha obtenido usando la distancia
Manhattan, el nmero ptimo de ejemplos para realizar la prediccin ha sido
7 y el nmero de horas anteriores que hay que usar para buscar los vecinos ha
sido 24 al igual que el tercer modelo.
Se han mostrado los resultados obtenidos de la aplicacin del algoritmo ba-
sado en los vecinos usando los cuatro modelos anteriores. Con el primer modelo
se ha obtenido un 7.8 % de error relativo medio en los meses de septiembre y
octubre, con el segundo modelo un 9.25 %, con el tercer modelo un 9.15 % y
con el cuarto un 9.19 %.
102
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
Los resultados obtenidos con el primer modelo han sido comparados con
los obtenidos de la aplicacin de una red neuronal a la prediccin de los precios
de la energa. stos muestran un mejor comportamiento del mtodo propuesto
frente a la red neuronal, ya que los errores cometidos en la prediccin son de
un 7.8 % mientras que con la red neuronal los errores son de un 14 %.
103
Captulo 4
Aplicacin a los Precios de la
Energa en el Mercado Elctrico
104
Captulo 5
Aplicacin a la Demanda de
Energa Elctrica.
En este captulo se aplica el mtodo basado en los vecinos ms cercanos
a la prediccin de otra serie temporal real: la demanda de energa elctrica.
En primer lugar, se analiza el comportamiento de la serie mediante algunas
herramientas de visualizacin. En segundo lugar, se obtienen los parmetros
que determinan el modelo y se realiza una prediccin sobre un conjunto test. En
base a los resultados obtenidos se hace una breve comparacin tanto cualitativa
como cuantitativa entre los precios de la energa, serie temporal analizada en
el captulo anterior, y la demanda. Finalmente, los resultados obtenidos de la
aplicacin del mtodo propuesto en esta tesis son comparados con los obtenidos
de la aplicacin de un rbol de regresin generado con el algoritmo M5.
5.1. Demanda. Programacin Horaria de Cen-
trales
La prediccin de la demanda de energa elctrica es muy importante para
lograr una operacin segura y econmica de los sistemas de energa. En el cor-
to, medio y largo plazo, la planicacin de la produccin de energa elctrica
abarca un conjunto de problemas de optimizacin interrelacionados entre ellos,
los cuales requieren una prediccin de la demanda. La planicacin de la pro-
duccin de energa elctrica en el corto plazo es lo que se conoce con el nombre
de Programacin Horaria de Centrales, problema cuya resolucin se presenta
en la segunda parte de esta tesis. De esta manera, la aproximacin de las tc-
nicas de prediccin son importantes para las compaas elctricas que intentan
reducir la incertidumbre de la demanda para obtener una programacin de la
105
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
produccin de energa ptima y realista [120].
Actualmente, los mtodos de prediccin para la estimacin de la demanda
se pueden clasicar en dos grandes grupos: los mtodos estadsticos clsicos
[95, 93] y las tcnicas de aprendizaje automtico (Machine Learning).
Los mtodos estadsticos clsicos consisten en estimar la demanda actual a
partir de los valores pasados de la demanda. Las relaciones entre la demanda
y otros factores importantes, como por ejemplo la temperatura, se usan para
determinar un modelo que represente el comportamiento y la evolucin tem-
poral de la serie, en este caso la demanda de energa elctrica. La principal
ventaja de estos mtodos es su simplicidad, sin embargo no es fcil identicar
modelos aproximados y realistas usando estos mtodos ya que las relaciones
que existen entre la demanda y los factores que inuyen en ella no son lineales.
En los ltimos aos, las tcnicas de Machine Learning tales como las Re-
des Neuronales Articiales (RNA) [4, 105, 67] se han aplicado al problema de
la prediccin de la demanda de energa elctrica en el corto plazo (normal-
mente 24 horas). Las RNA se entrenan para aprender las relaciones que hay
entre las variables de entrada (principalmente valores pasados de la demanda
y valores actuales de la temperatura) y los patrones histricos de la demanda.
La principal desventaja de las RNA es el procedimiento de aprendizaje que
necesitan.
Recientemente, las tcnicas de clasicacin basadas en los k vecinos ms
cercanos (kNN) se han aplicado con xito en distintas reas, desde diagnosis
mdica hasta sistemas expertos, en teora de juegos o prediccin de series
temporales. Estas tcnicas se han aplicado al problema de la prediccin de los
precios de la energa en el mercado elctrico espaol [124, 121] dando lugar a
resultados competitivos con los resultados obtenidos de la aplicacin de otras
tcnicas, pero en la literatura actual no se han encontrado aplicaciones de estas
tcnicas para obtener una prediccin de la demanda de energa elctrica para
el da siguiente.
Para ilustrar de una manera visual el comportamiento, propiedades y evo-
lucin de la serie temporal formada por la demanda de energa se han elegido
los meses comprendidos entre enero del ao 2000 y mayo del ao 2001. Los
nes de semana y das festivos no son incluidos debido a que presentan un
comportamiento distinto a los das laborables.
La gura 5.1 muestra el valor medio horario de la demanda de energa para
los das laborables de marzo del ao 2001. La desviacin estndar media es
aproximadamente un 4.5 % del valor medio frente al 20 % o 40 % que presentaba
la serie temporal formada por los precios.
106
Aplicacin a la Demanda de Energa Elctrica.
16000
17000
18000
19000
20000
21000
22000
23000
24000
25000
1 3 5 7 9 11 13 15 17 19 21 23
Horas
D
e
m
a
n
d
a
(
M
W
)
Media
Media + s. d.
Media - s. d.
Figura 5.1: Media horaria de la demanda.
En la gura 5.2 se muestran los histogramas de la demanda en el ao 2000
y 2001 para comparar el comportamiento de estos dos aos. Se puede observar
que tanto la distribucin del ao 2000 como la del ao 2001 son parecidas en
cuanto a su forma, salvo que en el ao 2001 la demanda fue ms alta, hecho
frecuente en los ltimos aos donde la demanda suele tener un crecimiento
anual de un 2 %. Debido a la anloga distribucin de los aos 2000 y 2001 se
pueden usar los datos de estos dos aos para obtener el modelo de prediccin,
lo cual era inviable en el caso de los precios.
Demanda (MW)
26500 23000 19500 16000 12500
H
o
r
a
s
500
400
300
200
100
0
Demanda (MW)
26500 23000 19500 16000 12500
H
o
r
a
s
500
400
300
200
100
0
Figura 5.2: Histograma de la demanda del ao 2000 y 2001.
107
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
La gura 5.3 muestra el coeciente de correlacin entre la demanda de
energa en una hora y la demanda correspondiente a las veinticuatro horas
anteriores. Como se puede ver, las horas pasadas ms inuyentes en la hora
actual son justo la hora uno y la veinticuatro, que coinciden con la hora anterior
y con la misma hora que la actual pero del da anterior, respectivamente.
-0.3
-0.2
-0.1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
1 3 5 7 9 11 13 15 17 19 21 23
Nmero de horas anteriores
C
o
e
f
i
c
i
e
n
t
e
d
e
C
o
r
r
e
l
a
c
i
n
Figura 5.3: Coeciente de Correlacin.
Una vez ilustradas de forma visual las principales caractersticas y el com-
portamiento de la demanda de energa se resolver el problema de la prediccin
mediante la aplicacin del mtodo expuesto en el Captulo 3. Tanto el modelo
como los resultados se obtendrn con un tipo de prediccin directa ya que
como se ha visto anteriormente la prediccin iterada muestra una peor aproxi-
macin debido a la acumulacin de errores en las ltimas horas del horizonte
de prediccin.
5.2. Descripcin del problema
El problema de la prediccin de la demanda de energa elctrica en el corto
plazo consiste en predecir la demanda de energa para las 24 horas del da
siguiente.
108
Aplicacin a la Demanda de Energa Elctrica.
5.3. Obtencin del modelo
El algoritmo descrito en la gura 4.7 del captulo anterior ha sido aplicado
a la base de datos formada por la demanda de energa [125, 126], tomando
como conjunto de entrenamiento los das laborables comprendidos entre enero
del ao 2000 y mayo del ao 2001. El nmero mximo de das anteriores (par-
metro num_dias_maximo), usado para el clculo de los vecinos ms cercanos
que son falsos, ha sido igual a 25, lo cual corresponde aproximadamente con
el nmero de das laborables de un mes completo. El parmetro R
max
, que re-
presenta el umbral a partir del cual un punto considerado vecino ms cercano
de otro punto va a ser un vecino falso, ha sido elegido igual a 1.
Para el clculo de los vecinos ms cercanos se han elegido dos distancias, la
distancia Eucldea y la distancia Manhattan, para establecer una comparacin
entre los resultados obtenidos usando ambas en lo que respecta a la calidad
del modelo obtenido, una vez determinados los dos parmetros principales: la
longitud de la ventana y el nmero de vecinos.
La tabla 5.1 presenta el porcentaje obtenido de vecinos cercanos que son
falsos cuando stos han sido calculados con dos distancias, la distancia Eucldea
y la distancia Manhattan. Como se puede observar el nmero de vecinos falsos
tiende a cero cuando el nmero de das pasados que forman la longitud de la
ventana aumenta. La longitud ptima de la ventana deslizante es de 7 das
cuando se calculan los vecinos con la distancia Manhattan, mientras que con
la distancia Eucldea es necesario buscar los vecinos ms cercanos de los 15
das anteriores al que se quiere predecir para que el nmero de vecinos falsos
sea sucientemente pequeo.
La gura 5.4 muestra cmo el porcentaje de vecinos ms cercanos falsos
disminuye cuando el nmero de das anteriores usados para formar la ventana
aumenta, tanto para la distancia Eucldea como la distancia Manhattan.
Una vez determinada la longitud de la ventana deslizante hay que determi-
nar el nmero de vecinos que hacen que el error de la prediccin sea mnimo.
El algoritmo descrito en la gura 4.9 del captulo anterior ha sido aplicado
a la base de datos formada por la demanda de energa, tomando como conjunto
de entrenamiento los das laborables comprendidos entre enero del ao 2000
y mayo del ao 2001. La longitud de la ventana ha sido de 7 das cuando se
ha usado la distancia Manhattan y de 15 das cuando se ha usado la distancia
Eucldea para el clculo de los k vecinos ms cercanos. El nmero mximo de
vecinos (parmetro num_vecinos_max) ha sido igual a 20.
109
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
Vecinos Cercanos Falsos ( %)
Distancia
Nmero de das Eucldea Manhattan
anteriores
1 84.5902 84.918
2 57.377 50.4918
3 43.6066 21.3115
4 23.9344 7.2131
5 25.9016 3.2787
6 21.6393 1.6393
7 16.0656 0.3279
8 14.7541 0
9 6.5574 0
10 7.8689 0
11 5.9016 0
12 4.2623 0
13 3.9344 0
14 2.9508 0
15 1.6393 0
16 1.6393 0
17 0.6557 0
18 0.3279 0
19 0.6557 0
20 0.6557 0
21 0.3279 0
22 0 0
23 0 0
24 0 0
25 0 0
Tabla 5.1: Porcentaje de vecinos falsos segn distancias.
110
Aplicacin a la Demanda de Energa Elctrica.
0
10
20
30
40
50
60
70
80
90
100
1 3 5 7 9 11 13 15 17 19 21 23 25
Nmero de das anteriores
N
m
e
r
o
d
e
v
e
c
i
n
o
s
f
a
l
s
o
s
(
%
)
Distancia Eucldea
Distancia Manhattan
Figura 5.4: Nmero de vecinos cercanos falsos.
La gura 5.5 presenta la inuencia del nmero de vecinos sobre los erro-
res relativos y absolutos medios obtenidos en la prediccin de la demanda de
energa para el conjunto de entrenamiento considerado, siendo la distancia pa-
ra evaluar la similitud entre la demanda de los 7 das anteriores y los datos
histricos, la distancia Manhattan.
Anlogamente a la gura anterior, la gura 5.6 presenta la inuencia del
nmero de vecinos sobre los errores relativos y absolutos medios obtenidos en la
prediccin de la demanda de energa para el mismo conjunto de entrenamiento,
habiendo usado para el clculo de los vecinos la distancia Eucldea.
Como resultado se han obtenido los modelos siguientes:
Con la distancia Eucldea, se han obtenido mediante el mtodo de los
falsos vecinos ms cercanos los siguientes patrones:
P
1,1
P
1,24
P
15,1
P
15,24
P
16,1
P
16,24
P
2,1
P
2,24
P
16,1
P
16,24
P
17,1
P
17,24
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(5.1)
y el nmero de ejemplos cercanos que se usarn en la prediccin son
cuatro.
111
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
2.9
3
3.1
3.2
3.3
3.4
3.5
3.6
3.7
1 3 5 7 9 11 13 15 17 19
Nmero de Vecinos
E
r
r
o
r
R
e
l
a
t
i
v
o
M
e
d
i
o
(
%
)
580
600
620
640
660
680
700
720
E
r
r
o
r
A
b
s
o
l
u
t
o
M
e
d
i
o
(
M
W
)
Error Relativo Medio (%)
Error Absoluto Medio (MW)
Figura 5.5: Nmero ptimo de vecinos usando la distancia Manhattan.
2.9
3
3.1
3.2
3.3
3.4
3.5
3.6
3.7
1 3 5 7 9 11 13 15 17 19
Nmero de Vecinos
E
r
r
o
r
R
e
l
a
t
i
v
o
M
e
d
i
o
(
%
)
580
600
620
640
660
680
700
720
E
r
r
o
r
A
b
s
o
l
u
t
o
M
e
d
i
o
(
M
W
)
Error Relativo Medio (%)
Error Absoluto Medio (MW)
Figura 5.6: Nmero ptimo de vecinos usando la distancia Eucldea.
112
Aplicacin a la Demanda de Energa Elctrica.
Con la distancia Manhattan, se han obtenido mediante el mtodo de los
falsos vecinos ms cercanos los siguientes patrones:
P
1,1
P
1,24
P
7,1
P
7,24
P
8,1
P
8,24
P
2,1
P
2,24
P
8,1
P
8,24
P
9,1
P
9,24
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
(5.2)
y el nmero de ejemplos cercanos que se usarn en la prediccin son siete.
En ambos casos, la ventana se va desplazando veinticuatro atributos cada vez
que se predice la demanda de energa para las veinticuatro horas de un da.
5.4. Prediccin. Resultados
En esta seccin los resultados se obtendrn con un tipo de prediccin di-
recta ya que como se ha visto anteriormente la prediccin iterada muestra una
peor aproximacin debido a la acumulacin de errores en las ltimas horas del
horizonte de prediccin.
El algoritmo descrito en la gura 4.17 del captulo anterior se ha aplicado a
la serie temporal formada por la demanda para obtener la prediccin de los das
laborables comprendidos entre junio y noviembre del ao 2001. El conjunto de
datos empleado para la obtencin y validacin del modelo de prediccin han
sido los das comprendidos entre enero del ao 2000 y mayo del ao 2001.
Aproximadamente, las dos terceras partes de los datos han sido elegidas como
conjunto de entrenamiento correspondiendo a 17 meses y una tercera parte
como conjunto de test correspondiendo a 6 meses. Aunque el conjunto de test
no es un conjunto de test en el sentido clsico, ya que cada vez que se predice
un da del conjunto de test este da es incluido en la base de datos para predecir
de nuevo el siguiente da del conjunto de test.
La tabla 5.2 muestra los valores medios y la desviacin estndar de la
demanda correspondiente a los meses comprendidos entre junio y noviembre
del ao 2001.
Junio Julio Agosto
Demanda real 20453.267 21624.967 20598.948
Desviacin Estndar 747.121 (3.6 %) 576.181 (2.6 %) 816.604 (3.9 %)
Septiembre Octubre Noviembre
Demanda real 17281.499 20404.260 21998.205
Desviacin Estndar 666.605 (9.1 %) 587.017 (2.8 %) 1459.911 (6.6 %)
Tabla 5.2: Media y desviacin estndar del conjunto test.
113
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
Las guras 5.7 y 5.8 presentan la media horaria de la prediccin obtenida
de la demanda y la media horaria de la demanda real para los das laborables
del conjunto test seleccionado, tanto si se usa la distancia Eucldea como la
distancia Manhattan, siendo el error medio de la prediccin 2.9 % y 2.3 %,
respectivamente.
16000
17000
18000
19000
20000
21000
22000
23000
24000
25000
1 3 5 7 9 11 13 15 17 19 21 23
Horas
D
e
m
a
n
d
a
(
M
W
)
Prediccin
Media horaria
Figura 5.7: Media horaria de la prediccin usando la distancia Eucldea.
16000
17000
18000
19000
20000
21000
22000
23000
24000
25000
1 3 5 7 9 11 13 15 17 19 21 23
Horas
D
e
m
a
n
d
a
(
M
W
)
Prediccin
Media horaria
Figura 5.8: Media horaria de la prediccin usando la distancia Manhattan.
114
Aplicacin a la Demanda de Energa Elctrica.
En lo que sigue, slo se mostrarn los resultados obtenidos de la prediccin
sobre el conjunto test cuando los vecinos cercanos se han calculado con la
distancia Manhattan, debido a la mejor aproximacin que se obtiene con el
uso de esta mtrica.
La gura 5.9 presenta la media diaria de la prediccin obtenida de la deman-
da y la media diaria de la demanda real para los das laborables del conjunto
test seleccionado.
18000
19000
20000
21000
22000
23000
24000
1 12 23 34 45 56 67 78 89 100 111 122
Das
D
e
m
a
n
d
a
(
M
W
)
Prediccin diaria
Demanda diaria
Figura 5.9: Media diaria de la prediccin.
La gura 5.10 presenta la media del error absoluto horario cometido en la
prediccin de la demanda para las estaciones de verano y otoo. En esta gura
se puede observar un buen comportamiento del mtodo de los vecinos ms cer-
canos en las horas punta. Es importante obtener una buena prediccin durante
las horas punta, aquellas horas en las que el consumo de energa elctrica es
alto (desde las 10 horas hasta las 14 horas y desde las 18 horas hasta las 22
horas), ya que para satisfacer la punta de demanda hay que tener prepara-
das centrales adicionales (normalmente de coste elevado), por lo que cualquier
error en la prediccin conlleva un sobrecoste que puede ser muy importante.
115
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
0
200
400
600
800
1 3 5 7 9 11 13 15 17 19 21 23
Horas
E
r
r
o
r
A
b
s
o
l
u
t
o
(
M
W
)
Verano
Otoo
Figura 5.10: Media horaria del error absoluto.
Las guras 5.11 y 5.12 presentan la prediccin de la demanda de las dos
semanas que conducen a los mximos y mnimos errores semanales, y la de-
manda real para esas dos semanas. La semana que da lugar al mximo error
corresponde a los das comprendidos entre el lunes 25 de junio y el viernes
29 de junio. La semana que da lugar al mnimo error corresponde a los das
comprendidos entre el lunes 16 de julio y el viernes 20 de julio.
12000
14000
16000
18000
20000
22000
24000
26000
28000
1 20 39 58 77 96 115
Horas
D
e
m
a
n
d
a
(
M
W
)
Prediccin
Demanda real
Figura 5.11: Mejor prediccin semanal.
116
Aplicacin a la Demanda de Energa Elctrica.
12000
14000
16000
18000
20000
22000
24000
26000
28000
1 20 39 58 77 96 115
Horas
D
e
m
a
n
d
a
(
M
W
)
Prediccin
Demanda real
Figura 5.12: Peor prediccin semanal.
La tabla 5.3 muestra los errores diarios de los das laborables de las semanas
en las que se obtuvo la mejor y la peor prediccin.
Errores diarios ( %) Error semanal ( %)
16 de julio-20 de julio 0.8 0.6 0.8 1.7 1.3 1.05
25 de junio-29 de junio 2.1 7.2 5.9 2.6 1.3 3.8
Tabla 5.3: Errores diarios de la mejor y la peor prediccin semanal.
Las guras 5.13 y 5.14 presentan la prediccin de la demanda de los dos
das que conducen a los mximos y mnimos errores diarios, junto a la demanda
real y el error relativo horario para esos dos das. Los das con el mximo y
mnimo error diario corresponden al lunes 6 de agosto del ao 2001 y al jueves
20 de septiembre del ao 2001, respectivamente. Se puede observar que el da
de mayor error corresponde al primer lunes del mes de agosto, que es el da
que comienzan las vacaciones de verano para la mayora de los espaoles.
117
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
1 3 5 7 9 11 13 15 17 19 21 23
Horas
E
r
r
o
r
R
e
l
a
t
i
v
o
15000
18000
21000
24000
D
e
m
a
n
d
a
(
M
W
)
Error
Demanda real
Prediccin
Figura 5.13: Mejor prediccin diaria.
0
0.02
0.04
0.06
0.08
0.1
0.12
0.14
0.16
1 3 5 7 9 11 13 15 17 19 21 23
Horas
E
r
r
o
r
R
e
l
a
t
i
v
o
15000
18000
21000
24000
D
e
m
a
n
d
a
(
M
W
)
Error
Demanda real
Prediccin
Figura 5.14: Peor prediccin diaria.
Estos resultados se resumen en la tabla 5.4 que se muestra a continuacin.
118
Aplicacin a la Demanda de Energa Elctrica.
Distancia Eucldea Distancia Manhattan
Verano Otoo Verano Otoo
Error Relativo Medio ( %) 2.99 3.729 2.356 2.244
Error Absoluto Medio 627.53 572.098 493.42 456.31
Mximo error diario ( %) 8.246 8.038 7.88 6.27
Mximo error horario ( %) 13.5 18.6 14.8 17.6
Mnimo error diario ( %) 0.499 0.657 0.6 0.484
Mnimo error horario ( %) 0.0 0.0 0.0 0.0
Tabla 5.4: Errores segn distancias.
Como se puede observar en la tabla anterior, cuando se usa la distancia
Manhattan para la bsqueda de los vecinos ms cercanos se obtiene una mejor
aproximacin en la prediccin de la demanda para el conjunto de test seleccio-
nado que cuando se usa la distancia Eucldea.
5.5. Estudio Cualitativo y Comparativo de la
Demanda y los Precios de la Energa en el
Mercado Elctrico Espaol.
En esta seccin se comparan las dos series temporales analizadas ante-
riormente: los precios y la demanda de energa. De esta forma, se justica la
diferencia cuantitativa notable existente entre el error cometido en la predic-
cin de ambas series temporales. Recurdese que el error medio cometido en la
prediccin de los precios ha sido un 7.8 % frente a un error de 2.3 % obtenido
en la prediccin de la demanda.
La gura 5.15 muestra las relaciones entre los precios de una hora y los
precios de la hora siguiente. En la gura se puede distinguir claramente una
lnea horizontal y vertical las cuales estn indicadas con una echa, que re-
presentan un rango de precios comprendidos entre 1 cent/kWh y 3 cent/kWh
cuyo precio en la hora siguiente fue el mismo (lnea horizontal) y un mismo
precio cuyo precio en la hora siguiente oscila en todo un rango comprendido
entre 1 cent/kWh y 4 cent/kWh (lnea vertical). Se puede observar cmo dado
un precio hay veces que en la hora siguiente el precio aumenta (precios por
encima de la diagonal) y otras veces el precio disminuye (precios por debajo
de la diagonal). Por ltimo se ha indicado con un crculo aquellos precios que
claramente son inusuales y que impiden hacer una buena prediccin.
En contraste a la gura anterior, la gura 5.16 presenta las relaciones entre
la demanda de una hora y la demanda de la hora siguiente. Como se puede
119
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
observar, la demanda en una hora determinada t tiene una relacin casi lineal
con la demanda de energa que hubo en la hora t 1, sin embargo los precios
en una hora concreta no presentan relacin alguna con los precios en la hora
anterior.
0
1
2
3
4
5
6
0 1 2 3 4 5 6
Precios (t-1)
P
r
e
c
i
o
s
(
t
)
Figura 5.15: Relaciones entre los precios de horas consecutivas.
15000
18000
21000
24000
27000
30000
15000 18000 21000 24000 27000 30000
Demanda (t-1)
D
e
m
a
n
d
a
(
t
)
Figura 5.16: Relaciones entre la demanda de horas consecutivas.
120
Aplicacin a la Demanda de Energa Elctrica.
A continuacin en las guras 5.17 y 5.18 se muestran las relaciones entre
los precios y la demanda de dos horas consecutivas concretas, en este caso
las 7 horas y las 8 horas. Como se puede observar, la demanda presenta una
tendencia casi lineal mientras que los precios presentan una mayor dispersin
sin mostrar relacin alguna entre estas dos horas.
0
1
2
3
4
5
6
0 1 2 3 4 5
Precios en la hora 7
P
r
e
c
i
o
s
e
n
l
a
h
o
r
a
8
Figura 5.17: Relacin entre los precios de la hora 7 y la hora 8.
15000
16000
17000
18000
19000
20000
21000
22000
23000
15000 16000 17000 18000 19000 20000 21000
Demanda en la hora 7
D
e
m
a
n
d
a
e
n
l
a
h
o
r
a
8
Figura 5.18: Relacin entre la demanda de la hora 7 y la hora 8.
121
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
Las guras 5.19 y 5.20 presentan la relacin existente entre los precios y
la demanda de la misma hora en das consecutivos, respectivamente. Como se
puede notar los precios presentan una gran dispersin no pudindose obtener
buenos resultados si un mtodo de regresin estndar, que establezca una re-
lacin entre el precio de una hora y el precio que hubo en esa misma hora el
da anterior, es usado para la estimacin de una prediccin. Sin embargo, aun-
que la demanda presenta una menor dispersin tampoco se obtendran buenos
resultados si un mtodo de regresin estndar es usado para la estimacin de
una prediccin sobretodo cuando la demanda de energa es baja.
0
1
2
3
4
5
6
7
0 1 2 3 4 5 6 7
Precios (d-1)
P
r
e
c
i
o
s
(
d
)
Figura 5.19: Relacin entre los precios de das consecutivos.
14000
16000
18000
20000
22000
24000
26000
14000 16000 18000 20000 22000 24000 26000
Demanda (d-1)
D
e
m
a
n
d
a
(
d
)
Figura 5.20: Relacin entre la demanda de das consecutivos.
122
Aplicacin a la Demanda de Energa Elctrica.
En las guras 5.21 y 5.22 se muestra el comportamiento de la hora 1 en das
consecutivos para los precios y la demanda, respectivamente. Obsrvese que
los precios de la hora 1 oscilan aproximadamente desde 1.5 cent/kWh hasta
4.5 cent/kWh y donde presenta un comportamiento ms catico es cuando los
precios del da anterior en esa misma hora son superiores a 3 cent/kWh.
0
0.5
1
1.5
2
2.5
3
3.5
4
4.5
5
0 1 2 3 4 5
Precios del da d-1 hora 1
P
r
e
c
i
o
s
d
e
l
d
a
d
h
o
r
a
1
Figura 5.21: Relacin entre los precios de la hora 1 en das consecutivos.
15000
17000
19000
21000
23000
25000
15000 17000 19000 21000 23000 25000
Demanda del da d-1 hora 1
D
e
m
a
n
d
a
d
e
l
d
a
d
h
o
r
a
1
Figura 5.22: Relacin entre la demanda de la hora 1 en das consecutivos.
123
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
Debido a las irregularidades de la serie temporal formada por los precios se
puede pensar que se trata de una serie temporal catica de baja dimensiona-
lidad. Un sistema catico presenta una divergencia de las trayectorias vecinas,
aunque stas se encuentran en una regin acotada que se conoce con el nombre
de atractor. Las trayectorias sufren un proceso de estiramiento y doblado en
el atractor lo que ocasiona la separacin de una trayectoria con respecto a las
temporalmente vecinas. Recientemente la Teora del Caos [96] ha identicado
numerosos atractores extraos en el comportamiento de muchos sistemas en
distintas reas como meteorologa, biologa, economa... Para obtener las tra-
yectorias y visualizar el tipo de atractor subyacente a la serie temporal basta
con representar los pares (X
t
, X
t1
) para todos los valores de la serie.
Las guras 5.23 y 5.24 presentan las cuencas de atraccin de las trayectorias
para los precios y la demanda. Se puede observar que la divergencia de las
trayectorias es mayor cuando se trata de la serie temporal formada por los
precios, lo cual de nuevo conrma la diferencia que hay entre el error cometido
en la prediccin de ambas series.
0
1
2
3
4
5
6
0 1 2 3 4 5 6
Figura 5.23: Atractor de los precios.
124
Aplicacin a la Demanda de Energa Elctrica.
15000
17000
19000
21000
23000
25000
27000
29000
16000 18000 20000 22000 24000 26000 28000
Figura 5.24: Atractor de la demanda.
La distancia que hay en el instante t entre dos trayectorias que inicialmente
eran cercanas viene dada por un crecimiento exponencial que depende del
tiempo que haya transcurrido, es decir, si x
0
e y
0
son puntos cercanos en el
pasado se observa la siguiente relacin en el futuro:
|y
t
x
t
| < e
t
|y
0
x
0
| (5.3)
Al conjunto de que cumplen (5.3) se le llaman exponentes de Lyapunov [29].
Estos exponentes proporcionan una medida de la divergencia que muestran
en un futuro las trayectorias que han sido vecinas en el pasado. Desde la
ecuacin (5.3) se puede concluir que en presencia de exponentes de Lyapunov
estrictamente positivos las trayectorias divergen exponencialmente, por tanto
el nmero de exponentes de Lyapunov positivos es una aproximacin de la
predecibilidad de la serie temporal.
La tabla 5.5 muestra los exponentes de Lyapunov para la serie temporal
formada por los precios de la energa y para la serie temporal formada por la
demanda de energa elctrica. Como se puede observar los precios presentan
dos exponentes positivos ms que la demanda y unos exponentes positivos de
mayor magnitud que los exponentes positivos de la demanda, lo cual vuelve
a justicar la diferencia que hay entre el error cometido en la prediccin de
ambas series.
125
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
Exponentes de Lyapunov
Demanda Precios
0.0328 0.0473
0.0217 0.0300
0.0146 0.0264
0.0102 0.0209
0.0069 0.0130
0.0016 0.0083
-0.0011 0.0029
-0.0041 0.0003
-0.0060 -0.0024
-0.0087 -0.0096
-0.0139 -0.0106
-0.0164 -0.0156
-0.0201 -0.0178
-0.0244 -0.0257
-0.0289 -0.0286
-0.0368 -0.0365
-0.0421 -0.0447
-0.0499 -0.0539
-0.0613 -0.0633
-0.0791 -0.0764
-0.0977 -0.1073
-0.1460 -0.1444
-0.2395 -0.2460
-0.6129 -0.5853
Tabla 5.5: Exponentes de Lyapunov.
5.6. Comparacin con rboles de Regresin: Al-
goritmo M5
En esta seccin se describe brevemente el algoritmo de aprendizaje M5
usado en la presente tesis para establecer una comparacin entre los resultados
obtenidos de la aplicacin de este algoritmo y el algoritmo propuesto basado
en la tcnica de los vecinos ms cercanos para la prediccin de la demanda del
da siguiente.
En Machine Learning, es importante obtener resultados que sean fcilmente
126
Aplicacin a la Demanda de Energa Elctrica.
interpretables. Los rboles de decisin basados en reglas del tipo Si-Entonces
son uno de los lenguajes de descripcin ms populares en Machine Learning.
Bsicamente, el M5 construye un rbol basado en modelos lineales a trozos.
Los rboles de regresin son rboles de decisin en cuyas hojas se obtiene un
modelo lineal. As, este algoritmo obtiene un conjunto ordenado de reglas Si-
Entonces para la prediccin de series temporales que producen modelos los
cuales revelan alguna informacin sobre la estructura de los datos. En general,
el aprendizaje de un algoritmo basado en reglas consta de dos etapas:
Se parte de un conjunto de reglas iniciales
Las reglas son mejoradas mediante un algoritmo de optimizacin global
El algoritmo M5 construye un rbol dividiendo los datos basndose en los
valores de los atributos predictivos. Una vez que el rbol ha sido construido,
el mtodo computa un modelo lineal para cada nodo. Entonces las hojas del
rbol son podadas mientras que el error disminuya. El error para cada nodo
es la media del valor absoluto de la diferencia entre el valor predicho y el valor
actual de cada ejemplo del conjunto de entrenamiento que alcanza dicho nodo.
Este error es ponderado con un peso que representa el nmero de ejemplos
que alcanza ese nodo. Este proceso es repetido hasta que todos los ejemplos
son cubiertos por una o ms reglas. Este algoritmo est implementado en la
librera WEKA [15].
As el algoritmo se puede resumir en las siguientes etapas:
Transformacin de atributos no numricos a variables binarias
Tratamiento de valores perdidos
Construccin del rbol
Cortes
Poda
Suavizado
5.6.1. Transformacin de atributos no numricos
Antes de construir el rbol todos los atributos que no son numricos se
transforman en variables binarias las cuales son tratadas como atributos nu-
mricos. Esta transformacin se hace mediante una tcnica desarrollada por
Breiman en [14] donde se demuestra que el mejor corte en un nodo para una
variable que tiene k posibles valores es una de las k 1 posibles posiciones
127
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
resultantes una vez ordenados los k valores mediante algn criterio de orde-
nacin. Para cada atributo no numrico se calcula la media de las veces que
aparece cada etiqueta posible para este atributo a partir de un conjunto de en-
trenamiento, entonces las etiquetas se ordenan de menor a mayor segn estas
medias. Una vez ordenadas las etiquetas se denen la variable binaria i-sima
como 0 si el valor de la etiqueta est entre los i primeros elementos y 1 en caso
contrario. De esta manera, todos los cortes envuelven atributos numricos o
variables binarias tratadas como atributos numricos.
Supngase un atributo no numrico, llamado color, que tiene tres posibles
valores: azul, rojo y verde y que a partir de un conjunto de entrenamiento
formado por 80 ejemplos se tiene que la etiqueta rojo aparece 12 veces, la
etiqueta verde aparece 40 veces y la etiqueta azul aparece 28 veces. Entonces
este atributo se puede transformar en dos variables binarias b1 y b2 cuyos
valores se muestran a continuacin en la tabla 5.6.
rojo azul verde
b1 0 1 1
b2 0 0 1
Tabla 5.6: Transformacin de atributos no numricos en variables binarias.
La ordenacin de las posibles etiquetas para un atributo no numrico se
debe hacer en cada nodo, sin embargo hay un inevitable incremento de ruido
debido a que el nmero de ejemplos que alcanzan los nodos situados en la
parte ms baja del rbol es pequeo. Por tanto no hay mucha prdida si esta
ordenacin se hace slo una vez al principio antes de comenzar a construir el
rbol.
En la aplicacin de este algoritmo a la prediccin de la demanda de energa
elctrica esta etapa no es necesaria puesto que todos los atributos son num-
ricos.
5.6.2. Valores perdidos
Una vez que un atributo es seleccionado como punto de corte para dividir
los datos en subconjuntos se necesita el valor de ese atributo. Por tanto, es un
problema obvio si el valor del atributo no existe lo cual es bastante comn en
datos reales. Para resolver esto hay una tcnica que consiste bsicamente en la
sustitucin del valor inexistente de este atributo por el valor de otro atributo
que est altamente correlacionado con ste.
128
Aplicacin a la Demanda de Energa Elctrica.
Una heurstica ms simple es usar el valor de la prediccin como valor del
atributo que ha sido elegido para el corte. Sin embargo, esto es slo posible
cuando se trata del conjunto de entrenamiento. En otros casos se puede usar
como valor la media de los valores de ese atributo para todos los ejemplos del
conjunto que alcanzan el nodo.
En la serie temporal formada por la demanda de energa elctrica slo se
encuentra un ejemplo con un atributo sin valor debido al cambio de horario
que se efecta en el mes de marzo.
5.6.3. Cortes
Para determinar qu atributo es el mejor para dividir el conjunto de en-
trenamiento en un nodo determinado se usa la desviacin estndar como una
medida del error en cada nodo. Primero se calcula la reduccin de este error
para cada atributo que se use como punto de corte en el nodo y el atributo
que maximiza esta reduccin es elegido como punto de corte en dicho nodo.
La reduccin del error viene dado por:
SDR = sd(T)
i
|T
i
|
|T|
sd(T
i
) (5.4)
donde T
i
son los conjuntos resultantes de dividir el nodo usando el atributo
elegido, T es el conjunto de entrenamiento, sd() es la desviacin estndar de
un conjunto y | | es la funcin cardinal que devuelve el nmero de elementos
de un conjunto.
El proceso de clculo de los puntos de corte termina cuando las predicciones
de los ejemplos del conjunto de entrenamiento que alcanzan el nodo varan
ligeramente, es decir la desviacin estndar de este subconjunto es menor que
un 5 % de la desviacin estndar del conjunto total o cuando ese nodo es
alcanzado por muy pocos ejemplos (cuatro o cinco).
5.6.4. Suavizado
En una etapa nal se realiza un proceso de regularizacin para compensar
las posibles discontinuidades que haya entre los modelos lineales adyacentes
en las hojas del rbol ya una vez podado, sobretodo para modelos construidos
a partir de un conjunto de entrenamiento con un nmero pequeo de ejem-
plos. Este proceso de suavizado suele mejorar la aproximacin de la prediccin
obtenida mediante modelos basados en rboles.
Para realizar esta regularizacin, se construyen modelos lineales para los
nodos internos al igual que en las hojas mientras se est construyendo el rbol.
129
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
Entonces una vez que el valor de la prediccin para un ejemplo del conjunto
test se ha obtenido con el modelo lineal de la hoja alcanzada ste se ltra
recorriendo el rbol desde la hoja hasta la raz suavizando en cada nodo me-
diante una combinacin de ste y el valor predicho para este ejemplo usando
el modelo lineal del nodo.
5.6.5. Poda
Como se ha descrito anteriormente, para el proceso de suavizado se necesita
un modelo lineal para cada nodo interior del rbol, no slo en las hojas. As,
antes de podar el rbol se calcula un modelo lineal para cada nodo. Este modelo
tiene la forma siguiente:
w
0
+w
1
a
1
+w
2
a
2
+. . . +w
k
a
k
(5.5)
donde a
i
son valores de los atributos y w
i
son los pesos que se calculan mediante
una regresin. Sin embargo en esta regresin slo intervienen los atributos que
aparecen en el subrbol que cuelga del nodo porque los otros atributos que
afectan a la prediccin ya se han tenido en cuenta para recorrer el rbol hasta
alcanzar dicho nodo.
El proceso de poda usa una estimacin del error en cada nodo. El error
para cada nodo es la media del valor absoluto de la diferencia entre el valor
predicho y el valor actual de cada ejemplo del conjunto de entrenamiento que
alcanza dicho nodo. Esta media estima por defecto el error para los ejemplos
del conjunto test puesto que ha sido calculada a partir del conjunto de entrena-
miento, por tanto se multiplica por un factor de peso que depende del nmero
de ejemplos del conjunto de entrenamiento que alcanzan ese nodo y el nmero
de parmetros del modelo lineal obtenido en ese nodo.
Una vez obtenido el modelo lineal para un nodo ste se puede simplicar
eliminando trminos mientras que el error estimado disminuya. Una vez sim-
plicados los modelos lineales de cada nodo el rbol se poda desde las hojas.
Un subrbol es podado siempre que su error sea mayor que el error obtenido
en el nodo que debido a esta poda se convierte en hoja.
5.6.6. Resultados
El algoritmo descrito anteriormente se ha aplicado a la serie temporal for-
mada por la demanda para obtener la prediccin de los das laborables com-
prendidos entre junio y noviembre del ao 2001.
Se ha usado el algoritmo M5 que hay implementado en Java en la li-
brera WEKA. Antes de aplicar este algoritmo se ha aplicado un mtodo de
130
Aplicacin a la Demanda de Energa Elctrica.
seleccin de atributos para determinar que atributos son importantes y ver-
daderamente relevantes para obtener una buena prediccin. Esta seleccin de
atributos no slo debe beneciar a la aproximacin de la prediccin puesto
que se eliminan los atributos que no son inuyentes sino tambin en lo que
respecta al coste computacional. El mtodo de seleccin usado ha sido el algo-
ritmo CFS (Correlation-based Feature Selection) implementado en la WEKA el
cual bsicamente evala como buenos atributos aquellos que tienen una alta
correlacin con el atributo que se quiere predecir pero sin embargo tienen poca
correlacin entre ellos mismos. Una vez aplicado este mtodo se han obtenido
como buenos atributos para predecir la demanda de energa elctrica en una
hora (D
25
) la demanda de energa elctrica en las dos horas anteriores (D
23
,
D
24
) y la quinta hora anterior (D
20
).
La tabla 5.7 presenta el error relativo medio y los mximos y mnimos
errores diarios para el conjunto test seleccionado. 53 y 151 reglas de la variable
dependiente han sido encontradas por el algoritmo M5 con y sin seleccin de
atributos respectivamente, para el problema de la prediccin de la demanda.
Los rboles de regresin junto a los modelos lineales obtenidos en las hojas
de los rboles se muestran en el Apndice A. Como era esperado el algoritmo
M5 genera un rbol ms pequeo y que aproxima mejor cuando se hace una
seleccin de atributos previa. Cuando se usa el rbol de regresin obtenido por
el M5 con seleccin de atributos el error medio es 11 % mientras que cuando
se usa el mtodo basado en los vecinos el error medio es 2.3 %.
Obsrvese que los resultados obtenidos de la aplicacin del mtodo basado
en kNN son mucho mejores que los obtenidos de la aplicacin del algoritmo
M5. Esto es debido a que el algoritmo M5 construye modelos lineales y la serie
temporal formada por la demanda no tiene un comportamiento estrictamente
lineal.
Junio-Noviembre 2001
kNN M5 con seleccin M5 sin seleccin
Mnimo error diario ( %) 0.5 7 7
Mximo error diario ( %) 8.5 16.5 17.2
Error Relativo Medio ( %) 2.3 11 11.4
Tabla 5.7: Comparacin de los errores de la prediccin de la demanda usando
ambos mtodos.
131
Captulo 5 Aplicacin a la Demanda de Energa Elctrica.
5.7. Conclusiones
En este Captulo se ha presentado un algoritmo basado en tcnicas de
vecinos para la prediccin de la serie temporal formada por la demanda de
energa elctrica.
Se han obtenido dos modelos de prediccin, dependiendo de la distancia
utilizada para calcular los vecinos: en el primer modelo se ha usado la distancia
Eucldea, el nmero de ejemplos usados en la prediccin ha sido 4 y hay que
buscar los vecinos de los 15 das anteriores al da que se quiere predecir para
estimar los valores de la prediccin; en el segundo modelo se ha usado la
distancia Manhattan, el nmero ptimo de ejemplos obtenido ha sido 7 y hay
que buscar los vecinos de los 7 das anteriores.
Se han mostrado los resultados obtenidos de la aplicacin del algoritmo
basado en los vecinos usando el segundo modelo y stos han sido comparados
con los obtenidos de la aplicacin de un rbol de regresin obtenido con el
algoritmo M5. Los resultados muestran un mejor comportamiento del mtodo
propuesto, ya que los errores cometidos en la prediccin son aproximadamente
de un 2 % mientras que con el algoritmo M5 los errores son de un 11 %.
Esta gran diferencia en el error de la prediccin obtenido de la aplicacin de
ambos mtodos es debida a que el algoritmo M5 presenta modelos lineales de
prediccin y la serie temporal estudiada en este caso tiene unas dependencias
no lineales que este mtodo es incapaz de aprender. Sin embargo este algoritmo
presenta la ventaja de que obtiene modelos explcitos del comportamiento del
sistema.
Por ltimo se ha realizado un estudio comparativo entre las dos series
analizadas en esta tesis: los precios y la demanda. Los errores de prediccin
obtenidos han sido mucho mayores en el caso de la prediccin de los precios
que en el caso de la prediccin de la demanda. Este hecho ha sido justicado
estableciendo una comparacin cualitativa entre el comportamiento de ambas
series.
132
Parte II
Programacin con Mltiples
Mnimos Locales
133
Captulo 6
Programacin no Lineal no
Convexa
El objeto de este captulo es la resolucin de problemas de optimizacin con
restricciones donde la funcin objetivo f y las restricciones tanto de igualdad,
h, como de desigualdad, g, son no lineales y no convexas. Se supone que f, h
y g son sucientemente regulares. En primer lugar, se describe la formulacin
matemtica de un problema de optimizacin de estas caractersticas cuando
todas las variables son reales y varan de una forma continua, despus se pro-
pone un nuevo mtodo que resuelve el problema de manera eciente, con una
ventaja frente a los mtodos existentes: su habilidad de escapar de un mni-
mo local. Para ilustrar el comportamiento de este nuevo mtodo se presenta
un ejemplo tutorial de una sola variable. En un segundo lugar, se describe la
formulacin matemtica cuando coexisten variables reales y enteras, lo que se
conoce como Programacin no Lineal Entera-Mixta. Se propone un mtodo
de resolucin que consiste bsicamente en relajar el carcter discreto de las
variables y aplicar el mtodo propuesto en el caso anterior. Para ilustrar el
comportamiento del mtodo en el caso mixto-entero se presenta un ejemplo
tutorial de dos variables, una binaria y una real.
6.1. Variables reales
6.1.1. Formulacin del problema
Una gran variedad de problemas basados en casos reales, que aparecen
en campos como la Ingeniera o la Economa, se pueden modelar como un
problema de optimizacin con restricciones.
Un problema de optimizacin con restricciones de igualdad y desigualdad
135
Captulo 6 Programacin no Lineal no Convexa
puede formularse de una forma general como sigue:
Minimizar f(x)
sujeto a h(x) = 0
g(x) 0
(6.1)
donde
x R
n
es un vector de variables independientes de dimensin n.
f : R
n
R es una funcin escalar no lineal, no convexa y dos veces
diferenciable con derivadas continuas. Esta funcin modela la funcin
objetivo deseada.
g : R
n
R
p
es una funcin vectorial no lineal, no convexa y dos ve-
ces diferenciable con derivadas continuas. Esta funcin modela tanto las
restricciones de desigualdad como las restricciones de lmite sobre las
variables.
h : R
n
R
q
es una funcin vectorial no lineal, no convexa y dos veces di-
ferenciable con derivadas continuas. Esta funcin modela las restricciones
de igualdad.
La caracterstica principal de este tipo de problemas de optimizacin es la
existencia de mltiples ptimos locales (mximos y mnimos). En general los
mtodos de optimizacin no lineales, dado un punto inicial, tratan de encontrar
un ptimo local; sin embargo el ptimo local encontrado puede estar muy lejos
del ptimo global.
6.1.2. Mtodo propuesto
En esta seccin se propone un mtodo heurstico, prctico y sencillo para
resolver problemas de optimizacin no lineal no convexa de una manera rpida
y ecaz [106]. Por tanto, no se analizarn propiedades tericas de convergencia
del mtodo, que podrn formar parte de futuras lneas de investigacin, sino
su implementacin y funcionamiento.
El mtodo consiste bsicamente en resolver de manera iterativa una suce-
sin de subproblemas de optimizacin con restricciones. Estos subproblemas
se construyen de tal forma que mediante su resolucin se obtenga una sucesin
de mnimos decrecientes, en un intento de alcanzar el mnimo global. Para
asegurar la obtencin de una sucesin decreciente de mnimos, al problema de
optimizacin (6.1) se le aade la restriccin siguiente:
f(x) C (6.2)
136
Programacin no Lineal no Convexa
donde C es una constante que se inicializa con un valor sucientemente grande
y se va actualizando en cada iteracin de una manera adecuada para que los
mnimos que se van calculando sean decrecientes.
En general, los pasos del algoritmo propuesto son los siguientes:
1) Eleccin de un cota superior inicial, C, sucientemente grande.
2) Clculo de un ptimo local del problema siguiente:
Minimizar f(x)
sujeto a h(x) = 0
g(x) 0
f(x) C
(6.3)
3) Actualizacin de C.
Los pasos 2 a 3 se repiten de manera iterativa hasta que no se pueda encontrar
un nuevo ptimo local mediante el algoritmo usado en el segundo paso, ya sea
por motivos de convergencia o bien por haber alcanzado el ptimo global, lo
que nunca se podr saber.
6.1.2.1. Solucin de los subproblemas
El algoritmo elegido para resolver la secuencia de subproblemas de op-
timizacin (6.3) ha sido un algoritmo Primal-Dual de Punto Interior
[84, 16, 10], por su tratamiento caracterstico de las restricciones de desigualdad
y por los avances recientes obtenidos de la aplicacin de este tipo de mtodos
a problemas de optimizacin no lineal no convexa, tanto en propiedades de
convergencia como en aspectos computacionales de la resolucin de problemas
de gran dimensin [30, 129].
Introduciendo las variables de holgura apropiadas para convertir las res-
tricciones de desigualdad en igualdad, el problema (6.3) se transforma en el
problema siguiente:
Minimizar v
sujeto a h(x) = 0
f(x) v = 0
g(x) z = 0
z +s
1
= 0
v +s
2
C = 0
s
1
, s
2
0
(6.4)
137
Captulo 6 Programacin no Lineal no Convexa
Se han introducido dos variables auxiliares, v y z, para que las restricciones
de mximos y mnimos se apliquen sobre variables del problema, ya que en los
mtodos de Punto Interior la convergencia se controla mediante el error de
dualidad el cual depende de las holguras de las variables del problema sujetas
a lmites.
Para asegurar la positividad de estas variables, s
1
, s
2
, se penaliza la fun-
cin objetivo a travs de trminos logartmicos ponderados por el factor de
penalizacin [80]. De esta manera, el problema de optimizacin resultante es
el subproblema de barrera logartmica siguiente:
Minimizar v ln(s
1
) ln(s
2
)
sujeto a h(x) = 0
f(x) v = 0
g(x) z = 0
z +s
1
= 0
v +s
2
C = 0
(6.5)
Los problemas (6.1) y (6.5) son equivalentes en el sentido de que ambos tienen
las mismas soluciones.
6.1.2.2. Condiciones de optimalidad
Para caracterizar la solucin del problema de barrera logartmica (6.5) se
introduce el Lagrangiano, que viene dado por:
L(x, v, z, s
i
,
j
) = v
2
i=1
ln(s
i
) +
1
h(x) +
2
(f(x) v) +
3
(g(x) z)
+
4
(z +s
1
) +
5
(v +s
2
C) i = 1, 2 j = 1, . . . , 5(6.6)
donde
j
son los Multiplicadores de Lagrange. Las ecuaciones de optimalidad
de primer orden de Karust-Kuhn-Tucker (KKT) son:
F
(x, v, z, s
i
,
j
) =
_
_
H(x,
j
)
h(x)
f(x) v
g(x) z
z +s
1
v +s
2
C
s
1
+
4
s
2
+
5
1
2
+
5
3
+
4
_
_
= 0 (6.7)
138
Programacin no Lineal no Convexa
donde
H(x,
j
) = h(x)
1
+f(x)
2
+g(x)
3
(6.8)
Hay que tener en cuenta que las ecuaciones de optimalidad de primer orden de
KKT (6.7) son una condicin necesaria de mnimo local [72]. Es decir, no todos
los puntos que verican estas ecuaciones son mnimos locales. Para asegurar
que los puntos que verican este sistema de ecuaciones sean mnimos locales
se necesitan hiptesis de convexidad:
x
H(x,
j
) > 0 en el plano tangente en x (6.9)
El plano tangente en x est denido por las ecuaciones de igualdad y las
ecuaciones de desigualdad activas, es decir:
{y : h(x)
t
y = 0, g
j
(x)
t
y = 0} (6.10)
donde j es el conjunto de ndices donde las restricciones de desigualdad estn
activas. Para que (6.10) dena un plano tangente los vectores h(x) y g
j
(x)
deben ser linealmente independientes [10, 97].
La ecuaciones 7 y 8 que aparecen en (6.7):
s
i
+
j
= 0 i = 1, 2 j = 4, 5 (6.11)
se sustituyen por las ecuaciones equivalentes siguientes:
j
s
i
= 0 i = 1, 2 j = 4, 5 (6.12)
Las ecuaciones (6.12) tienen la ventaja de tener derivadas acotadas cuando
cualquier variable de holgura se aproxima a cero que no es el caso de las
ecuaciones (6.11).
6.1.2.3. Direccin de bsqueda
Aplicando el Mtodo de Newton a las ecuaciones de optimalidad de KKT
(6.7), las correcciones a las variables del problema en la iteracin k, w
k
,
vienen dadas por el sistema de ecuaciones:
F
(w
k
)w
k
= F
(w
k
) (6.13)
donde
w
k
= (x
k
, v
k
, z
k
, s
k
i
,
k
j
) i = 1, 2 j = 1, . . . , 5 (6.14)
w
k
= (x
k
, v
k
, z
k
, s
k
i
,
k
j
) i = 1, 2 j = 1, . . . , 5 (6.15)
139
Captulo 6 Programacin no Lineal no Convexa
_
x
H(x
k
,
k
j
) 0 0 0 0 h(x
k
) f(x
k
) g(x
k
) 0 0
0 0 0 0 0 0 1 0 0 1
0 0 0 0 0 0 0 1 1 0
0 0 0
k
4
0 0 0 0 s
k
1
0
0 0 0 0
k
5
0 0 0 0 s
k
2
h(x
k
) 0 0 0 0 0 0 0 0 0
f(x
k
) 1 0 0 0 0 0 0 0 0
g(x
k
) 0 1 0 0 0 0 0 0 0
0 0 1 1 0 0 0 0 0 0
0 1 0 0 1 0 0 0 0 0
_
_
(6.16)
es la matriz del sistema lineal, F
(w
k
) y el segundo miembro es:
F
(w
k
) =
_
_
H(x
k
,
k
j
)
h(x
k
)
f(x
k
) v
k
g(x
k
) z
k
z
k
+s
k
1
v
k
+s
k
2
C
k
k
4
s
k
1
k
k
5
s
k
2
k
1
k
2
+
k
5
k
3
+
k
4
_
_
(6.17)
En el sistema de ecuaciones denido por (6.13), la ecuacin 9 puede ser usa-
da para eliminar s
k
1
, la ecuacin 10 para eliminar s
k
2
, la ecuacin 4 para
eliminar
k
4
y por ltimo la ecuacin 5 para eliminar
k
5
. Por tanto, estos
incrementos vienen dados por:
s
k
1
= (z
k
+s
k
1
) z
k
(6.18)
s
k
2
= (v
k
+s
k
2
C
k
) v
k
(6.19)
k
4
=
k
s
k
1
+
k
4
s
k
1
z
k
+
k
4
s
k
1
z
k
(6.20)
k
5
=
k
s
k
2
+
k
5
s
k
2
(v
k
C
k
) +
k
5
s
k
2
v
k
(6.21)
140
Programacin no Lineal no Convexa
Y el sistema de ecuaciones de optimalidad de KKT reducido es el siguiente:
_
x
H(x
k
,
k
j
) 0 0 h(x
k
) f(x
k
) g(x
k
)
0
k
5
s
k
2
0 0 1 0
0 0
k
4
s
k
1
0 0 1
h(x
k
) 0 0 0 0 0
f(x
k
) 1 0 0 0 0
g(x
k
) 0 1 0 0 0
_
_
_
_
x
k
v
k
z
k
k
1
k
2
k
3
_
_
=
_
_
r
k
1
r
k
2
r
k
3
r
k
4
r
k
5
r
k
6
_
_
(6.22)
donde
r
k
1
= H(x
k
,
k
j
) (6.23)
r
k
2
= (1 +
k
2
+
k
5
)
s
k
2
k
5
s
k
2
(v
k
C
k
) (6.24)
r
k
3
= (
k
3
+
k
4
)
s
k
1
k
4
s
k
1
z
k
(6.25)
r
k
4
= h(x
k
) (6.26)
r
k
5
= f(x
k
) v
k
(6.27)
r
k
6
= g(x
k
) z
k
(6.28)
No se puede asegurar que la direccin de bsqueda determinada por la solucin
del sistema (6.22) sea una direccin de descenso [72, 97, 10].
La restriccin sobre la funcin objetivo (6.2) conduce a una la/columna
densa en la matriz del sistema lineal. Esto debe tenerse en cuenta para la
resolucin del sistema, ya que en casos reales se trata de una matriz dispersa
de gran dimensin y con un algoritmo de reordenacin ptima de la matriz
se puede evitar tener un nmero excesivo de elementos de llenado, lo que da
eciencia a la ejecucin del algoritmo [117].
6.1.2.4. Actualizacin de variables
Teniendo en cuenta que las condiciones de optimalidad de KKT (6.7) en
cada iteracin se resuelven de manera aproximada con una nica iteracin del
Mtodo de Newton, podra ocurrir que las variables una vez actualizadas con
sus respectivos incrementos no sean factibles en lo que respecta a las restric-
ciones de desigualdad. Para evitar esto, se calcula una longitud de avance, ,
que multiplica a todos los incrementos, los obtenidos para las variables al re-
solver el sistema (6.22) y los obtenidos con las ecuaciones (6.18)-(6.21), para
asegurar que ninguna variable, ya sea de holgura o su multiplicador asociado,
sea negativa.
141
Captulo 6 Programacin no Lineal no Convexa
En este caso, la longitud de avance, , debe cumplir:
s
k
1
+ s
k
1
0 (6.29)
s
k
2
+ s
k
2
0 (6.30)
k
4
+
k
4
0 (6.31)
k
5
+
k
5
0 (6.32)
De esta manera, una posible longitud de avance comn en la iteracin k viene
dada por:
k
= mn{
1
,
2
,
3
,
4
} (6.33)
donde
1
= mn{1,
s
k
1
s
k
1
: s
k
1
< 0} (6.34)
2
= mn{1,
s
k
2
s
k
2
: s
k
2
< 0} (6.35)
3
= mn{1,
k
4
k
4
:
k
4
< 0} (6.36)
4
= mn{1,
k
5
k
5
:
k
5
< 0} (6.37)
Para evitar la excesiva aproximacin a un lmite y asegurar la positividad
estricta de las variables en la iteracin siguiente, la longitud de avance se
limita con un factor cuyo valor tpico en la prctica suele ser = 0.9995
[133, 138].
Por tanto, las variables en la iteracin siguiente k + 1 vienen dadas por:
w
k+1
= w
k
+
k
w
k
(6.38)
donde
k
viene dada por (6.33)-(6.37) y w
k
es la solucin del sistema de
ecuaciones (6.22).
6.1.2.5. Inicializacin y reduccin del parmetro barrera
El valor inicial del parmetro que pondera las penalizaciones logartmicas
en la funcin objetivo afecta obviamente a la convergencia del algoritmo. As,
un valor elevado penaliza excesivamente cualquier movimiento de las variables
en direccin a sus lmites, mientras que un valor demasiado pequeo favorece
que muchas variables alcancen rpidamente sus lmites, haciendo ms difcil la
convergencia hacia el ptimo.
142
Programacin no Lineal no Convexa
Para permitir que las variables se puedan aproximar a sus lmites, debe
tender a cero durante el proceso iterativo. Se han propuesto mltiples tcnicas
para reducir sucesivamente en cada iteracin [119, 82, 140], pero la ms
inmediata viene dada por las condiciones de optimalidad de KKT (6.7), en las
que se observa que, en cada iteracin, es igual al producto de la holgura por
su multiplicador asociado para toda variable sujeta a lmites (6.12). As una
posible eleccin es:
= (s
k
1
k
4
+s
k
2
k
5
)/2 (6.39)
Esta forma de actualizar el parmetro barrera es una extensin directa de un
resultado terico obtenido para problemas lineales, que se detalla a continua-
cin [56]. Un mtodo de optimizacin basado en la teora de dualidad, como
es el caso de los mtodos de Punto Interior, converge cuando el error de dua-
lidad, es decir la diferencia entre la funcin objetivo del problema primal y
la funcin objetivo del problema dual, es cero. En problemas lineales el error
de dualidad es igual al producto de la holgura por su multiplicador asociado,
as este producto tiende a cero cuando el mtodo converge hacia el ptimo.
Como extensin directa de este resultado se dene para problemas no lineales
el Error de Dualidad (Duality gap), como el producto de la holgura por su
multiplicador asociado. Adems para aumentar la velocidad de convergencia el
parmetro barrera se actualiza como el error de dualidad medio, gap, por un
factor de reduccin entre 0 y 1. Es decir, el parmetro barrera en la iteracin
k viene dado por:
k
=
k
gap
k
(6.40)
El parmetro afecta a la convergencia del algoritmo, ya que el clculo de
depende de y inuye en la solucin del sistema lineal puesto que aparece
en el segundo miembro de ste. De esta manera la eleccin ptima de es muy
importante.
Analizando los casos extremos, si = 1, el parmetro barrera se va
reduciendo a la velocidad que lo hace el error dual medio, esto da lugar a
una convergencia lenta, con una mejora de la factibilidad. En estos casos, la
reduccin se hace notable en las ltimas iteraciones. Si es muy prximo
a cero, esto hace que sea muy pequeo y las variables de holgura o sus
multiplicadores alcancen la frontera de la regin factible rpidamente.
6.1.2.6. Test de convergencia
La secuencia de subproblemas parametrizados por el parmetro barrera
se resuelve de manera iterativa hasta que una serie de criterios de convergencia
se satisfacen. Los criterios adoptados son los que siguen:
143
Captulo 6 Programacin no Lineal no Convexa
Las condiciones de optimalidad de KKT (6.7) se cumplen, es decir:
max(|F
(x
k
, v
k
, z
k
, s
k
i
,
k
j
)|) <
1
(6.41)
El error de dualidad medio tiende a cero:
gap <
2
(6.42)
As, el algoritmo se resume como sigue:
Algoritmo Primal-Dual de Punto Interior
Paso 0: Inicializacin. k = 0. Se inicializan las variables teniendo en cuenta la
necesaria positividad de las variables de holgura. Se inicializa el factor
de penalizacin .
Paso 1: Test de Convergencia. Se calculan el gradiente (6.41) y el error dual
medio (6.42). Si se cumplen los criterios de convergencia se ha alcanzado
una solucin ptima, x
.
Paso 2: Ecuaciones de Optimalidad. Se resuelve el sistema de ecuaciones lineal
(6.22).
Paso 3: Longitud de Avance. Clculo de usando (6.33)-(6.37).
Paso 4: Actualizacin. Se actualizan las variables teniendo en cuenta la longitud
de avance mxima segn (6.38).
Paso 5: Reduccin del parmetro barrera. k = k + 1. Se actualiza segn (6.40).
Ir al paso 1.
6.1.2.7. Valor inicial y actualizacin de la cota de la funcin obje-
tivo
Inicialmente el valor de la cota de la funcin objetivo debe ser sucien-
temente grande, as al resolver en la primera iteracin el problema (6.3) la
restriccin (6.2) no interviene en la obtencin de la solucin. En las siguientes
iteraciones, esta cota se actualiza de la forma siguiente:
C = f(x
) (6.43)
donde x
es el ptimo local obtenido al resolver el problema (6.3) mediante el
algoritmo Primal-Dual de Punto Interior descrito en la seccin anterior.
Se puede observar que la robustez y convergencia del algoritmo Primal-
Dual de Punto Interior presentado es crucial en el buen funcionamiento del
mtodo que se propone.
144
Programacin no Lineal no Convexa
6.1.3. Un ejemplo de una variable
Se considera el problema siguiente:
Minimizar f(x)
sujeto a 3 x 10
(6.44)
donde
f(x) = exp (x) cos (20x) (6.45)
La gura 6.1 muestra los mltiples mnimos locales de la funcin f.
3 4 5 6 7 8 9 10
3
2
1
0
1
2
3
x 10
4
x1
x2
x3
x5
x6
x4
x7
Figura 6.1: Mltiples mnimos de una funcin no convexa.
Inicializando en x
0
= 3, la resolucin del problema (6.44) para la funcin
objetivo f mediante un algoritmo de Punto Interior Primal-Dual de Barrera
Logartmica nos conduce a un mnimo local (x
1
, f(x
1
)). Si se resuelve de nuevo
el problema aadiendo la restriccin siguiente:
f(x) f(x
1
) (6.46)
se obtiene un nuevo mnimo local (x
2
, f(x
2
)) que es menor que el hallado
anteriormente. As sucesivamente se obtiene el ptimo global (x
7
, f(x
7
)). Los
ptimos intermedios calculados aparecen representados por una circunferencia
en la gura 6.1.
145
Captulo 6 Programacin no Lineal no Convexa
6.2. Variables reales y enteras
6.2.1. Formulacin del problema
En general, un problema de optimizacin no lineal entera-mixta 0/1 se
formula matemticamente como sigue:
Minimizar f(x, u)
sujeto a h(x, u) = 0
g(x, u) 0
(6.47)
donde
u {0, 1}
m
es un vector de variables binarias independientes de dimen-
sin m.
x R
n
es un vector de variables independientes de dimensin n.
f : R
n
{0, 1}
m
R es una funcin escalar no lineal, no convexa y no
diferenciable. Esta funcin modela la funcin objetivo deseada.
g : R
n
{0, 1}
m
R
p
es una funcin vectorial no lineal, no convexa y no
diferenciable. Esta funcin modela tanto las restricciones de desigualdad
como las restricciones de banda sobre las variables.
h : R
n
{0, 1}
m
R
q
es una funcin vectorial no lineal, no convexa y
no diferenciable. Esta funcin modela las restricciones de igualdad.
Se trata de un problema de optimizacin no lineal, no convexa, entera-mixta
0/1 y de gran dimensin cuando se aplica a un problema basado en un ca-
so real. La caracterizacin principal de este tipo de problemas es el carcter
combinatorial que le proporciona las variables binarias.
Un problema de optimizacin donde aparecen variables binarias siempre
se puede transformar en un problema de optimizacin global con mltiples
ptimos, basta penalizar la funcin objetivo cuando las variables binarias no
toman los valores 0 1 o aadir la restriccin cuadrtica siguiente:
u (1 u) = 0 (6.48)
As el problema original (6.47) es equivalente a los dos problemas siguientes:
Minimizar f(x, u)
sujeto a h(x, u) = 0
g(x, u) 0
u(1 u) = 0
(6.49)
146
Programacin no Lineal no Convexa
Minimizar f(x, u) +Mu (1 u)
sujeto a h(x, u) = 0
g(x, u) 0
(6.50)
donde M es un factor de penalizacin.
Sin embargo, la restriccin cuadrtica (6.48) incrementa la no linealidad
y no convexidad de los problemas (6.49) y (6.50) frente al problema original
(6.47). Adems esta restriccin cuadrtica presenta un mximo en u = 0.5 con
lo cual la solucin suele tender a ese punto.
6.2.2. Mtodo propuesto
Los algoritmos de resolucin de problemas de optimizacin combinatorial
son algoritmos en tiempo no polinomial, es decir el tiempo de clculo para
resolver este tipo de problemas crece exponencialmente con el nmero de va-
riables del problema [136, 10].
Frecuentemente en la prctica, para la resolucin de estos problemas se
relaja la naturaleza discreta de las variables mediante la restriccin siguiente:
0 u 1 (6.51)
Y luego se opta por una estrategia heurstica para determinar los valores en-
teros mejores para las variables discretas [82].
En esta seccin se presenta un algoritmo novedoso para programacin no
lineal entera-mixta en tiempo polinomial que resuelve de una manera rpida
y satisfactoria este tipo de problemas.
El mtodo consiste en relajar la naturaleza discreta de las variables. Esto
se puede hacer de varias formas: permitiendo que las variables discretas to-
men valores intermedios entre 0 y 1, forzando la naturaleza discreta de stas
aadiendo una restriccin cuadrtica o penalizando la funcin objetivo cuando
las variables discretas no tomen los valores 0 1. En esta tesis, se resuelven
de manera iterativa una sucesin de subproblemas de dos tipos, uno donde
las variables discretas toman valores entre 0 y 1 (problema continuo) y otro
donde el carcter discreto se fuerza mediante una restriccin cuadrtica (pro-
blema discreto), donde la solucin del primero es el punto inicial del segundo.
A estos subproblemas se le aplica el mtodo propuesto en la seccin ante-
rior, obteniendo de esta manera, una sucesin de mnimos decrecientes para el
problema continuo y una sucesin de mnimos decrecientes para el problema
discreto, en un intento de alcanzar el ptimo global de ambos. De esta mane-
ra, para determinar los valores ptimos de las variables binarias a partir de la
147
Captulo 6 Programacin no Lineal no Convexa
solucin de los problemas con la restriccin relajada (6.51) no se usa ninguna
estrategia heurstica.
En general, los pasos del algoritmo propuesto son los siguientes:
1. Eleccin de dos cotas superiores iniciales, C y C
d
, sucientemente gran-
des.
2. Clculo de un ptimo local del problema siguiente:
Minimizar f(x, u)
sujeto a h(x, u) = 0
g(x, u) 0
0 u 1
f(x, u) C
(6.52)
3. Inicializacin con el ptimo calculado en el paso anterior.
a) Clculo de un ptimo local del problema siguiente:
Minimizar f(x, u)
sujeto a h(x, u) = 0
g(x, u) 0
u(1 u) = 0
f(x, u) C
d
(6.53)
b) Actualizacin de C
d
.
Los pasos 3a) a 3b) se repiten de manera iterativa hasta que no se pueda
encontrar un nuevo ptimo local del problema (6.53), ya sea por motivos
de convergencia o bien por haber alcanzado el ptimo global.
4. Actualizacin de C
Los pasos 2 a 4 se repiten de manera iterativa hasta que no se pueda encontrar
un nuevo ptimo local del problema (6.52), ya sea por motivos de convergencia
o bien por haber alcanzado el ptimo global.
Como se puede observar, el procedimiento propuesto simplemente est for-
mado por dos bucles: uno externo y uno interno. En el bucle externo, se obtiene
una sucesin de mnimos decrecientes del problema (6.52) y en el interno se
intenta encontrar el mejor mnimo factible discreto que haya en los alrededores
de cada mnimo continuo, resolviendo el problema (6.53) de manera iterativa.
148
Programacin no Lineal no Convexa
6.2.2.1. Solucin de los subproblemas continuos
La secuencia de subproblemas continuos (6.52) se resuelven mediante el
Algoritmo Primal-Dual de Punto Interior descrito en la seccin 6.1.2, donde
La variable independiente es un vector de dimensin n + m:
x = [x, u] (6.54)
Las restricciones de desigualdad estn modeladas por un vector de di-
mensin p + 2m:
g(x) = [g(x, u), u, u 1] (6.55)
La resolucin de estos subproblemas (6.52) mediante el algoritmo de Punto
Interior presenta una convergencia crtica debido a la proximidad de las varia-
bles u a sus barreras. Por ello, se ha implementado un mecanismo heurstico
de control de la proximidad a las barreras para las variables sujetas a lmites.
Este procedimiento consiste en jar la variable u al valor que tenga cuando una
cierta condicin se cumpla. Es decir, si en la iteracin k se tiene que el error de
dualidad de la variable de holgura asociada a u es sucientemente pequeo, se
toma u = u
k
, por lo que u toma un valor constante a lo largo de las iteraciones
restantes. Esto mejora notablemente la convergencia del algoritmo.
De igual forma, el parmetro se actualiza de manera dinmica a lo largo
de las iteraciones, con el objetivo de mejorar la factibilidad de las variables
aunque la convergencia sea un poco ms lenta.
6.2.2.2. Solucin de los subproblemas discretos
La secuencia de subproblemas discretos (6.53) se resuelven mediante el
Algoritmo Primal-Dual de Punto Interior descrito en la seccin 6.1.2, donde
La variable independiente es un vector de dimensin n + m:
x = [x, u] (6.56)
Las restricciones de igualdad estn modeladas por un vector de dimensin
q +m:
h(x) = [h(x, u), u (1 u)] (6.57)
149
Captulo 6 Programacin no Lineal no Convexa
6.2.2.3. Valores iniciales y actualizacin de las cotas de la funcin
objetivo
Inicialmente los valores de las cotas de la funcin objetivo, C y C
d
deben ser
sucientemente grandes, as al resolver en la primera iteracin los problemas
(6.52) y (6.53) esta restriccin sobre la funcin objetivo no interviene en la
obtencin de la solucin.
La actualizacin de la cota C
d
viene dada por:
C
d
= f(x
d
, u
d
) (6.58)
donde (x
d
, u
d
) es el ptimo local obtenido al resolver el problema (6.53) me-
diante el Algoritmo Primal-Dual de Punto Interior.
En las siguientes iteraciones se pueden adoptar varios esquemas de actua-
lizacin para la cota del problema continuo:
(A) C = f(x
, u
) (6.59)
(B) C = min(f(x
, u
), C
d
) (6.60)
donde (x
, u
) es el ptimo local obtenido al resolver el problema (6.52) me-
diante el Algoritmo Primal-Dual de Punto Interior.
El esquema de actualizacin (A) es una aproximacin ms conservadora que
intenta identicar todos los posibles ptimos locales del problema continuo.
Como el mejor mnimo discreto no est asociado necesariamente con el mejor
mnimo continuo se puede adoptar una estrategia ms agresiva como la del
esquema (B) la cual es ms efectiva en problemas donde hay mltiples mnimos
discretos mejores que cada mnimo continuo. Esto es debido a la existencia de
mltiples cuencas de atraccin ya que el mnimo local continuo de cada cuenca
puede estar rodeado de mnimos discretos pertenecientes a cuencas de atraccin
de un mnimo local continuo distinto. Entonces es posible encontrar mnimos
discretos mejores que un mnimo continuo, aunque los mnimos discretos son
siempre peores que los continuos cuando se trata de mnimos en la misma
cuenca de atraccin. Sin embargo para problemas generales como es el caso
del ejemplo tutorial que se presenta a continuacin es mejor adoptar el esquema
de actualizacin (A).
Las estrategias que se pueden adoptar tanto en lo que respecta a la inicia-
lizacin de los problemas de optimizacin como a la actualizacin de las cotas
de la funcin objetivo forman parte de lneas futuras de investigacin.
150
Programacin no Lineal no Convexa
6.2.3. Un ejemplo de dos variables
Se considera esta vez el problema siguiente:
Minimizar f(x, u)
sujeto a 0 x 1
u {0, 1}
(6.61)
donde
f(x, u) = 4 + sin (4 u) + sin (6 x) + 3
_
x
7
12
_
2
+ 4
_
u
7
8
_
2
(6.62)
Las guras 6.2 y 6.3 representan la supercie denida por esta funcin (6.62)
donde se observan los mltiples mximos, mnimos y puntos de silla desde
distintas perspectivas, cuando u es real y vara de forma continua en el intervalo
[0, 1].
0
0.2
0.4
0.6
0.8
1
0
0.2
0.4
0.6
0.8
1
2
4
6
8
10
Figura 6.2: Supercie denida por una funcin no lineal no convexa.
151
Captulo 6 Programacin no Lineal no Convexa
0
0.5
1
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
2
3
4
5
6
7
8
9
10
Figura 6.3: Supercie denida por una funcin no lineal no convexa.
152
Programacin no Lineal no Convexa
De igual forma, las lneas de contorno de la funcin estn representadas en
la gura 6.4.
0 0.1 0.2 0.3 0.4 0.5 0.6 0.7 0.8 0.9 1
0
0.1
0.2
0.3
0.4
0.5
0.6
0.7
0.8
0.9
1
x
(x1,u1)
(x2,u2) (x3,u3)
(x4,u4)
(x5,u5)
u
Figura 6.4: Sucesin de mnimos locales para el ejemplo mixto-entero.
Comenzando con el punto inicial x
0
= 0.5, u
0
= 0.5, e ignorando la natura-
leza discreta de u (problema (6.52)), el algoritmo de Punto Interior converge al
ptimo local x
1
= 0.583, u
1
= 0.399 para el cual el valor de la funcin objetivo
es f(x
1
, u
1
) = 2.95.
Ahora, la atencin se centra en encontrar un mnimo cercano para el que u
es 0 1. Comenzando en (x
1
, u
1
), y resolviendo el problema (6.53), el algoritmo
de Punto Interior converge al punto x
2
= 0.753, u
2
= 0 para el cual la funcin
objetivo vale f(x
2
, u
2
) = 8.14. A la vista del valor de la funcin objetivo, se
hace un nuevo intento de encontrar un mejor mnimo discreto, comenzando de
nuevo en (x
1
, u
1
) pero aadiendo la restriccin:
f(x, u) f(x
2
, u
2
) (6.63)
Esto conduce al punto x
3
= 0.91, u
3
= 0 cuyo valor de la funcin objetivo
es f(x
3
, u
3
) = 6.39. No se obtiene un mejor mnimo si el proceso se repite
153
Captulo 6 Programacin no Lineal no Convexa
aadiendo de nuevo la restriccin:
f(x, u) f(x
3
, u
3
) (6.64)
Sin embargo, adoptando de nuevo el problema relajado (6.52), comenzando
en (x
0
, u
0
) y aadiendo la restriccin:
f(x, u) f(x
1
, u
1
) (6.65)
se obtiene un nuevo punto x
4
= 0.583, u
4
= 0.875. Este punto es para este
ejemplo, el mnimo global si la naturaleza discreta de u se ignora y cuyo valor
es f(x
4
, u
4
) = 2.
Finalmente, comenzando en (x
4
, u
4
) y teniendo en cuenta una vez ms la
restriccin (6.48), se obtiene el punto x
5
= 0.583, u
5
= 1, el cual es el mnimo
global discreto con un valor f(x
5
, u
5
) = 3.06.
154
Captulo 7
Aplicacin: Programacin Horaria
de Centrales
Para demostrar la efectividad del algoritmo presentado anteriormente, en
este captulo se aplica a un problema de planicacin de un sistema de energa
elctrica centralizado conocido como Programacin Horaria de Centrales Elc-
tricas. En primer lugar, se describe y modela este problema, el cual conduce a
un problema de optimizacin no lineal entero-mixto 0/1. En segundo lugar, la
solucin de los subproblemas, que aparecen al aplicar el mtodo propuesto, se
describe brevemente resaltando la estructuras de las matrices resultantes. Por
ltimo, se presentan resultados obtenidos de la aplicacin del mtodo a dos
casos de estudio basados en el parque de generacin espaol, un sistema test
de pequea dimensin y un sistema realista de gran dimensin. Los resulta-
dos obtenidos se comparan con los obtenidos de la aplicacin de un Algoritmo
Gentico.
7.1. Formulacin del problema
La Programacin Horaria de Centrales Elctricas tiene por objeto deter-
minar los arranques y paradas de las centrales trmicas (Unit Commitment) y
la programacin conjunta de potencia generada por los grupos trmicos e hi-
drulicos (Coordinacin Hidrotrmica) durante un horizonte temporal de corto
plazo, normalmente 24 horas, de manera que se satisfaga la demanda horaria,
estimada en base a una prediccin, y se minimice el coste de explotacin del
sistema.
155
Captulo 7 Aplicacin: Programacin Horaria de Centrales
7.1.1. Funcin objetivo.
7.1.1.1. Costes de produccin
Para cada central trmica existe una funcin que relaciona la produccin
con el coste que esa produccin implica. Sea n
g
el nmero de centrales trmi-
cas y n
t
el nmero de intervalos horarios (normalmente horas) que forman el
horizonte de programacin. Las curvas de costes de produccin de las centra-
les trmicas, C
i,t
, se pueden aproximar, sin prdida de generalidad, por una
funcin cuadrtica de la potencia media de cada central en el periodo t como
muestra la gura 7.1.
Pmin Pmax
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
Potencia
C
o
s
t
e
d
e
p
r
o
d
u
c
c
i
n
Figura 7.1: Coste de produccin.
Es decir:
C
i,t
= C(P
i,t
) = a
i
P
2
i,t
+b
i
P
i,t
+c
i
i = 1, ..., n
g
t = 1, ..., n
t
(7.1)
donde
P
i,t
es la potencia media suministrada por el generador i en el periodo t.
a
i
, b
i
y c
i
son los coecientes de la funcin cuadrtica.
7.1.1.2. Costes de arranque
El coste de arranque de las centrales trmicas, CA
i,t
, es el coste de poner
en funcionamiento una central, tras haber estado desacoplada un determina-
do periodo de tiempo. Estos costes bsicamente representan la energa que
156
Aplicacin: Programacin Horaria de Centrales
necesita la central trmica para alcanzar la temperatura y presin sucientes
para el momento del acoplamiento a la red. Estos costes aumentan de manera
exponencial con el tiempo que la central lleve desacoplada, como muestra la
gura 7.2.
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .
C
o
s
t
e
d
e
a
r
r
a
n
q
u
e
Horas de desacoplamiento
Figura 7.2: Coste de arranque.
Es decir:
CA
i,t
(S
i,t
) = CC
i
(1 e
S
i,t1
/
i
) +CF
i
(7.2)
donde
CC
i
es el coste variable de arranque del generador i.
CF
i
es el coste jo de arranque del generador i
S
i,t
es el nmero de horas que el generador i lleva desacoplado en la hora
t.
i
es la constante de tiempo trmica del generador i.
7.1.1.3. Costes de parada
Los costes de parada son constantes para cada central y representan bsi-
camente la prdida de combustible debida a la potencia que se est generando
mientras que la central se est desacoplando, potencia que principalmente es-
t determinada por la rampa de bajada de la central y al enfriamiento de la
caldera una vez que la central est desacoplada.
157
Captulo 7 Aplicacin: Programacin Horaria de Centrales
As el coste total a minimizar, C
T
, viene dado por:
C
T
=
nt
t=1
ng
i=1
C
i,t
U
i,t
+CA
i,t
(S
i,t
) Y
i,t
+CP
i
Z
i,t
(7.3)
donde
U
i,t
es una variable binaria que es igual a 1 si el generador i est acoplado
en la hora t.
Y
i,t
es una variable binaria que es igual a 1 si el generador i se acopla al
principio de la hora t.
Z
i,t
es una variable binaria que es igual a 1 si el generador i se desacopla
al principio de la hora t.
C
i,t
son los costes de produccin dados por (7.1).
CA
i,t
(S
i,t
) son los costes de arranque dados por (7.2).
CP
i
son los costes de parada que se consideran independientes del tiempo.
Los arranques y paradas de las centrales trmicas modelados mediante las
variables binarias Y
i,t
y Z
i,t
deben mantener una lgica, por ejemplo que una
central no puede ser arrancada y parada en la misma hora, etc. Este tipo de
restricciones lgicas se modelan con las ecuaciones que siguen:
Y
i,t
Z
i,t
= U
i,t
U
i,t1
(7.4)
Y
i,t
+Z
i,t
1 (7.5)
Obsrvese que las variables Y
i,t
y Z
i,t
se pueden poner en funcin de la variable
U
i,t
de la forma siguiente:
Y
i,t
= U
i,t
(1 U
i,t1
) (7.6)
Z
i,t
= U
i,t1
(1 U
i,t
) (7.7)
Estas variables, Y
i,t
, Z
i,t
, modeladas como (7.6)-(7.7) verican las restricciones
lgicas (7.4)-(7.5). El cumplimiento de la segunda restriccin (7.5), se muestra
en la tabla 7.1, teniendo en cuenta que:
Y
i,t
+Z
i,t
= U
i,t
+U
i,t1
2 U
i,t
U
i,t1
(7.8)
158
Aplicacin: Programacin Horaria de Centrales
U
i,t
U
i,t1
2 U
i,t
U
i,t1
Y
i,t
+Z
i,t
0 0 0 0
1 1 -2 0
0 1 0 1
1 0 0 1
Tabla 7.1: Vericacin de una restriccin lgica.
De esta manera el nmero de variables binarias se puede disminuir, trans-
formando la funcin objetivo (7.3) en la funcin equivalente siguiente:
C
T
=
nt
t=1
ng
i=1
C
i,t
U
i,t
+CA
i,t
U
i,t
(1 U
i,t1
) +CP
i
U
i,t1
(1 U
i,t
)(7.9)
La funcin objetivo (7.9) es menos lineal que la funcin objetivo (7.3) puesto
que aparecen nuevos productos de variables binarias.
7.1.2. Restricciones
Las distintas restricciones que aparecen en el problema de la Programacin
Horaria de Centrales Trmicas e Hidrulicas se pueden agrupar en: restriccio-
nes del sistema y restricciones propias de las centrales. Las restricciones del
sistema, entre las que se encuentran las restricciones de demanda y de reserva
rodante, acoplan a las centrales trmicas e hidrulicas en un mismo periodo
de tiempo. Las restricciones tcnicas son caractersticas de cada central segn
sea trmica o hidrulica. Entre ellas cabe destacar: las restricciones de rampas
de subida y bajada, las restricciones de acoplamiento entre embalses hidruli-
cos debido a la continuidad del agua, las restricciones de potencias mximas y
mnimas y las restricciones de volmenes mximos y mnimos.
7.1.2.1. Restricciones tcnicas de las centrales trmicas
Las restricciones tcnicas de las centrales trmicas son las siguientes:
La limitacin mxima y mnima de produccin, que se modela
como sigue:
P
m
i
P
i,t
P
M
i
i = 1, . . . , n
g
t = 1, . . . , n
t
(7.10)
donde P
M
i
es la potencia mxima de la central trmica i, llamada poten-
cia nominal y P
m
i
es la potencia mnima de la central trmica i, llamada
159
Captulo 7 Aplicacin: Programacin Horaria de Centrales
mnimo tcnico. Estos lmites hay que tenerlos en cuenta slo en las ho-
ras que la central est acoplada, ya que en caso contrario la potencia es
cero.
Las rampas de subida y bajada. Este tipo de centrales no puede
aumentar o disminuir su produccin de una hora a la siguiente en ms
de una determinada cantidad. Esto se modela as:
RB
i
P
i,t
P
i,t1
RS
i
i = 1, . . . , n
g
t = 1, . . . , n
t
(7.11)
donde RS
i
es la rampa mxima de subida de la central trmica i, es
decir la mxima potencia que una central puede aumentar en dos horas
sucesivas y RB
i
es la rampa mxima de bajada de la central trmica i, es
decir la mxima potencia que una central puede disminuir su produccin
al pasar a la hora siguiente.
Tiempos mnimos de funcionamiento y parada. Con el objetivo
de que no haya un envejecimiento prematuro de las unidades trmicas
se evitan los acoplamientos y desacoplamientos con excesiva frecuencia.
El tiempo mnimo de funcionamiento es el nmero mnimo de horas que
una central debe permanecer acoplada una vez que se pone en funcio-
namiento. De forma anloga, el tiempo mnimo de parada representa el
nmero mnimo de horas que una central debe mantenerse desacoplada
una vez que deja de funcionar. Esto se modela como sigue:
(X
i,t
UT
i
) (U
i,t1
U
i,t
) 0 (7.12)
(S
i,t
+DT
i
) (U
i,t
U
i,t1
) 0 (7.13)
donde X
i,t
es una variable que indica el nmero de horas que lleva acopla-
da la central i al nal de la hora t y UT
i
y DT
i
son los tiempos mnimos
de funcionamiento y parada de la central i respectivamente.
Las variables S
i,t
y X
i,t
, teniendo en cuenta la programacin de arranques y
paradas, se pueden modelar con las ecuaciones siguientes:
X
i,t
= (X
i,t1
(1 Y
i,t
) + 1) U
i,t
(7.14)
S
i,t
= (S
i,t1
(1 Z
i,t
) + 1) (1 U
i,t
) (7.15)
7.1.2.2. Restricciones tcnicas de las centrales hidrulicas
Sea n
h
el nmero de centrales hidrulicas de una cuenca. Las centrales
hidrulicas no tienen ningn coste asociado puesto que usan como combustible
para generar energa elctrica el agua. Las restricciones tcnicas de las centrales
hidrulicas son las siguientes:
160
Aplicacin: Programacin Horaria de Centrales
Acoplamiento entre volmenes. Para cada central hidrulica existe
una funcin no lineal que relaciona la produccin de potencia elctrica
con el caudal de agua turbinada y con el volumen de agua del embalse
asociado a dicha central. Es decir:
PH
h,t
= PH
h,t
(Q
h,t
, V H
h,t
) h = 1, . . . , n
h
t = 1, . . . , n
t
(7.16)
donde PH
h,t
es la potencia hidrulica generada por la central h en el
intervalo temporal t, Q
h,t
el caudal de agua del embalse h en el intervalo
temporal t y V H
h,t
el volumen de agua del embalse h, asociado a la
central h, en el intervalo temporal t.
En horizontes temporales de corto plazo los volmenes de los embalses
no tienen una variacin signicativa, de esta manera se puede suponer
que la potencia hidrulica es una funcin no lineal tan slo del caudal de
agua turbinado. Para simplicar el modelo se ha supuesto que la potencia
y el caudal estn relacionados de una forma lineal, es decir:
PH
h,t
= C
h
Q
h,t
h = 1, . . . , n
h
t = 1, . . . , n
t
(7.17)
Al tratarse de centrales situadas en una cuenca hidrulica, existe un
acoplamiento espacio-tiempo entre las distintas centrales de la cuenca,
pues parte del agua que turbina una central para generar energa es usada
por la central situada justo aguas abajo cuando llega a su embalse con un
cierto retraso temporal. Este acoplamiento se puede modelar mediante
la siguiente restriccin:
V H
h,t
= V H
h,t1
Q
h,t
+
sig(k)=h
Q
k,tret(k)
+W
h
(7.18)
donde ret(h) es el tiempo en horas desde que se vierte el agua turbinada
en la central h hasta que llega al siguiente embalse, sig(h), situado aguas
abajo de la central h, y W
h
son las aportaciones externas en el embalse
asociado a la central h.
Usando la relacin (7.17), se puede escribir la ecuacin (7.18) de la forma
siguiente:
V H
h,t
= V H
h,t1
PH
h,t
+
sig(k)=h
PH
k,tret(k)
+W
h
(7.19)
Limitacin del agua disponible. Las centrales hidrulicas tienen res-
tricciones de combustible, ya que su combustible, el agua, es un recurso
161
Captulo 7 Aplicacin: Programacin Horaria de Centrales
limitado. As la energa hidrulica de una central est limitada por el
volumen de agua disponible en el embalse asociado a sta. A su vez la
capacidad de cada embalse est sujeta a lmites, es decir:
V H
m
h
V H
h,t
V H
M
h
h = 1, . . . , n
h
t = 1, . . . , n
t
(7.20)
donde V H
m
h
, V H
M
h
son los lmites mnimos y mximos sobre el volumen
del embalse asociado a la central hidrulica h, respectivamente.
Limitacin de la produccin. Por ltimo, las centrales hidrulicas
tienen lmites mximos y mnimos de produccin, es decir:
PH
m
h
PH
h,t
PH
M
h
h = 1, . . . , n
h
t = 1, . . . , n
t
(7.21)
donde PH
m
h
y PH
M
h
son los lmites sobre la potencia de la central hi-
drulica h.
Limitacin del caudal. El caudal de agua de cada embalse est limi-
tado por un caudal mximo y mnimo, es decir:
Q
m
h
Q
h,t
Q
M
h
h = 1, . . . , n
h
t = 1, . . . , n
t
(7.22)
donde Q
m
h
y Q
M
h
son los lmites mnimos y mximos sobre el caudal del
embalse asociado a la central hidrulica h, respectivamente.
7.1.2.3. Restricciones de demanda
La potencia consumida en cada intervalo horario se supone constante. As
la curva de demanda se modela como una funcin constante a trozos como
muestra la gura 7.3 que corresponde a la demanda del 10 de junio del ao
1998.
Las restricciones de demanda vienen dadas por:
162
Aplicacin: Programacin Horaria de Centrales
0
5000
10000
15000
20000
25000
1 3 5 7 9 11 13 15 17 19 21 23
Horas
D
e
m
a
n
d
a
(
M
W
)
Figura 7.3: Curva de demanda de potencia.
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
= D
t
t = 1, ..., n
t
(7.23)
donde D
t
es la potencia demandada en el periodo t estimada en base a una
prediccin.
Para incluir las prdidas de la red de transporte en esta ecuacin bastara
aadir una estimacin de las prdidas en el segundo miembro, de manera
que la suma de las potencias generadas sea igual a la suma de las potencias
consumidas ms las prdidas de la red de transporte.
7.1.2.4. Restricciones de reserva rodante
La reserva rodante es la potencia que el sistema debe ser capaz de pro-
porcionar de forma rpida en caso de fallo en alguna central. En realidad es
un margen de seguridad sobre la potencia demandada estimada para asegurar
163
Captulo 7 Aplicacin: Programacin Horaria de Centrales
que sta siempre se suministre, incluso en el peor de los casos. Para ello se
impone que la suma de los mrgenes de potencia disponibles tanto trmicos
como hidrulicos sea mayor o igual que la reserva, que se suele tomar como
una fraccin de la demanda o la potencia mxima de la central mayor acoplada
en el intervalo t. Esto se formula como sigue:
ng
i=1
(P
M
i
P
i,t
) U
i,t
+
n
h
h=1
(PH
M
h
PH
h,t
) R
t
t = 1, . . . , n
t
(7.24)
donde R
t
es la reserva rodante en la hora t.
El problema de optimizacin consiste en minimizar la funcin objetivo (7.9)
sujeto a las restricciones (7.10)-(7.15), (7.19)-(7.21) y (7.23)-(7.24).
As el problema queda como sigue:
Minimizar C
T
(7.25)
sujeto a
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
= D
t
(7.26)
ng
i=1
(P
M
i
P
i,t
) U
i,t
+
n
h
h=1
(PH
M
h
PH
h,t
) R
t
(7.27)
V H
h,t
= V H
h,t1
PH
h,t
+
sig(k)=h
PH
k,tret(k)
+W
h
(7.28)
X
i,t
= (X
i,t1
(1 Y
i,t
) + 1) U
i,t
(7.29)
S
i,t
= (S
i,t1
(1 Z
i,t
) + 1) (1 U
i,t
) (7.30)
Y
i,t
= U
i,t
(1 U
i,t1
) (7.31)
Z
i,t
= U
i,t1
(1 U
i,t
) (7.32)
(X
i,t
UT
i
) (U
i,t1
U
i,t
) 0 (7.33)
(S
i,t
+DT
i
) (U
i,t
U
i,t1
) 0 (7.34)
P
m
i
U
i,t
P
i,t
P
M
i
U
i,t
(7.35)
RB
i
P
i,t
P
i,t1
RS
i
(7.36)
PH
m
h
PH
h,t
PH
M
h
(7.37)
V H
m
h
V H
h,t
V H
M
h
(7.38)
Se trata de un problema de optimizacin no lineal no convexo y acoplado
en tiempo y espacio, acoplamiento que se debe tanto a las restricciones sobre
la variacin de la potencia generada en horas consecutivas, como a la propia
topologa de la cuenca hidrulica considerada, que conlleva un retraso temporal
164
Aplicacin: Programacin Horaria de Centrales
entre el vertido de agua en un embalse y la disponibilidad de dicha agua en
embalses situados aguas abajo. Adems de la complejidad del problema de
optimizacin, en sistemas de tamao realista el nmero de variables es muy
elevado, lo que hace an ms complicada su resolucin.
En la prctica, las restricciones de tiempo mnimo de parada y funciona-
miento no son importantes (restricciones (7.12)-(7.15)), puesto que el nmero
de arranques y paradas de las centrales trmicas tiende a ser lo ms pequeo
posible debido a que los arranques y paradas aparecen en la funcin objetivo
penalizados por sus respectivos costes.
Por simplicidad, los costes de arranques se considerarn constantes, es decir:
CA
i,t
(S
i,t
) = CA
i
(7.39)
7.2. Solucin mediante el mtodo propuesto
7.2.1. Subproblema continuo
El subproblema de optimizacin continuo es el siguiente:
Minimizar C
T
(7.40)
sujeto a
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
= D
t
(7.41)
ng
i=1
P
M
i
U
i,t
R
t
+D
t
n
h
h=1
PH
M
h
(7.42)
V H
h,t
= V H
h,t1
PH
h,t
+
sig(k)=h
PH
k,tret(k)
+W
h
(7.43)
P
m
i
P
i,t
P
M
i
(7.44)
0 U
i,t
1 (7.45)
C
T
C (7.46)
RB
i
P
i,t
P
i,t1
RS
i
(7.47)
PH
m
h
PH
h,t
PH
M
h
(7.48)
V H
m
h
V H
h,t
V H
M
h
(7.49)
Este problema se resuelve mediante el algoritmo Primal-Dual de Punto
Interior descrito en la seccin 6.1.2 donde:
La variable independiente es un vector de dimensin (2n
g
+ 2n
h
) n
t
x = [P
i,t
, PH
h,t
, V H
h,t
, U
i,t
] (7.50)
165
Captulo 7 Aplicacin: Programacin Horaria de Centrales
La funcin objetivo es:
f(x) = C
T
(7.51)
Las restricciones de igualdad estn modeladas por un vector de dimensin
n
t
+n
h
n
t
h(x) = [h
1
t
(x), h
2
h,t
(x)] (7.52)
donde:
h
1
t
(x) =
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
D
t
(7.53)
h
2
h,t
(x) = V H
h,t
V H
h,t1
+PH
h,t
sig(k)=h
PH
k,tret(k)
W
h
(7.54)
Las restricciones de desigualdad estn modeladas por un vector de di-
mensin n
t
+ 6n
g
n
t
+ 4n
h
n
t
+ 1
g(x) = [g
1
t
(x), g
2
i,t
(x), g
3
i,t
(x), g
4
i,t
(x), g
5
i,t
(x), g
6
i,t
(x), (7.55)
g
7
i,t
(x), g
8
(x), g
9
h,t
(x), g
10
h,t
(x), g
11
h,t
(x), g
12
h,t
(x)]
donde:
g
1
t
(x) = R
t
+D
t
n
h
h=1
PH
M
h
ng
i=1
P
M
i
U
i,t
(7.56)
g
2
i,t
(x) = P
i,t
P
M
i
(7.57)
g
3
i,t
(x) = P
m
i
P
i,t
(7.58)
g
4
i,t
(x) = P
i,t
P
i,t1
RS
i
(7.59)
g
5
i,t
(x) = RB
i
P
i,t
+P
i,t1
(7.60)
g
6
i,t
(x) = U
i,t
1 (7.61)
g
7
i,t
(x) = U
i,t
(7.62)
g
8
(x) = C
T
C (7.63)
g
9
h,t
(x) = PH
h,t
PH
M
h
(7.64)
g
10
h,t
(x) = PH
m
h
PH
h,t
(7.65)
g
11
h,t
(x) = V H
h,t
V H
M
h
(7.66)
g
12
h,t
(x) = V H
m
h
V H
h,t
(7.67)
166
Aplicacin: Programacin Horaria de Centrales
Las ecuaciones y la estructura por bloques de la matriz del sistema lineal
resultante se describe de manera detallada en el Apndice D.
A continuacin se muestra un ejemplo, basado en un sistema test, para
ilustrar la estructura de la matriz del sistema lineal que hay que resolver.
0 20 40 60 80 100
0
20
40
60
80
100
nz = 449
0 20 40 60 80 100
0
20
40
60
80
100
nz = 1168
Figura 7.4: a) Matriz de optimizacin, b) Elementos de llenado
0 20 40 60 80 100
0
20
40
60
80
100
nz = 449
0 20 40 60 80 100
0
20
40
60
80
100
nz = 827
Figura 7.5: a) Matriz de optimizacin reordenada, b) Elementos de llenado
167
Captulo 7 Aplicacin: Programacin Horaria de Centrales
Ejemplo Ilustrativo:
Sea un sistema formado por tres centrales trmicas y cuatro centrales hi-
drulicas en cascada con un retraso de un embalse a otro de una hora. El
horizonte temporal est dividido en cuatro intervalos horarios.
Entonces se tiene que la estructura de la matriz del sistema de ecuaciones
es la que se muestra en la gura 7.4a, donde nz (nozeros) es el nmero
de elementos distinto de cero. En la gura 7.4b se muestran los elementos
de llenado que aparecen al factorizar esta matriz de optimizacin, stos se
representan con un cuadrado mientras que los elementos de la matriz que ya
existan se representan con un punto.
Los elementos de llenado son causados principalmente por las ecuaciones
de acoplamiento hidrulico, en este ejemplo la matriz tiene 449 elementos no
nulos y aparecen 719 elementos de llenado. Haciendo una reordenacin de la
matriz por un algoritmo de mnimo grado [117], se obtiene la matriz de la
gura 7.5a, donde el nmero de elementos de llenado es 378 como se muestra
en la gura 7.5b, aproximadamente una reduccin en el nmero de elementos
de llenado de un 50 %.
7.2.2. Subproblema discreto
El subproblema de optimizacin discreto es el siguiente:
Minimizar C
T
(7.68)
sujeto a
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
= D
t
(7.69)
ng
i=1
P
M
i
U
i,t
R
t
+D
t
n
h
h=1
PH
M
h
(7.70)
V H
h,t
= V H
h,t1
PH
h,t
+
sig(k)=h
PH
k,tret(k)
+W
h
(7.71)
P
m
i
P
i,t
P
M
i
(7.72)
U
i,t
(1 U
i,t
) = 0 (7.73)
C
T
C
d
(7.74)
RB
i
P
i,t
P
i,t1
RS
i
(7.75)
PH
m
h
PH
h,t
PH
M
h
(7.76)
V H
m
h
V H
h,t
V H
M
h
(7.77)
Este problema se resuelve mediante el algoritmo Primal-Dual de Punto
Interior descrito en la seccin 6.1.2 donde:
168
Aplicacin: Programacin Horaria de Centrales
La variable independiente es un vector de dimensin (2n
g
+ 2n
h
) n
t
x = [P
i,t
, PH
h,t
, V H
h,t
, U
i,t
] (7.78)
La funcin objetivo es:
f(x) = C
T
(7.79)
Las restricciones de igualdad estn modeladas por un vector de dimensin
(1 +n
h
+n
g
) n
t
h(x) = [h
1
t
(x), h
2
h,t
(x), h
3
i,t
(x)] (7.80)
donde:
h
1
t
(x) =
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
D
t
(7.81)
h
2
h,t
(x) = V H
h,t
V H
h,t1
+PH
h,t
sig(k)=h
PH
k,tret(k)
W
h
(7.82)
h
3
i,t
(x) = U
i,t
(1 U
i,t
) (7.83)
Las restricciones de desigualdad estn modeladas por un vector de di-
mensin n
t
+ 4n
g
n
t
+ 4n
h
n
t
+ 1
g(x) = [g
1
t
(x), g
2
i,t
(x), g
3
i,t
(x), g
4
i,t
(x), g
5
i,t
(x), g
6
(x), g
7
h,t
(x),
g
8
h,t
(x), g
9
h,t
(x), g
10
h,t
(x)] (7.84)
donde:
g
1
t
(x) = R
t
+D
t
n
h
h=1
PH
M
h
ng
i=1
P
M
i
U
i,t
(7.85)
g
2
i,t
(x) = P
i,t
P
M
i
(7.86)
g
3
i,t
(x) = P
m
i
P
i,t
(7.87)
g
4
i,t
(x) = P
i,t
P
i,t1
RS
i
(7.88)
g
5
i,t
(x) = RB
i
P
i,t
+P
i,t1
(7.89)
g
6
(x) = C
T
C
d
(7.90)
g
7
h,t
(x) = PH
h,t
PH
M
h
(7.91)
g
8
h,t
(x) = PH
m
h
PH
h,t
(7.92)
g
9
h,t
(x) = V H
h,t
V H
M
h
(7.93)
169
Captulo 7 Aplicacin: Programacin Horaria de Centrales
g
10
h,t
(x) = V H
m
h
V H
h,t
(7.94)
Las ecuaciones y la estructura por bloques de la matriz del sistema lineal
resultante se describe de manera detallada en el Apndice D.
A continuacin se muestra un ejemplo, basado en un sistema test, para
ilustrar la estructura de la matriz del sistema lineal que hay que resolver en
este caso.
0 20 40 60 80 100
0
20
40
60
80
100
nz = 473
0 20 40 60 80 100
0
20
40
60
80
100
nz = 1643
Figura 7.6: a) Matriz de optimizacin, b) Elementos de llenado
0 20 40 60 80 100
0
20
40
60
80
100
nz = 473
0 20 40 60 80 100
0
20
40
60
80
100
nz = 990
Figura 7.7: a) Matriz de optimizacin reordenada, b) Elementos de llenado
170
Aplicacin: Programacin Horaria de Centrales
Ejemplo Ilustrativo:
Considrese el mismo sistema test de antes. Entonces se tiene que la estruc-
tura de la matriz del sistema de ecuaciones es la que se muestra en la gura
7.6a. En la gura 7.6b se muestran los elementos de llenado que aparecen al
factorizar la matriz de optimizacin, stos se representan con un cuadrado
mientras que los elementos de la matriz que ya existan se representan con un
punto.
Los elementos de llenado son causados principalmente por las ecuaciones
de acoplamiento hidrulico, en este ejemplo la matriz tiene 473 elementos no
nulos y aparecen 1170 elementos de llenado. Haciendo una reordenacin de
la matriz por un algoritmo de mnimo grado [117], se obtiene la matriz de la
gura 7.7a, donde el nmero de elementos de llenado es 517 como se muestra
en la gura 7.7b, aproximadamente una reduccin en el nmero de elementos
de llenado de un 50 %.
7.3. Resultados
En esta seccin se presentan los resultados obtenidos por el mtodo presen-
tado en la seccin 6.2.2, de su aplicacin al problema de Programacin Horaria
de Centrales Elctricas modelado anteriormente.
En primer lugar, se analizan los resultados obtenidos al adoptar distin-
tos esquemas de actualizacin (6.59)-(6.60) de la cota impuesta a la funcin
objetivo para dos casos de estudio distintos. El primer caso de estudio es un
sistema test de pequea dimensin que se ha usado para validar el mtodo pro-
puesto. El segundo es un sistema de tamao realista basado en el parque de
generacin trmica espaol. Finalmente, se presentan los resultados obtenidos
de la aplicacin de un Algoritmo Gentico [123] para comparar las soluciones
alcanzadas por ambos mtodos.
Los datos de entrada de los dos casos de estudio se detallan en el Apndice
B. El sistema test est formado por 5 centrales trmicas y el sistema de tamao
realista est formado por 49 generadores y se basa en el sistema de generacin
espaol. El horizonte temporal de programacin es un da dividido en 24 horas.
En la tabla 7.2 se presenta la secuencia de mnimos locales obtenidos para
el sistema test usando el esquema de actualizacin dado por (6.59).
Se puede observar que, en las iteraciones 6, 7, 8 y 9, el problema de optimi-
zacin discreto alcanza la misma solucin inicializando el algoritmo de Punto
Interior con soluciones del problema de optimizacin continuo diferentes. Ade-
ms, en las iteraciones 11, 13 y 14, el problema discreto no alcanza ninguna
solucin factible inicializando con las respectivas soluciones del problema con-
171
Captulo 7 Aplicacin: Programacin Horaria de Centrales
Iteracin Coste en euros
Problema Continuo Problema Discreto
1 863072 594407
2 810518 531000
3 771204 529838
4 736237 529580
5 704342 528999
6 676478 528484
7 652025 528484
8 630573 528484
9 613612 528484
10 597874 513257
11 584346 Infactible
12 572451 512419
13 567611 Infactible
14 564055 Infactible
15 Infactible
Tabla 7.2: Secuencia de mnimos locales.
tinuo.
En la tabla 7.3 se puede apreciar que la solucin que alcanza el problema
discreto es mejor que la del problema continuo en cada iteracin. Esto es debido
a que el mnimo discreto alcanzado pertenece a una cuenca de atraccin de un
mnimo local continuo mejor que el punto inicial considerado. Esto ocurre de-
bido a la gran cantidad de mnimos locales distintos, con valores muy cercanos
entre s, que presenta el problema de la Programacin Horaria de Centrales,
ya que hay generadores trmicos con costes muy parecidos.
La tabla 7.3 presenta la secuencia de mnimos locales obtenidos para el
sistema test usando el esquema de actualizacin dado por (6.60).
Se puede ver, que hay una gran reduccin en el nmero de iteraciones con
Iteracin Coste en euros
Problema Continuo Problema Discreto
1 863072 594407
2 578531 512419
3 Infactible
Tabla 7.3: Secuencia de mnimos locales.
172
Aplicacin: Programacin Horaria de Centrales
este esquema de actualizacin. Tanto con una estrategia de actualizacin como
con otra se ha alcanzado nalmente el mismo mnimo local, lo cual sugiere que
quizs este mnimo sea el ptimo global en este caso.
Debido a las caractersticas especcas del problema de la Programacin
Horaria de Centrales, principalmente la gran cantidad de mnimos locales con
valores muy parecidos, se ha optado por el esquema de actualizacin dado por
(6.60) que es ms rpido y efectivo en este tipo de problemas.
La tabla 7.4 muestra la secuencia de mnimos locales obtenidos para el
sistema de tamao realista cuando se usa el esquema de actualizacin dado
por (6.60).
Iteracin Coste en euros
Problema Continuo Problema Discreto
1 6796118 4881891
2 4881644 4670545
3 Infactible
Tabla 7.4: Secuencia de mnimos locales.
7.3.1. Comparacin con algoritmos genticos
Los Algoritmos Genticos son tcnicas computacionales basadas en meca-
nismos de seleccin natural en las cuales las soluciones de un problema son
codicadas como la estructura gentica de un organismo biolgico.
Cada individuo de la poblacin representa una posible solucin del pro-
blema y se le asigna una medida de calidad a cada miembro de la poblacin.
Los individuos mejor adaptados al medio tendrn una medida de la calidad
mayor que el resto. Un Algoritmo Gentico se caracteriza por parmetros y
operadores tales como: tamao de la poblacin, probabilidad de mutacin y
cruce y mecanismos para la creacin de una nueva poblacin.
En el Algoritmo Gentico implementado [122, 79], cada individuo se dene
por el estado arrancado/parado de cada generador trmico y la medida de
calidad viene dada por la solucin del Despacho Econmico de la Generacin
Trmica para el periodo de un da.
El algoritmo bsico es como sigue:
1. Una poblacin se selecciona aleatoriamente.
2. Clculo de la medida de la calidad de cada individuo.
3. Seleccin de los padres aleatoriamente mediante un sorteo tipo ruleta.
173
Captulo 7 Aplicacin: Programacin Horaria de Centrales
4. Se cruzan los padres para crear nuevos individuos.
5. Los nuevos individuos son mutados.
6. Los miembros con una medida de calidad baja son reemplazados por
nuevos individuos.
7. Si no se alcanza el nmero mximo de generaciones, ir al paso 2.
Cada individuo de la poblacin se representa mediante una matriz de ceros
y unos, con tantas columnas como nmero de periodos del horizonte temporal,
y tantas las como nmero de centrales trmicas. Si el elemento que ocupa la
la i y la columna j de la matriz es un uno, la central i est acoplada en el
intervalo j. De forma anloga, si el elemento que ocupa la la i y la columna
j de la matriz es un cero, la central i no est acoplada en el intervalo j.
Para obtener una nueva generacin, se seleccionan aleatoriamente los indi-
viduos de la generacin actual mediante un algoritmo de muestreo tipo ruleta,
donde la probabilidad de seleccin de un individuo es proporcional a la inversa
de su coste, que viene dado por el mdulo de Despacho Econmico.
En lo que respecta a la poltica de cruce, para proporcionar mayor diver-
sidad en la poblacin, se ha elegido una probabilidad de cruce igual a uno, es
decir, una vez que dos individuos se han elegidos para ser padres siempre se
cruzan. Los individuos hijos se obtienen uniendo los trozos resultantes de una
particin aleatoria de cada la de los individuos padres como muestra la gura
7.8. Tambin se puede aplicar el mismo procedimiento pero partiendo aleato-
riamente las columnas (gura 7.9). Este operador cruce es un caso particular
del operador cruce multipunto. Como las las estn asociadas a las horas del
horizonte de programacin, la primera aproximacin conduce a infactibilidad
de los nuevos individuos con respecto a las restricciones de tiempo mnimo
de parada y funcionamiento (7.12) y (7.13), mientras que la segunda tiene un
efecto ms acusado en las restricciones de demanda (7.23) y de reserva (7.24).
Despus del operador cruce, los hijos son mutados. El operador mutacin
introduce nuevo material gentico en los genes, segn una probabilidad de
mutacin previamente determinada. Se selecciona de manera aleatoria un ge-
nerador y una hora, de un individuo tambin seleccionado aleatoriamente. Se
cambia el estado de ese generador en esa hora (de cero a uno o de uno a cero).
Las guras 7.10 y 7.11 muestran la evolucin del mejor individuo para
el caso test y el caso realista respectivamente. Estos dos individuos son los
mejores que se han obtenido a lo largo de varios experimentos.
174
Aplicacin: Programacin Horaria de Centrales
1 2 3 t 1 2 3 t
1 1
2 2
3 3
. .
. .
. .
g g
1 2 3 t 1 2 3 t
1 1
2 2
3 3
. .
. .
. .
g g
(a)
PADRES
HIJOS
Figura 7.8: Operador de cruce por las
1 2 3 t 1 2 3 t
1 1
2 2
. . . . . .
g g
1 2 3 t 1 2 3 t
1 1
2 2
. . . . . .
g g
(b)
HIJOS
PADRES
Figura 7.9: Operador de cruce por columnas
175
Captulo 7 Aplicacin: Programacin Horaria de Centrales
520
540
560
580
600
620
640
660
680
700
1 101 201 301 401 501 601 701 801 901 10011101
Nmero de generaciones
C
o
s
t
e
(
M
i
l
e
s
d
e
e
u
r
o
s
)
Figura 7.10: Evolucin del mejor individuo para caso test.
4700
4900
5100
5300
5500
5700
5900
6100
6300
6500
1 1701 3401 5101 6801 8501
Nmero de generaciones
C
o
s
t
e
(
M
i
l
e
s
d
e
e
u
r
o
s
)
Figura 7.11: Evolucin del mejor individuo para caso realista.
176
Aplicacin: Programacin Horaria de Centrales
Otras
actividades
23%
Ordenacin
ptima
6%
Construccin
del sistema
10%
Resolucin
del sistema
61%
Figura 7.12: Tiempo de ejecucin segn actividades
Uno de los principales inconvenientes de los Algoritmos Genticos es su
alta carga computacional como se muestra en la tabla 7.5 y en la tabla 7.6.
Para la comparacin de los resultados obtenidos de la aplicacin del mtodo
de optimizacin propuesto con los obtenidos de la aplicacin de un Algoritmo
Gentico se ha hecho la siguiente simplicacin: se han considerado slo cen-
trales trmicas, puesto que considerando la restriccin de acoplamiento entre
embalses, el coste computacional y el tiempo de ejecucin del Algoritmo Ge-
ntico es excesivo, siendo aun ms notable cuando se trata del caso de tamao
realista.
La gura 7.12 muestra los tiempos de las rutinas principales que forman
un algoritmo de Punto Interior.
Como se puede observar, la mayora del tiempo de ejecucin se consume
en resolver el sistema de ecuaciones. Esto es debido al nmero de elementos
de llenado que aparecen, que son causados principalmente por la ecuacin de
acoplamiento entre embalses. Por ejemplo, en el caso de una poblacin de 100
individuos a lo largo de 1000 generaciones se ejecuta 100000 veces el algoritmo
de Punto Interior para resolver cada vez un nuevo problema de Programacin
Horaria de Centrales Elctricas, obteniendo el coste de cada individuo de la
generacin y por tanto su respectiva medida de calidad.
Las tablas 7.5 y 7.6 muestran la mejor solucin conseguida por el Algoritmo
Gentico y por el procedimiento propuesto basado en tcnicas de Punto Inte-
rior, para el caso test y el caso realista, respectivamente. Adems, se muestra
el tiempo de CPU relativo junto con el nmero total de iteraciones.
177
Captulo 7 Aplicacin: Programacin Horaria de Centrales
Funcin Objetivo Tiempo de Iteraciones
(euros) CPU Relativo Externas
PI 512419 1 2
AG 528832 737 1100
Tabla 7.5: Comparacin de resultados para el caso test.
Funcin Objetivo Tiempo de Iteraciones
(euros) CPU Relativo Externas
PI 4670545 1 2
AG 4708849 2800 8500
Tabla 7.6: Comparacin de resultados para el caso realista.
Como se puede observar, la tcnica propuesta es varios rdenes de magnitud
ms rpida que el Algoritmo Gentico y proporciona mejores mnimos locales.
Con esta nueva tcnica, en el caso test, el coste se reduce en 16413.59 euros y
en el caso realista en 38304 euros, lo cual es notable en trminos econmicos.
Las tablas C.1 y C.2 que aparecen en el Apndice C muestran las matrices
de acoplamiento y potencias de salida de las mejores soluciones obtenidas para
el caso test por el nuevo mtodo y el Algoritmo Gentico, respectivamente. Se
puede ver, que la programacin de arranques y paradas y la potencia de salida
para las cinco centrales en las horas 1, 2, 3, 4, 5, 6, 11 y 23 coinciden para los dos
algoritmos. Sin embargo, desde las horas 12 hasta la 22 el Algoritmo Gentico
opta por tener acopladas slo las centrales 1, 2 y 3 mientras que el mtodo
iterativo basado en Punto Interior opta por tener tambin acoplada la central
5 a potencia mnima, lo que hace que la central 2 disminuya su generacin
hasta su potencia mnima para ajustarse a la demanda. Esta misma estrategia
usa el Algoritmo Gentico en las horas 7, 8 y 9 donde todas las centrales
estn acopladas, lo que hace que las centrales 4 y 5 estn a potencia mnima
y la central 3 baje su generacin para ajustarse a la demanda mientras que el
mtodo propuesto tiene acopladas slo las centrales 1, 2 y 3. Por ltimo, una
pareja de centrales se intercambian en la hora 24 (centrales 2 y 3). Se puede
observar (ver Apndice B), que la central 1 es la ms econmica por lo que
siempre est acoplada a potencia mxima.
Las tablas C.3, C.4, C.5, C.6 y C.7 que aparecen en el Apndice C mues-
tran las matrices de acoplamiento y potencias de salida de la mejor solucin
obtenida para el caso realista por el nuevo mtodo.
Las tablas C.8, C.9, C.10, C.11 y C.12 que aparecen en el Apndice C mues-
tran las matrices de acoplamiento y potencias de salida de la mejor solucin
178
Aplicacin: Programacin Horaria de Centrales
obtenida para el caso realista por el Algoritmo Gentico.
7.4. Conclusiones
En este captulo se ha aplicado el algoritmo de optimizacin desarrollado
en el Captulo 6 para la resolucin de problemas no lineales y no convexos
con mltiples mnimos locales, al problema de la PHCT que cumple esas ca-
ractersticas de no linealidad y no convexidad debido a las variables binarias
que aparecen en el modelado del problema y a los costes no lineales. Para la
resolucin de este problema se necesita la prediccin de la demanda que se
obtiene como se describe en el Captulo 5. Se ha descrito brevemente cmo se
resuelven los problemas discretos y continuos que aparecen al aplicar el mtodo
propuesto a este problema, haciendo especial nfasis en las estructuras de las
matrices resultantes.
Para acelerar la ejecucin del algoritmo de Punto Interior las matrices de
los sistemas lineales que hay que resolver se han reordenado para que el n-
mero de elementos de llenado que aparecen al factorizar la matriz sea mnimo.
Esto acelera tanto la ejecucin del mtodo propuesto, ya que ste consiste en
la resolucin de problemas de optimizacin mediante un algoritmo de Punto
Interior de manera iterativa como la ejecucin del AG que obtiene el valor de
la funcin que mide la calidad de cualquier individuo mediante la resolucin de
un problema de optimizacin cuadrtica mediante tcnicas de Punto Interior.
Se han presentado los resultados obtenidos de la aplicacin del mtodo a
dos casos de estudio basados en el parque de generacin espaol, un sistema
test de pequea dimensin y un sistema realista de gran dimensin. Los re-
sultados obtenidos han sido comparados con los obtenidos de la aplicacin de
un Algoritmo Gentico. En ambos casos de estudio el Algoritmo Gentico en-
cuentra mnimos locales peores que el algoritmo basado en tcnicas de Punto
Interior: para el sistema test, el mnimo local encontrado es de 512419 euros
usando la tcnica propuesta y de 528832 euros usando el AG; para el siste-
ma realista, el mnimo local encontrado es de 4670545 euros usando la tcnica
expuesta en esta tesis y de 4708849 euros usando el AG.
179
Captulo 7 Aplicacin: Programacin Horaria de Centrales
180
Captulo 8
Conclusiones y Futuras Lneas de
Investigacin
Como conclusiones generales, se han obtenido avances signicativos en lo
que respecta a tcnicas de prediccin, ya que se ha aplicado un mtodo de
clasicacin, usado hasta ahora principalmente en base de datos espaciales, a
la prediccin de dos series temporales, la demanda y los precios de la energa
elctrica, obteniendo resultados competitivos con las tcnicas de prediccin que
existen en la literatura actual y en algunos casos mejores. En lo que respecta
a la literatura encontrada sobre las tcnicas de prediccin aplicadas a estas
series, ha sido la primera vez que se ha aplicado este mtodo. El objetivo
principal y ltimo de cualquier prediccin de un evento futuro siempre es la
optimizacin, puesto que la optimizacin es un proceso que se nutre de las
predicciones realizadas para obtener algn benecio, como por ejemplo reducir
costes en el caso de los clientes de un servicio o incrementar benecios en el
caso de una empresa. De esta forma, el obtener una prediccin simplemente
proporciona ayuda para elaborar las estrategias necesarias y las decisiones
adecuadas siempre con vistas a optimizar algn objetivo. En el caso de los
precios de la energa en el mercado elctrico, una vez obtenida la prediccin,
las compaas elctricas deben determinar la programacin de generacin de
energa horaria para maximizar el benecio obtenido por la venta de energa en
el mercado y en el caso de la demanda de energa elctrica, una vez obtenida la
prediccin, las empresas elctricas deben planicar la produccin de energa de
las centrales elctricas de manera que se satisfaga la demanda predicha a coste
mnimo. De igual forma, uno de los principales resultados obtenidos dentro de
esta tesis ha sido el desarrollo de un algoritmo de optimizacin para problemas
no lineales no convexos, potente, exible, simple y rpido comparado con las
tcnicas que se usan en la literatura para resolver este tipo de problemas, con la
181
Captulo 8 Conclusiones y Futuras Lneas de Investigacin
principal ventaja ante stas que recorre una trayectoria de mnimos locales cada
vez mejores sin quedar atrapado en el primer mnimo local que se encuentre.
Adems este algoritmo se puede aplicar a cualquier problema de optimizacin
que presente esas caractersticas en cualquier rea cientca/tcnica. En el
campo de la Ingeniera Elctrica ha demostrado ser una herramienta potente
y competitiva con el software comercial existente.
8.1. Prediccin
Las conclusiones ms relevantes en el campo de la prediccin de series
temporales son detalladas a continuacin:
Se ha presentado un algoritmo basado en tcnicas de clasicacin y re-
conocimiento de patrones para la prediccin de series temporales. Estas
tcnicas de reconocimiento de patrones estn basadas en el concepto de
vecindad, por tanto la eleccin de la mtrica que determina el concepto
de vecino ha sido importante en las predicciones realizadas. Debido a
esto, se han experimentado con dos distancias: la distancia Eucldea y la
distancia Manhattan. En lo que respecta a este mtodo, cuando se rea-
liza la prediccin se necesita saber cuntos ejemplos usar de manera que
la prediccin sea ptima. El nmero ptimo de vecinos usados en la pre-
diccin ha sido determinado minimizando los distintos tipos de errores
que se comenten en la prediccin sobre un conjunto de entrenamiento.
Tambin se ha aplicado un mtodo, el mtodo de los falsos vecinos ms
cercanos, para determinar de una manera ptima el nmero de atributos
necesarios para que dos puntos vecinos en el pasado sigan siendo vecinos
en el futuro, lo cual asegura que el error cometido en la prediccin sea
sucientemente pequeo. Por ltimo, se ha analizado de forma heursti-
ca cul es el mnimo error que se puede cometer al predecir usando este
mtodo.
El mtodo de prediccin desarrollado ha sido aplicado a la prediccin
de dos series temporales reales: la demanda de energa elctrica en un
entorno centralizado y los precios de la energa del Mercado Elctrico
Espaol en un entorno liberalizado. El mtodo da lugar a unos errores
de prediccin mucho mayores en el caso de la prediccin de los precios
que en el caso de la prediccin de la demanda, lo cual permite cuestio-
nar el funcionamiento del Mercado Elctrico Espaol. Debido a esto, se
ha establecido una comparacin cualitativa entre el comportamiento de
182
Conclusiones y Futuras Lneas de Investigacin
ambas series que justican la diferencia entre los errores de la prediccin
de ambas series.
Los resultados obtenidos de la aplicacin de la tcnica desarrollada a la
demanda de energa elctrica, han sido comparados con los obtenidos de
la aplicacin de un rbol de regresin obtenido con el algoritmo M5.
Se han obtenido resultados mejores con el mtodo propuesto en cuanto
a aproximacin se reere, aunque los rboles de regresin presentan la
ventaja de obtener modelos cualitativos del sistema.
Se ha desarrollado una red neuronal articial para la prediccin de los
precios de la energa, ya que actualmente son las tcnicas mas utilizadas
en la literatura para la prediccin de series temporales no lineales. Los
resultados obtenidos de la aplicacin de la red neuronal a los precios de
la energa han sido comparados con los obtenidos de la aplicacin de
la tcnica propuesta, revelando sta ltima unos errores de prediccin
menores sin necesitar un elevado tiempo de aprendizaje.
8.2. Optimizacin
En lo que respecta a optimizacin se han obtenido las conclusiones siguien-
tes:
Se ha desarrollado un algoritmo para la resolucin de problemas de opti-
mizacin no lineales no convexos basado en tcnicas de Punto Interior,
que resuelve de manera satisfactoria, eciente y robusta este tipo de
problemas. Teniendo en cuenta que estos problemas presentan mltiples
mnimos locales y que la principal desventaja de los algoritmos existentes
en la literatura para resolver este tipo de problemas, es que explotan tc-
nicas de bsqueda local, encontrando un ptimo local que puede distar
del mnimo global, se ha mejorado esta desventaja obteniendo al me-
nos una sucesin de mnimos locales cada vez mejores que tienden al
mnimo global. Este algoritmo se valida con dos ejemplos tutoriales de
pequea dimensin.
El algoritmo desarrollado para problemas no lineales no convexos se ha
aplicado al problema de la Programacin Horaria de Centrales Trmicas
que cumple esas caractersticas de no linealidad y no convexidad, debi-
do principalmente a las variables discretas que modelan los arranques y
183
Captulo 8 Conclusiones y Futuras Lneas de Investigacin
paradas de las centrales. Para la resolucin de este problema se ha nece-
sitado primero una prediccin de la demanda, que se ha obtenido como
se ha descrito en la primera parte de esta tesis.
Se ha desarrollado un algoritmo gentico para la resolucin del proble-
ma de la Programacin Horaria de Centrales Trmicas para establecer
una comparacin con el mtodo propuesto en esta tesis. Este problema
es relevante tanto para el operador de un sistema de energa elctrica
como para las compaas de generacin. La programacin horaria es un
problema de optimizacin no lineal, entero-mixto, combinatorio y, para
sistemas de tamao realista, de gran dimensin. Estas caractersticas ha-
cen que no haya ningn mtodo que sea capaz de obtener su solucin
exacta. Los algoritmos genticos son tcnicas de resolucin que pueden
modelar cualquier tipo de restriccin y cualquier no linealidad o no con-
vexidad, por lo que son buenos candidatos para obtener la solucin de
este problema. Los resultados obtenidos de la aplicacin del algoritmo
propuesto a dos casos de estudio basados en el parque de generacin es-
paol, un sistema test de pequea dimensin y un sistema realista de
gran dimensin, han sido comparados con los obtenidos de la aplicacin
del Algoritmo Gentico. El nuevo mtodo desarrollado en esta tesis en-
cuentra un mejor mnimo local que el mnimo local encontrado por el
Algoritmo Gentico y adems con menor coste computacional.
8.3. Futuras lneas de investigacin
A partir del anlisis de los resultados presentados en esta tesis, se pueden
sugerir las siguientes lneas futuras de trabajo:
8.3.1. Prediccin
Inclusin de variables externas, que inuyan en el comportamiento de la
serie temporal, en el modelo de prediccin. Por ejemplo, en la serie tem-
poral formada por la demanda se puede incluir la temperatura y en la
serie temporal formada por los precios se puede incluir la demanda, pues-
to que parece lgico pensar que sta en parte explica el comportamiento
de los precios [131].
Experimentar con otras distancias para el clculo de los vecinos ms
cercanos. En esta tesis se han presentado los resultados obtenidos en lo
que respecta a la prediccin de los precios y la demanda usando dos
184
Conclusiones y Futuras Lneas de Investigacin
distancias: la distancia Eucldea y la distancia Manhattan. Tambin se
han publicado algunos resultados, no incluidos en esta tesis, en los que se
ha usado la distancia Eucldea ponderada por unos pesos los cuales son
determinados mediante un Algoritmo Gentico. Se propone experimentar
con el uso de la distancia Eucldea ponderada, donde los pesos sean
determinados mediante un anlisis de correlacin.
Experimentar con otras alternativas para proporcionar factores de peso
a los vecinos, una vez calculados stos con la distancia elegida. En esta
tesis se han calculado estos pesos segn la ecuacin (8.1).
j
=
_
d
k
d
j
d
k
d
1
d
k
= d
1
1 d
k
= d
1
(8.1)
Existen otras alternativas como por ejemplo:
j
=
1
d
j
(8.2)
Clasicacin de los tipos de vecinos, as para el clculo del vecino en lugar
de recorrer toda la base de datos slo se tendra que recorrer los vecinos
del tipo correspondiente al da que se quiera predecir. Esto mejora el
coste computacional del mtodo propuesto basado en los vecinos ms
cercanos.
Aplicacin de la tcnica de prediccin de series temporales desarrollada
a la prediccin de la generacin y el consumo en redes de distribucin,
contemplando especialmente la generacin mediante fuentes de energas
alternativas.
8.3.2. Optimizacin
Automatizacin del ajuste de los parmetros que afectan a la convergen-
cia de los mtodos de Punto Interior mediante algn algoritmo evolutivo
adecuado.
Nuevas estrategias para la inicializacin de los subproblemas continuos
y discretos que aparecen en el mtodo de optimizacin descrito en esta
tesis y nuevas estrategias para la actualizacin de las cotas superiores de
la funcin objetivo en ambos subproblemas.
185
Captulo 8 Conclusiones y Futuras Lneas de Investigacin
Anlisis terico del mtodo de optimizacin que se ha propuesto en esta
tesis, obteniendo propiedades tericas sobre la convergencia y si fuera
posible obteniendo una demostracin terica de la convergencia de la
sucesin decreciente de mnimos locales hacia el mnimo global.
Seguir validando el mtodo de optimizacin propuesto. Para ello se puede
aplicar a otros problemas reales que cumplan las caractersticas de no
linealidad y no convexidad.
Aplicar el mtodo propuesto para obtener mejoras en la planicacin y
operacin de las redes de distribucin de energa elctrica en sistemas
con un alto grado de generacin dispersa.
186
Apndice A
rboles de Regresin
En este apndice se muestran los rboles de regresin y los modelos lineales
obtenidos en las hojas de los rboles mediante el algoritmo M5 con y sin
seleccin de atributos. Los resultados de su aplicacin a la prediccin de la
demanda de energa elctrica han sido usados para establecer una comparacin
con los resultados obtenidos de la aplicacin del mtodo de prediccin basado
en los vecinos ms cercanos, presentado en esta tesis, al mismo problema.
A.1. Sin seleccin de atributos
La gura A.1 muestra el rbol de regresin obtenido tras una ejecucin
del algoritmo M5 sin previa seleccin de atributos. La gura A.2 muestra los
modelos lineales obtenidos en cada hoja del rbol. Para obtener este rbol se
han usado 8280 ejemplos de entrenamiento y el nmero de ejemplos de test
han sido 3072. El nmero de reglas obtenido con este rbol es 151 que han
cometido en la prediccin un 11.4 % de error.
187
Apndice A rboles de Regresin
h24 <= 20300 :
| h20 <= 18300 :
| | h20 <= 16100 :
| | | h20 <= 14600 :
| | | | h12 <= 15500 : LM1 (28/10 %)
| | | | h12 >15500 :
| | | | | h2 <= 17100 :
| | | | | | h9 <= 16500 :
| | | | | | | h5 <= 14300 :
| | | | | | | | h1 <= 13700 : LM2 (2/7.32 %)
| | | | | | | | h1 >13700 :
| | | | | | | | | h11 <= 15800 : LM3 (3/5.87 %)
| | | | | | | | | h11 >15800 : LM4 (3/3.24 %)
| | | | | | | h5 >14300 : LM5 (8/12 %)
| | | | | | h9 >16500 :
| | | | | | | h24 <= 15200 : LM6 (12/9.11 %)
| | | | | | | h24 >15200 :
| | | | | | | | h2 <= 16500 : LM7 (9/7.92 %)
| | | | | | | | h2 >16500 : LM8 (4/2.2 %)
| | | | | h2 >17100 :
| | | | | | h19 <= 15100 : LM9 (9/9.41 %)
| | | | | | h19 >15100 :
| | | | | | | h21 <= 15800 : LM10 (10/9.14 %)
| | | | | | | h21 >15800 : LM11 (11/11.6 %)
| | | h20 >14600 :
| | | | h15 <= 16600 :
| | | | | h3 <= 16100 :
| | | | | | h4 <= 15300 : LM12 (16/6.28 %)
| | | | | | h4 >15300 :
| | | | | | | h7 <= 16600 :
| | | | | | | | h2 <= 15800 : LM13 (30/21.6 %)
| | | | | | | | h2 >15800 : LM14 (10/12.3 %)
| | | | | | | h7 >16600 :
| | | | | | | | h2 <= 17700 :
| | | | | | | | | h1 <= 16200 : LM15 (3/2.57 %)
| | | | | | | | | h1 >16200 : LM16 (8/2.97 %)
| | | | | | | | h2 >17700 : LM17 (3/8.65 %)
| | | | | h3 >16100 :
| | | | | | h20 <= 15800 : LM18 (151/30 %)
| | | | | | h20 >15800 : LM19 (54/27.8 %)
188
A.1 Sin seleccin de atributos
| | | | h15 >16600 :
| | | | | h24 <= 16100 :
| | | | | | h10 <= 17400 :
| | | | | | | h24 <= 15700 : LM20 (9/2.5 %)
| | | | | | | h24 >15700 : LM21 (4/3.38 %)
| | | | | | h10 >17400 :
| | | | | | | h11 <= 17500 : LM22 (7/6.15 %)
| | | | | | | h11 >17500 : LM23 (4/5.11 %)
| | | | | h24 >16100 :
| | | | | | h12 <= 18400 :
| | | | | | | h21 <= 16400 :
| | | | | | | | h18 <= 16500 : LM24 (4/3.78 %)
| | | | | | | | h18 >16500 : LM25 (11/13 %)
| | | | | | | h21 >16400 : LM26 (15/29.2 %)
| | | | | | h12 >18400 :
| | | | | | | h17 <= 17400 : LM27 (6/5.75 %)
| | | | | | | h17 >17400 :
| | | | | | | | h1 <= 20100 : LM28 (7/31.2 %)
| | | | | | | | h1 >20100 : LM29 (3/23.2 %)
| | h20 >16100 :
| | | h24 <= 17500 :
| | | | h22 <= 17400 :
| | | | | h24 <= 16700 :
| | | | | | h14 <= 17200 :
| | | | | | | h22 <= 16600 :
| | | | | | | | h20 <= 16300 :
| | | | | | | | | h8 <= 15300 : LM30 (14/15.8 %)
| | | | | | | | | h8 >15300 : LM31 (24/12.5 %)
| | | | | | | | h20 >16300 : LM32 (81/16.1 %)
| | | | | | | h22 >16600 : LM33 (79/20.4 %)
| | | | | | h14 >17200 :
| | | | | | | h22 <= 16400 :
| | | | | | | | h1 <= 16900 :
| | | | | | | | | h23 <= 16300 : LM34 (11/3.02 %)
| | | | | | | | | h23 >16300 :
| | | | | | | | | | h11 <= 15600 : LM35 (3/7 %)
| | | | | | | | | | h11 >15600 : LM36 (10/10.3 %)
| | | | | | | | h1 >16900 :
| | | | | | | | | h1 <= 17700 :
| | | | | | | | | | h14 <= 17500 : LM37 (4/5.82 %)
| | | | | | | | | | h14 >17500 : LM38 (10/4.35 %)
189
Apndice A rboles de Regresin
| | | | | | | | | h1 >17700 :
| | | | | | | | | | h2 <= 17700 : LM39 (4/2.91 %)
| | | | | | | | | | h2 >17700 : LM40 (4/3.47 %)
| | | | | | | h22 >16400 :
| | | | | | | | h2 <= 18100 :
| | | | | | | | | h15 <= 17400 : LM41 (10/7.4 %)
| | | | | | | | | h15 >17400 : LM42 (17/9.84 %)
| | | | | | | | h2 >18100 :
| | | | | | | | | h9 <= 18500 :
| | | | | | | | | | h2 <= 18100 : LM43 (3/2.15 %)
| | | | | | | | | | h2 >18100 : LM44 (7/3.96 %)
| | | | | | | | | h9 >18500 : LM45 (5/3.58 %)
| | | | | h24 >16700 :
| | | | | | h17 <= 15800 :
| | | | | | | h24 <= 17300 :
| | | | | | | | h14 <= 16500 : LM46 (10/6 %)
| | | | | | | | h14 >16500 : LM47 (19/9.89 %)
| | | | | | | h24 >17300 : LM48 (17/6.41 %)
| | | | | | h17 >15800 :
| | | | | | | h20 <= 16800 :
| | | | | | | | h23 <= 16500 : LM49 (15/7.54 %)
| | | | | | | | h23 >16500 : LM50 (21/23.7 %)
| | | | | | | h20 >16800 :
| | | | | | | | h18 <= 17300 :
| | | | | | | | | h1 <= 18000 :
| | | | | | | | | | h9 <= 18200 :
| | | | | | | | | | | h7 <= 17000 :
| | | | | | | | | | | | h2 <= 16200 :
| | | | | | | | | | | | | h12 <= 15700 : LM51 (3/4.29 %)
| | | | | | | | | | | | | h12 >15700 : LM52 (6/12.8 %)
| | | | | | | | | | | | h2 >16200 : LM53 (12/10.9 %)
| | | | | | | | | | | h7 >17000 :
| | | | | | | | | | | | h4 <= 17700 : LM54 (12/5.9 %)
| | | | | | | | | | | | h4 >17700 : LM55 (8/4.98 %)
| | | | | | | | | | h9 >18200 : LM56 (11/24.1 %)
| | | | | | | | | h1 >18000 :
| | | | | | | | | | h14 <= 17300 : LM57 (5/6.81 %)
| | | | | | | | | | h14 >17300 :
| | | | | | | | | | | h11 <= 18500 : LM58 (3/2.82 %)
| | | | | | | | | | | h11 >18500 :
| | | | | | | | | | | | h1 <= 18700 : LM59 (6/2.52 %)
190
A.1 Sin seleccin de atributos
| | | | | | | | | | | | h1 >18700 : LM60 (3/4.49 %)
| | | | | | | | h18 >17300 :
| | | | | | | | | h2 <= 17400 :
| | | | | | | | | | h23 <= 17000 : LM61 (10/6.99 %)
| | | | | | | | | | h23 >17000 :
| | | | | | | | | | | h2 <= 16400 : LM62 (12/6.31 %)
| | | | | | | | | | | h2 >16400 : LM63 (11/8.62 %)
| | | | | | | | | h2 >17400 : LM64 (27/13.9 %)
| | | | h22 >17400 :
| | | | | h23 <= 18000 : LM65 (161/21.2 %)
| | | | | h23 >18000 : LM66 (63/25.9 %)
| | | h24 >17500 :
| | | | h20 <= 17600 :
| | | | | h18 <= 17500 :
| | | | | | h24 <= 18300 : LM67 (97/18.5 %)
| | | | | | h24 >18300 :
| | | | | | | h12 <= 18700 :
| | | | | | | | h21 <= 17200 :
| | | | | | | | | h12 <= 17700 : LM68 (11/4.25 %)
| | | | | | | | | h12 >17700 : LM69 (3/1.32 %)
| | | | | | | | h21 >17200 :
| | | | | | | | | h15 <= 17400 : LM70 (6/9.26 %)
| | | | | | | | | h15 >17400 : LM71 (5/25.5 %)
| | | | | | | h12 >18700 :
| | | | | | | | h23 <= 19200 :
| | | | | | | | | h24 <= 18600 : LM72 (3/5.2 %)
| | | | | | | | | h24 >18600 : LM73 (9/5.38 %)
| | | | | | | | h23 >19200 : LM74 (4/12.1 %)
| | | | | h18 >17500 : LM75 (167/38 %)
| | | | h20 >17600 :
| | | | | h24 <= 18300 : LM76 (115/17.9 %)
| | | | | h24 >18300 :
| | | | | | h16 <= 18300 : LM77 (70/15.9 %)
| | | | | | h16 >18300 : LM78 (50/30.1 %)
| h20 >18300 :
| | h24 <= 19200 :
| | | h23 <= 19000 :
| | | | h24 <= 18400 :
| | | | | h12 <= 17600 : LM79 (76/32 %)
| | | | | h12 >17600 :
| | | | | | h22 <= 18200 : LM80 (60/20.7 %)
191
Apndice A rboles de Regresin
| | | | | | h22 >18200 : LM81 (121/20.9 %)
| | | | h24 >18400 :
| | | | | h19 <= 19600 : LM82 (187/16.5 %)
| | | | | h19 >19600 :
| | | | | | h20 <= 19400 : LM83 (10/51.2 %)
| | | | | | h20 >19400 :
| | | | | | | h8 <= 20300 :
| | | | | | | | h24 <= 18600 : LM84 (5/7.93 %)
| | | | | | | | h24 >18600 : LM85 (19/12 %)
| | | | | | | h8 >20300 : LM86 (14/22.7 %)
| | | h23 >19000 :
| | | | h22 <= 20100 : LM87 (167/23.9 %)
| | | | h22 >20100 :
| | | | | h13 <= 19400 :
| | | | | | h5 <= 19400 : LM88 (11/35 %)
| | | | | | h5 >19400 : LM89 (6/29.1 %)
| | | | | h13 >19400 :
| | | | | | h16 <= 21500 : LM90 (38/19.2 %)
| | | | | | h16 >21500 : LM91 (16/26 %)
| | h24 >19200 :
| | | h23 <= 20400 : | | | | h2 <= 20700 :
| | | | | h7 <= 20500 : LM92 (327/25.6 %)
| | | | | h7 >20500 :
| | | | | | h16 <= 21400 :
| | | | | | | h16 <= 20400 : LM93 (36/19.2 %)
| | | | | | | h16 >20400 : LM94 (20/26.6 %)
| | | | | | h16 >21400 : LM95 (26/10.8 %)
| | | | h2 >20700 :
| | | | | h20 <= 19800 :
| | | | | | h19 <= 19600 : LM96 (58/12.8 %)
| | | | | | h19 >19600 :
| | | | | | | h17 <= 19700 : LM97 (22/24.6 %)
| | | | | | | h17 >19700 :
| | | | | | | | h4 <= 21200 : LM98 (7/23.4 %)
| | | | | | | | h4 >21200 : LM99 (13/20.4 %)
| | | | | h20 >19800 : LM100 (196/17.3 %)
| | | h23 >20400 :
| | | | h2 <= 20800 :
| | | | | h7 <= 21000 : LM101 (53/33 %)
| | | | | h7 >21000 : LM102 (14/17.1 %)
| | | | h2 >20800 : LM103 (110/23.8 %)
192
A.1 Sin seleccin de atributos
h24 >20300 :
| h24 <= 22700 :
| | h24 <= 21500 :
| | | h24 <= 21000 :
| | | | h23 <= 21000 :
| | | | | h24 <= 20600 :
| | | | | | h19 <= 21100 :
| | | | | | | h2 <= 20200 :
| | | | | | | | h4 <= 19300 : LM104 (39/17.7 %)
| | | | | | | | h4 >19300 : LM105 (30/33.5 %)
| | | | | | | h2 >20200 :
| | | | | | | | h23 <= 20700 : LM106 (153/16.1 %)
| | | | | | | | h23 >20700 : LM107 (43/19.4 %)
| | | | | | h19 >21100 : LM108 (67/29.1 %)
| | | | | h24 >20600 :
| | | | | | h20 <= 20500 :
| | | | | | | h18 <= 20300 : LM109 (73/17.4 %)
| | | | | | | h18 >20300 :
| | | | | | | | h20 <= 19700 : LM110 (15/12.1 %)
| | | | | | | | h20 >19700 :
| | | | | | | | | h21 <= 20700 : LM111 (41/17.9 %)
| | | | | | | | | h21 >20700 : LM112 (11/6.85 %)
| | | | | | h20 >20500 :
| | | | | | | h6 <= 21400 :
| | | | | | | | h18 <= 21200 : LM113 (73/15.5 %)
| | | | | | | | h18 >21200 : LM114 (21/26 %)
| | | | | | | h6 >21400 : LM115 (126/12.9 %)
| | | | h23 >21000 : LM116 (221/35.9 %)
| | | h24 >21000 :
| | | | h21 <= 21600 : LM117 (424/23.4 %)
| | | | h21 >21600 :
| | | | | h13 <= 22800 : LM118 (172/24.9 %)
| | | | | h13 >22800 :
| | | | | | h10 <= 23600 :
| | | | | | | h1 <= 21900 : LM119 (15/31.6 %)
| | | | | | | h1 >21900 : LM120 (23/32.1 %)
| | | | | | h10 >23600 :
| | | | | | | h12 <= 25000 : LM121 (17/11.8 %)
| | | | | | | h12 >25000 : LM122 (5/15 %)
193
Apndice A rboles de Regresin
| | h24 >21500 :
| | | h24 <= 22000 :
| | | | h20 <= 22200 :
| | | | | h18 <= 21900 : LM123 (324/20.2 %)
| | | | | h18 >21900 :
| | | | | | h3 <= 21800 : LM124 (36/29.7 %)
| | | | | | h3 >21800 :
| | | | | | | h13 <= 23200 : LM125 (70/16.7 %)
| | | | | | | h13 >23200 : LM126 (22/21.9 %)
| | | | h20 >22200 :
| | | | | h23 <= 22400 :
| | | | | | h18 <= 22100 :
| | | | | | | h14 <= 22500 : LM127 (30/17.2 %)
| | | | | | | h14 >22500 : LM128 (8/6.82 %)
| | | | | | h18 >22100 : LM129 (113/17 %)
| | | | | h23 >22400 :
| | | | | | h4 <= 21500 : LM130 (8/19.4 %)
| | | | | | h4 >21500 :
| | | | | | | h14 <= 23400 : LM131 (22/13.7 %)
| | | | | | | h14 >23400 :
| | | | | | | | h21 <= 22500 : LM132 (3/8.49 %)
| | | | | | | | h21 >22500 :
| | | | | | | | | h21 <= 23100 : LM133 (3/2.01 %)
| | | | | | | | | h21 >23100 : LM134 (2/0.932 %)
| | | h24 >22000 :
| | | | h23 <= 22600 :
| | | | | h4 <= 23000 :
| | | | | | h24 <= 22400 : LM135 (312/24.1 %)
| | | | | | h24 >22400 :
| | | | | | | h7 <= 22500 :
| | | | | | | | h23 <= 21700 : LM136 (20/15.3 %)
| | | | | | | | h23 >21700 : LM137 (78/25.5 %)
| | | | | | | h7 >22500 : LM138 (29/29.6 %)
| | | | | h4 >23000 : LM139 (194/16 %)
| | | | h23 >22600 :
| | | | | h11 <= 22100 :
| | | | | | h14 <= 20800 :
| | | | | | | h14 <= 19900 :
| | | | | | | | h2 <= 22200 : LM140 (2/2.63 %)
| | | | | | | | h2 >22200 : LM141 (3/5.07 %)
194
A.1 Sin seleccin de atributos
| | | | | | | h14 >19900 :
| | | | | | | | h19 <= 22000 : LM142 (4/9.12 %)
| | | | | | | | h19 >22000 : LM143 (7/17.3 %)
| | | | | | h14 >20800 :
| | | | | | | h19 <= 22800 :
| | | | | | | | h11 <= 21700 : LM144 (26/21.2 %)
| | | | | | | | h11 >21700 :
| | | | | | | | | h20 <= 22300 : LM145 (10/10.1 %)
| | | | | | | | | h20 >22300 : LM146 (9/13.4 %)
| | | | | | | h19 >22800 : LM147 (14/36.9 %)
| | | | | h11 >22100 :
| | | | | | h11 <= 23600 :
| | | | | | | h14 <= 22300 : LM148 (24/26.8 %)
| | | | | | | h14 >22300 : LM149 (95/17.6 %)
| | | | | | h11 >23600 : LM150 (59/24.4 %)
| h24 >22700 : LM151 (1867/26.5 %)
Figura A.1: rbol de regresin con 151 reglas.
195
Apndice A rboles de Regresin
LM1: h25 = 12200 - 1.18e-4h1 - 0.291h2 + 0.0314h3 + 0.173h4 - 0.0657h5 -
0.0565h6 - 0.00389h7 + 0.137h8 - 0.278h9 + 0.00702h10 - 0.298h11 + 0.261h12
+ 0.00379h14 + 0.177h15 - 0.0243h18 - 0.0835h19 + 0.374h20 - 0.575h21 +
0.716h22 + 0.0265h23 - 0.0543h24
LM2: h25 = 2040 - 0.154h1 - 0.0564h2 + 0.0314h3 + 0.296h4 + 0.192h5 -
0.388h6 - 0.00389h7 + 0.168h8 - 0.267h9 + 0.00702h10 + 0.413h11 + 0.144h12
+ 0.00379h14 + 0.108h15 - 0.0243h18 - 0.0475h19 + 0.602h20 - 0.171h21 +
0.192h22 + 0.0265h23 - 0.154h24
LM3: h25 = 2670 - 0.154h1 - 0.0564h2 + 0.0314h3 + 0.296h4 + 0.192h5 -
0.388h6 - 0.00389h7 + 0.168h8 - 0.267h9 + 0.00702h10 + 0.371h11 + 0.144h12
+ 0.00379h14 + 0.108h15 - 0.0243h18 - 0.0475h19 + 0.602h20 - 0.171h21 +
0.192h22 + 0.0265h23 - 0.154h24
LM4: h25 = 2670 - 0.154h1 - 0.0564h2 + 0.0314h3 + 0.296h4 + 0.192h5 -
0.388h6 - 0.00389h7 + 0.168h8 - 0.267h9 + 0.00702h10 + 0.371h11 + 0.144h12
+ 0.00379h14 + 0.108h15 - 0.0243h18 - 0.0475h19 + 0.602h20 - 0.171h21 +
0.192h22 + 0.0265h23 - 0.154h24
LM5: h25 = 5690 - 0.154h1 - 0.0564h2 + 0.0314h3 + 0.296h4 + 0.192h5 -
0.388h6 - 0.00389h7 + 0.168h8 - 0.267h9 + 0.00702h10 + 0.193h11 + 0.144h12
+ 0.00379h14 + 0.108h15 - 0.0243h18 - 0.0475h19 + 0.602h20 - 0.171h21 +
0.192h22 + 0.0265h23 - 0.154h24
LM6: h25 = 7530 - 0.128h1 - 0.114h2 + 0.0314h3 + 0.296h4 + 0.0427h5
- 0.0813h6 - 0.00389h7 + 0.168h8 - 0.481h9 + 0.00702h10 - 0.0689h11 +
0.144h12 + 0.00379h14 + 0.108h15 - 0.0243h18 - 0.0475h19 + 0.923h20 -
0.171h21 + 0.192h22 + 0.0265h23 - 0.227h24
LM7: h25 = 9730 - 0.128h1 - 0.0842h2 + 0.0314h3 + 0.296h4 + 0.0174h5
- 0.0813h6 - 0.00389h7 + 0.168h8 - 0.481h9 + 0.00702h10 - 0.0689h11 +
0.144h12 + 0.00379h14 + 0.108h15 - 0.0243h18 - 0.0475h19 + 0.739h20 -
0.171h21 + 0.192h22 + 0.0265h23 - 0.223h24
LM8: h25 = 9700 - 0.128h1 - 0.0842h2 + 0.0314h3 + 0.296h4 + 0.0213h5
- 0.0813h6 - 0.00389h7 + 0.168h8 - 0.481h9 + 0.00702h10 - 0.0689h11 +
0.144h12 + 0.00379h14 + 0.108h15 - 0.0243h18 - 0.0475h19 + 0.739h20 -
0.171h21 + 0.192h22 + 0.0265h23 - 0.223h24
196
A.1 Sin seleccin de atributos
LM9: h25 = 4040 - 0.0504h1 - 0.205h2 + 0.0314h3 + 0.407h4 - 0.0328h5
- 0.0943h6 - 0.00389h7 + 0.312h8 - 0.331h9 + 0.00702h10 - 0.0689h11 +
0.144h12 + 0.00379h14 + 0.108h15 - 0.0243h18 - 0.241h19 + 0.757h20 -
0.189h21 + 0.192h22 + 0.0265h23 - 0.00451h24
LM10: h25 = 4720 - 0.0504h1 - 0.205h2 + 0.0314h3 + 0.386h4 - 0.0328h5
- 0.0943h6 - 0.00389h7 + 0.192h8 - 0.331h9 + 0.00702h10 - 0.0689h11 +
0.144h12 + 0.00379h14 + 0.108h15 - 0.0243h18 - 0.176h19 + 0.781h20 -
0.189h21 + 0.192h22 + 0.0265h23 - 0.00451h24
LM11: h25 = 4910 - 0.0504h1 - 0.205h2 + 0.0314h3 + 0.386h4 - 0.0328h5
- 0.0943h6 - 0.00389h7 + 0.192h8 - 0.331h9 + 0.00702h10 - 0.0689h11 +
0.144h12 + 0.00379h14 + 0.108h15 - 0.0243h18 - 0.176h19 + 0.774h20 -
0.189h21 + 0.192h22 + 0.0265h23 - 0.00451h24
LM12: h25 = 7420 + 0.264h1 - 0.00996h2 + 0.0131h3 - 0.221h4 + 1.48e-4h5
- 0.117h6 - 0.0367h7 - 0.0543h9 + 0.00702h10 + 0.0228h12 + 0.00379h14 +
0.0282h15 + 0.0235h16 - 0.00995h17 - 0.0116h18 + 0.122h19 + 0.375h20 +
0.0911h21 + 0.015h22 + 0.0117h23 + 0.0383h24
LM13: h25 = 4450 + 0.321h1 - 0.176h2 + 0.424h3 - 0.301h4 + 1.48e-
4h5 - 0.129h6 - 0.0367h7 - 0.0543h9 + 0.00702h10 + 0.0228h12 + 0.00379h14
+ 0.0282h15 + 0.0235h16 - 0.00995h17 - 0.0116h18 + 0.207h19 + 0.302h20 +
0.0409h21 + 0.015h22 + 0.0117h23 + 0.0383h24
LM14: h25 = -8250 + 0.418h1 + 0.165h2 + 0.172h3 + 0.028h4 + 1.48e-4h5
- 0.029h6 - 0.0367h7 - 0.0543h9 + 0.00702h10 + 0.0228h12 + 0.00379h14 +
0.0282h15 + 0.0235h16 - 0.00995h17 - 0.0116h18 + 0.292h19 + 0.443h20 +
0.0409h21 + 0.015h22 + 0.0117h23 + 0.0383h24
LM15: h25 = 15200 + 0.478h1 - 0.257h2 + 0.0131h3 - 0.485h4 + 1.48e-4h5 -
0.0527h6 - 0.0367h7 - 0.0543h9 + 0.00702h10 + 0.0228h12 + 0.00379h14 +
0.0282h15 + 0.0235h16 - 0.00995h17 - 0.0116h18 + 0.147h19 + 0.126h20 +
0.0409h21 + 0.015h22 + 0.0117h23 + 0.0383h24
LM16: h25 = 15300 + 0.474h1 - 0.257h2 + 0.0131h3 - 0.485h4 + 1.48e-4h5 -
0.0527h6 - 0.0367h7 - 0.0543h9 + 0.00702h10 + 0.0228h12 + 0.00379h14 +
0.0282h15 + 0.0235h16 - 0.00995h17 - 0.0116h18 + 0.147h19 + 0.126h20 +
0.0409h21 + 0.015h22 + 0.0117h23 + 0.0383h24
197
Apndice A rboles de Regresin
LM17: h25 = 15900 + 0.545h1 - 0.367h2 + 0.0131h3 - 0.485h4 + 1.48e-4h5 -
0.0527h6 - 0.0367h7 - 0.0543h9 + 0.00702h10 + 0.0228h12 + 0.00379h14 +
0.0282h15 + 0.0235h16 - 0.00995h17 - 0.0116h18 + 0.147h19 + 0.126h20 +
0.0409h21 + 0.015h22 + 0.0117h23 + 0.0383h24
LM18: h25 = 9690 + 0.0223h1 - 0.0333h2 + 0.0451h3 + 0.00547h4 +
0.157h5 - 0.0132h6 - 0.0223h7 - 0.245h8 - 0.0446h9 + 0.00702h10 + 0.239h11
+ 0.0228h12 + 0.00379h14 + 0.00504h15 + 0.0206h16 - 0.00995h17 -
0.0116h18 - 0.0116h19 + 0.119h20 - 0.221h21 + 0.159h22 + 0.0117h23 +
0.169h24
LM19: h25 = 12500 + 0.0399h1 - 0.0662h2 + 0.09h3 + 0.00547h4 +
1.48e-4h5 - 0.0318h6 - 0.0223h7 - 0.0446h9 + 0.00702h10 + 0.0228h12 +
0.00379h14 - 0.0275h15 + 0.0368h16 - 0.00995h17 - 0.0116h18 - 0.0116h19 +
0.182h20 - 0.0464h21 + 0.015h22 + 0.0117h23 + 0.077h24
LM20: h25 = 537 - 0.316h1 - 0.00996h2 + 0.0131h3 + 0.143h4 + 1.48e-4h5
- 0.036h7 - 0.0699h9 + 0.00702h10 + 0.309h11 + 0.14h12 + 0.00379h14 +
0.0652h15 - 0.034h17 - 0.0116h18 - 0.0116h19 + 0.0408h20 + 0.0435h22 +
0.0117h23 + 0.652h24
LM21: h25 = -224 - 0.316h1 - 0.00592h2 + 0.0131h3 + 0.143h4 + 1.48e-4h5
- 0.036h7 - 0.0699h9 + 0.00702h10 + 0.309h11 + 0.14h12 + 0.00379h14 +
0.0652h15 - 0.034h17 - 0.0116h18 - 0.0116h19 + 0.0408h20 + 0.0435h22 +
0.0117h23 + 0.698h24
LM22: h25 = -1020 - 0.342h1 - 0.00996h2 + 0.0131h3 + 0.255h4 +
1.48e-4h5 - 0.036h7 - 0.0699h9 + 0.00702h10 + 0.445h11 + 0.14h12 +
0.00379h14 + 0.0652h15 - 0.034h17 - 0.0116h18 - 0.0116h19 + 0.0408h20 +
0.0435h22 + 0.0117h23 + 0.495h24
LM23: h25 = -69.6 - 0.304h1 - 0.00996h2 + 0.0131h3 + 0.153h4 + 1.48e-4h5
- 0.036h7 - 0.0699h9 + 0.00702h10 + 0.463h11 + 0.14h12 + 0.00379h14 +
0.0652h15 - 0.034h17 - 0.0116h18 - 0.0116h19 + 0.0408h20 + 0.0435h22 +
0.0117h23 + 0.495h24
LM24: h25 = 12900 - 0.0863h1 - 0.00996h2 + 0.00483h3 + 0.00547h4
+ 1.48e-4h5 - 0.036h7 - 0.0699h9 + 0.00702h10 - 0.0889h11 + 0.187h12 +
0.00379h14 + 0.0652h15 - 0.034h17 + 0.144h18 - 0.0116h19 + 0.0408h20 -
0.147h21 + 0.0435h22 + 0.0117h23 + 0.196h24
198
A.1 Sin seleccin de atributos
LM25: h25 = 12400 - 0.0863h1 - 0.00996h2 + 0.0131h3 + 0.00547h4 +
0.0244h5 - 0.036h7 - 0.0699h9 + 0.00702h10 - 0.065h11 + 0.187h12 +
0.00379h14 + 0.0652h15 - 0.034h17 + 0.124h18 - 0.0116h19 + 0.0408h20 -
0.147h21 + 0.0435h22 + 0.0117h23 + 0.196h24
LM26: h25 = 13900 - 0.185h1 - 0.00996h2 + 0.0131h3 + 0.00547h4 +
1.48e-4h5 - 0.036h7 - 0.0699h9 + 0.00702h10 + 0.187h12 + 0.00379h14 +
0.0652h15 - 0.034h17 + 0.0717h18 - 0.0116h19 + 0.0408h20 - 0.147h21 +
0.0435h22 + 0.0117h23 + 0.196h24
LM27: h25 = 9260 + 0.0338h1 - 0.00996h2 + 0.0131h3 + 0.00547h4 +
1.48e-4h5 - 0.036h7 - 0.0699h9 + 0.00702h10 + 0.224h12 + 0.00379h14 +
0.0652h15 - 0.034h17 - 0.0116h18 - 0.0116h19 + 0.0408h20 + 0.0435h22 +
0.0117h23 + 0.196h24
LM28: h25 = 9520 + 0.0338h1 - 0.00996h2 + 0.0131h3 - 0.016h4 +
1.48e-4h5 - 0.036h7 - 0.0699h9 + 0.00702h10 + 0.224h12 + 0.00379h14 +
0.0652h15 - 0.034h17 - 0.0116h18 - 0.0116h19 + 0.0408h20 + 0.0435h22 +
0.0117h23 + 0.196h24
LM29: h25 = 9200 + 0.0338h1 - 0.00996h2 + 0.0131h3 + 0.00547h4 +
1.48e-4h5 - 0.036h7 - 0.0699h9 + 0.00702h10 + 0.224h12 + 0.00379h14 +
0.0652h15 - 0.034h17 - 0.0116h18 - 0.0116h19 + 0.0408h20 + 0.0435h22 +
0.0117h23 + 0.196h24
LM30: h25 = 13200 - 1.18e-4h1 + 0.0018h2 + 0.0305h3 - 0.0134h4 -
0.0363h5 + 0.0146h7 - 0.0439h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 +
0.00532h12 + 0.045h13 - 0.00758h14 + 0.00203h15 - 0.0298h16 - 0.0499h18 -
0.0248h19 + 0.143h20 + 0.0649h21 + 0.0282h22 - 0.0376h23 + 0.107h24
LM31: h25 = 14000 - 1.18e-4h1 + 0.0018h2 + 0.0305h3 - 0.0134h4 -
0.0363h5 + 0.0146h7 - 0.035h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 +
0.00532h12 + 0.045h13 - 0.00758h14 + 0.00203h15 - 0.0298h16 - 0.0499h18 -
0.0248h19 + 0.143h20 + 0.0649h21 + 0.0282h22 - 0.103h23 + 0.107h24
LM32: h25 = 12400 - 1.18e-4h1 + 0.0018h2 + 0.0305h3 - 0.0134h4 -
0.0267h5 + 0.0146h7 - 0.00935h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 +
0.00532h12 + 0.0328h13 - 0.00758h14 + 0.00203h15 - 0.0298h16 - 0.0389h18 -
0.0248h19 + 0.103h20 + 0.0649h21 + 0.0282h22 + 0.0204h23 + 0.107h24
199
Apndice A rboles de Regresin
LM33: h25 = -635 - 1.18e-4h1 + 0.0018h2 + 0.153h3 - 0.0188h4 - 0.218h5
+ 0.192h7 - 0.0156h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 + 0.00532h12 -
0.0748h13 - 0.00758h14 + 0.00203h15 - 0.038h16 - 0.0324h18 - 0.0248h19 +
0.0654h20 + 0.314h21 + 0.0282h22 + 0.216h23 + 0.53h24
LM34: h25 = 2470 + 0.0333h1 + 0.222h2 + 0.0273h3 - 5.5e-4h4 - 0.0252h5 +
0.0129h7 + 0.00528h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 + 0.00532h12 +
0.00208h13 - 0.19h14 + 0.00203h15 - 0.0198h16 - 0.00872h18 - 0.0248h19 +
0.0283h20 + 0.0484h21 + 0.152h22 + 0.463h23 + 0.111h24
LM35: h25 = 5590 - 1.18e-4h1 + 0.0891h2 + 0.0273h3 - 5.5e-4h4 -
0.0252h5 + 0.0129h7 + 0.00528h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 +
0.00532h12 + 0.00208h13 - 0.19h14 + 0.00203h15 - 0.0198h16 - 0.00872h18 -
0.0248h19 + 0.0283h20 + 0.0484h21 + 0.152h22 + 0.453h23 + 0.111h24
LM36: h25 = 5570 - 1.18e-4h1 + 0.0891h2 + 0.0273h3 - 5.5e-4h4 -
0.0252h5 + 0.0129h7 + 0.00528h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 +
0.00532h12 + 0.00208h13 - 0.19h14 + 0.00203h15 - 0.0198h16 - 0.00872h18 -
0.0248h19 + 0.0283h20 + 0.0484h21 + 0.152h22 + 0.453h23 + 0.111h24
LM37: h25 = 14800 + 0.126h1 + 0.221h2 + 0.142h3 - 5.5e-4h4 - 0.0252h5 +
0.0129h7 + 0.00528h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 + 0.00532h12 +
0.00208h13 - 0.901h14 - 0.0846h15 - 0.0198h16 - 0.00872h18 - 0.0248h19 +
0.0283h20 + 0.0484h21 + 0.152h22 + 0.335h23 + 0.111h24
LM38: h25 = 12400 + 0.126h1 + 0.221h2 + 0.162h3 - 5.5e-4h4 - 0.0252h5 +
0.0129h7 + 0.00528h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 + 0.00532h12 +
0.00208h13 - 0.822h14 - 0.0483h15 - 0.0198h16 - 0.00872h18 - 0.0248h19 +
0.0283h20 + 0.0484h21 + 0.152h22 + 0.335h23 + 0.111h24
LM39: h25 = 9680 + 0.159h1 + 0.254h2 + 0.172h3 - 5.5e-4h4 - 0.0252h5 +
0.0129h7 + 0.00528h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 + 0.00532h12
+ 0.00208h13 - 0.67h14 - 0.107h15 - 0.0198h16 - 0.00872h18 - 0.0248h19 +
0.0283h20 + 0.0484h21 + 0.152h22 + 0.335h23 + 0.111h24
LM40: h25 = 9360 + 0.175h1 + 0.254h2 + 0.172h3 - 5.5e-4h4 - 0.0252h5 +
0.0129h7 + 0.00528h8 - 0.0177h9 + 0.0139h10 - 0.00642h11 + 0.00532h12
+ 0.00208h13 - 0.67h14 - 0.107h15 - 0.0198h16 - 0.00872h18 - 0.0248h19 +
0.0283h20 + 0.0484h21 + 0.152h22 + 0.335h23 + 0.111h24
200
A.1 Sin seleccin de atributos
LM41: h25 = 10600 - 0.0266h1 + 0.0675h2 + 0.0273h3 - 5.5e-4h4 - 0.0252h5
+ 0.0129h7 + 0.00528h8 + 0.023h9 + 0.0139h10 - 0.00642h11 - 0.0263h12 +
0.00208h13 - 0.0176h14 + 0.00203h15 - 0.0198h16 - 0.00872h18 - 0.0248h19 +
0.0283h20 + 0.0484h21 + 0.16h22 + 0.00699h23 + 0.111h24
LM42: h25 = 9060 - 0.0266h1 + 0.0675h2 + 0.0273h3 - 5.5e-4h4 - 0.0252h5 +
0.0671h7 + 0.00528h8 + 0.023h9 + 0.0139h10 - 0.00642h11 + 0.00532h12 +
0.00208h13 - 0.0176h14 + 0.00203h15 - 0.0198h16 - 0.00872h18 - 0.0248h19 +
0.0283h20 + 0.0484h21 + 0.16h22 + 0.00699h23 + 0.111h24
LM43: h25 = 8140 - 0.0372h1 + 0.0938h2 + 0.0273h3 - 5.5e-4h4 - 0.0252h5 +
0.0129h7 + 0.00528h8 + 0.122h9 + 0.0139h10 - 0.00642h11 + 0.00532h12 +
0.00208h13 - 0.0176h14 + 0.00203h15 - 0.0198h16 - 0.00872h18 - 0.0248h19 +
0.0283h20 + 0.0484h21 + 0.16h22 + 0.00699h23 + 0.111h24
LM44: h25 = 8210 - 0.0372h1 + 0.0938h2 + 0.0273h3 - 5.5e-4h4 - 0.0252h5
- 0.0046h6 + 0.0129h7 + 0.00528h8 + 0.122h9 + 0.0139h10 - 0.00642h11 +
0.00532h12 + 0.00208h13 - 0.0176h14 + 0.00203h15 - 0.0198h16 - 0.00872h18
- 0.0248h19 + 0.0283h20 + 0.0484h21 + 0.16h22 + 0.00699h23 + 0.111h24
LM45: h25 = 8090 - 0.0529h1 + 0.0938h2 + 0.0273h3 - 5.5e-4h4 - 0.0252h5 +
0.0129h7 + 0.00528h8 + 0.143h9 + 0.0139h10 - 0.00642h11 + 0.00532h12 +
0.00208h13 - 0.0176h14 + 0.00203h15 - 0.0198h16 - 0.00872h18 - 0.0248h19 +
0.0283h20 + 0.0484h21 + 0.16h22 + 0.00699h23 + 0.111h24
LM46: h25 = 7750 - 1.18e-4h1 + 0.044h2 + 0.0114h3 - 5.5e-4h4 - 0.00711h5
- 0.0996h7 + 0.0374h8 - 0.0498h9 + 0.0167h10 - 0.0379h11 + 0.08h12 +
0.00208h13 + 0.0406h14 + 0.00203h15 + 0.0352h16 + 0.0416h17 - 0.00872h18
- 0.0268h19 + 0.0854h20 + 0.0211h21 - 0.0343h22 - 0.0355h23 + 0.433h24
LM47: h25 = 8450 - 1.18e-4h1 + 0.044h2 - 0.0158h3 - 5.5e-4h4 - 0.00711h5
- 0.0996h7 + 0.0374h8 - 0.0498h9 + 0.0167h10 - 0.0379h11 + 0.08h12 +
0.00208h13 + 0.0303h14 + 0.00203h15 + 0.0352h16 + 0.0416h17 - 0.00872h18
- 0.0268h19 + 0.0854h20 + 0.0211h21 - 0.0343h22 - 0.0355h23 + 0.433h24
LM48: h25 = 5400 - 1.18e-4h1 + 0.044h2 + 0.0114h3 - 5.5e-4h4 - 0.00711h5
- 0.0996h7 + 0.0374h8 - 0.0498h9 + 0.0167h10 - 0.0379h11 + 0.08h12 +
0.00208h13 + 0.00179h14 + 0.00203h15 + 0.0352h16 + 0.18h17 - 0.00872h18
- 0.0268h19 + 0.0854h20 + 0.0211h21 - 0.0533h22 - 0.0355h23 + 0.517h24
201
Apndice A rboles de Regresin
LM49: h25 = 7440 - 1.18e-4h1 + 0.0161h2 + 0.0833h3 - 5.5e-4h4 - 0.00711h5
- 0.128h7 + 0.0162h8 - 0.223h9 + 0.0167h10 - 0.06h11 + 0.168h12 - 0.0287h13
+ 0.00179h14 + 0.00203h15 + 0.0542h16 + 0.102h17 - 0.00872h18 - 0.0268h19
+ 0.15h20 + 0.0211h21 + 0.0163h22 - 0.0602h23 + 0.455h24
LM50: h25 = 14700 - 0.142h1 + 0.0161h2 + 0.434h3 - 5.5e-4h4 - 0.00711h5 -
0.128h7 + 0.0162h8 - 0.654h9 + 0.0167h10 - 0.06h11 + 0.168h12 - 0.0287h13
+ 0.00179h14 + 0.00203h15 + 0.0542h16 + 0.075h17 - 0.00872h18 - 0.0268h19
+ 0.15h20 + 0.0211h21 + 0.0163h22 - 0.0602h23 + 0.272h24
LM51: h25 = 11800 + 0.0332h1 + 0.0408h2 + 0.0543h3 - 0.036h4 -
0.00711h5 + 0.0533h6 - 0.12h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 -
0.0329h11 + 0.206h12 - 0.00882h13 - 0.063h14 + 0.00203h15 + 0.00286h16 -
0.0294h17 - 0.00872h18 - 0.0268h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 -
0.0261h23 + 0.171h24
LM52: h25 = 11900 + 0.0332h1 + 0.0338h2 + 0.0543h3 - 0.036h4 -
0.00711h5 + 0.0533h6 - 0.12h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 -
0.0329h11 + 0.206h12 - 0.00882h13 - 0.063h14 + 0.00203h15 + 0.00286h16 -
0.0294h17 - 0.00872h18 - 0.0268h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 -
0.0261h23 + 0.171h24
LM53: h25 = 10700 + 0.0332h1 - 0.00799h2 + 0.0543h3 - 0.036h4 +
0.0999h5 + 0.0533h6 - 0.12h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 - 0.0329h11
+ 0.206h12 - 0.00882h13 - 0.063h14 + 0.00203h15 + 0.00286h16 - 0.0294h17
- 0.00872h18 - 0.0268h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 - 0.0261h23
+ 0.171h24
LM54: h25 = 13400 + 0.0322h1 - 0.00799h2 + 0.0543h3 - 0.0713h4 -
0.00711h5 + 0.0854h6 - 0.12h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 -
0.0329h11 + 0.207h12 - 0.00882h13 - 0.063h14 + 0.00203h15 + 0.00286h16 -
0.0294h17 - 0.00872h18 - 0.0268h19 + 0.0466h20 + 0.0211h21 + 0.0163h22 -
0.0261h23 + 0.171h24
LM55: h25 = 13300 + 0.0322h1 - 0.00799h2 + 0.0543h3 - 0.0775h4 -
0.00711h5 + 0.0548h6 - 0.12h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 -
0.0329h11 + 0.207h12 - 0.00882h13 - 0.063h14 + 0.00203h15 + 0.00286h16 -
0.0294h17 - 0.00872h18 - 0.0268h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 -
0.0261h23 + 0.171h24
202
A.1 Sin seleccin de atributos
LM56: h25 = 7390 + 0.0691h1 - 0.00799h2 + 0.0543h3 - 0.036h4 - 0.00711h5 -
0.12h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 - 0.0329h11 + 0.176h12 + 0.325h13
- 0.063h14 + 0.00203h15 + 0.00286h16 - 0.0294h17 - 0.00872h18 - 0.0268h19
+ 0.0838h20 + 0.0211h21 + 0.0163h22 - 0.0261h23 + 0.171h24
LM57: h25 = 13800 + 0.107h1 - 0.00799h2 + 0.0543h3 - 0.036h4 - 0.00711h5
- 0.177h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 - 0.0329h11 + 0.25h12 -
0.00882h13 - 0.134h14 + 0.00203h15 + 0.00286h16 - 0.0294h17 - 0.00872h18 -
0.0268h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 - 0.0261h23 + 0.171h24
LM58: h25 = 13900 + 0.0529h1 - 0.00799h2 + 0.0543h3 - 0.036h4 -
0.00711h5 - 0.177h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 + 0.0111h11 +
0.25h12 - 0.00882h13 - 0.134h14 + 0.00203h15 + 0.00286h16 - 0.0294h17 -
0.00872h18 - 0.0268h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 - 0.0261h23 +
0.171h24
LM59: h25 = 14100 + 0.0533h1 - 0.00799h2 + 0.0543h3 - 0.036h4 -
0.00711h5 - 0.177h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 + 7.48e-5h11 +
0.25h12 - 0.00882h13 - 0.134h14 + 0.00203h15 + 0.00286h16 - 0.0294h17 -
0.00872h18 - 0.0268h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 - 0.0261h23 +
0.171h24
LM60: h25 = 14200 + 0.0512h1 - 0.00799h2 + 0.0543h3 - 0.036h4 -
0.00711h5 - 0.177h7 + 0.0162h8 - 0.0468h9 + 0.0167h10 + 7.48e-5h11 +
0.25h12 - 0.00882h13 - 0.134h14 + 0.00203h15 + 0.00286h16 - 0.0294h17 -
0.00872h18 - 0.0268h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 - 0.0261h23 +
0.171h24
LM61: h25 = 9570 + 0.0547h1 - 0.0551h2 + 0.0956h3 - 0.0893h4 -
0.00711h5 + 0.0223h7 - 0.0223h8 - 0.0468h9 + 0.0167h10 - 0.0329h11 +
0.0698h12 - 0.00882h13 + 0.00179h14 + 0.00203h15 + 6.24e-5h16 - 0.0294h17
- 0.00872h18 + 0.0267h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 + 0.164h23
+ 0.171h24
LM62: h25 = 10300 + 0.0547h1 - 0.0551h2 + 0.0956h3 - 0.0893h4 -
0.00711h5 + 0.0223h7 - 0.0223h8 - 0.0468h9 + 0.0167h10 - 0.0329h11 +
0.0698h12 - 0.00882h13 + 0.00179h14 + 0.00203h15 + 6.24e-5h16 - 0.0294h17
- 0.00872h18 + 0.0267h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 + 0.126h23
+ 0.171h24
203
Apndice A rboles de Regresin
LM63: h25 = 11000 + 0.0547h1 - 0.0978h2 + 0.0956h3 - 0.0893h4 - 0.00711h5
+ 0.0223h7 - 0.0223h8 - 0.0468h9 + 0.0167h10 - 0.0329h11 + 0.0698h12 -
0.00882h13 + 0.00179h14 + 0.00203h15 + 6.24e-5h16 - 0.0294h17 - 0.00872h18
+ 0.0267h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 + 0.126h23 + 0.171h24
LM64: h25 = 9860 + 0.0571h1 - 0.0614h2 + 0.101h3 - 0.0963h4 - 0.00711h5
+ 0.0353h7 - 0.0278h8 - 0.0468h9 + 0.0167h10 - 0.0329h11 + 0.194h12 -
0.00882h13 + 0.00179h14 + 0.00203h15 - 0.0606h16 - 0.0294h17 - 0.00872h18
+ 0.0343h19 + 0.0838h20 + 0.0211h21 + 0.0163h22 + 0.0638h23 + 0.171h24
LM65: h25 = 3990 - 1.18e-4h1 - 0.128h2 + 0.00233h3 + 0.122h4 +
1.48e-4h5 - 0.0042h7 + 0.264h8 - 0.264h9 + 0.00552h10 - 0.00445h11 +
0.00532h12 + 0.00447h13 + 0.125h14 + 0.00203h15 - 0.138h16 - 0.0131h18 -
0.405h19 + 0.483h20 + 0.0133h21 + 0.49h22 - 0.202h23 + 0.398h24
LM66: h25 = 7570 - 1.18e-4h1 + 0.0018h2 + 0.00233h3 - 5.5e-4h4 +
1.48e-4h5 - 0.0042h7 + 0.0361h8 - 0.0141h9 + 0.00552h10 - 0.00445h11 +
0.00532h12 + 0.00447h13 + 0.00179h14 + 0.00203h15 - 0.0258h16 - 0.0131h18
- 0.0814h19 + 0.0808h20 + 0.0133h21 + 0.125h22 + 0.00994h23 + 0.463h24
LM67: h25 = 4850 - 1.18e-4h1 + 0.00621h2 + 0.00233h3 - 5.5e-4h4 +
1.48e-4h5 + 0.0555h6 - 0.023h7 + 0.0017h8 - 0.123h9 + 0.0129h10 + 0.059h12
- 0.0118h13 + 0.0177h14 + 0.171h15 - 0.018h16 - 0.0145h17 - 0.0119h18 -
0.0247h19 + 0.0482h20 + 0.00274h21 - 0.0305h22 - 0.0184h23 + 0.626h24
LM68: h25 = 5740 - 1.18e-4h1 + 0.00621h2 + 0.00233h3 - 5.5e-4h4 +
0.0166h5 - 0.0641h7 + 0.0017h8 - 0.0463h9 + 0.0129h10 + 0.206h12 -
0.0118h13 + 0.0337h14 + 0.152h15 - 0.018h16 - 0.0145h17 - 0.0119h18 -
0.0247h19 + 0.0482h20 - 0.112h21 - 0.0305h22 - 0.0184h23 + 0.558h24
LM69: h25 = 5890 - 1.18e-4h1 + 0.00621h2 + 0.00233h3 - 5.5e-4h4 +
1.48e-4h5 - 0.0641h7 + 0.0017h8 - 0.0463h9 + 0.0129h10 + 0.214h12 -
0.0118h13 + 0.0337h14 + 0.152h15 - 0.018h16 - 0.0145h17 - 0.0119h18 -
0.0247h19 + 0.0482h20 - 0.112h21 - 0.0305h22 - 0.0184h23 + 0.558h24
LM70: h25 = 4140 - 1.18e-4h1 + 0.00621h2 + 0.00233h3 - 5.5e-4h4 +
1.48e-4h5 - 0.0689h7 + 0.0017h8 - 0.0463h9 + 0.0129h10 + 0.188h12 -
0.0118h13 + 0.0337h14 + 0.274h15 - 0.018h16 - 0.0145h17 - 0.0119h18 -
0.0247h19 + 0.0482h20 - 0.112h21 - 0.0305h22 - 0.0184h23 + 0.558h24
204
A.1 Sin seleccin de atributos
LM71: h25 = 4120 - 1.18e-4h1 + 0.00621h2 + 0.00233h3 - 5.5e-4h4 + 1.48e-
4h5 - 0.0689h7 + 0.0017h8 - 0.0463h9 + 0.0129h10 + 0.188h12 - 0.0118h13
+ 0.0337h14 + 0.28h15 - 0.018h16 - 0.0145h17 - 0.0119h18 - 0.0247h19 +
0.0482h20 - 0.112h21 - 0.0305h22 - 0.0184h23 + 0.558h24
LM72: h25 = 4770 - 1.18e-4h1 + 0.00621h2 + 0.00233h3 - 5.5e-4h4 +
1.48e-4h5 - 0.023h7 + 0.0017h8 - 0.0463h9 + 0.0129h10 + 0.221h12 -
0.0118h13 + 0.0337h14 + 0.0433h15 - 0.018h16 - 0.0145h17 - 0.0119h18 -
0.0247h19 + 0.0482h20 - 0.145h21 - 0.0305h22 - 0.0184h23 + 0.724h24
LM73: h25 = 4780 - 1.18e-4h1 + 0.00621h2 + 0.00233h3 - 5.5e-4h4 + 1.48e-
4h5 - 0.023h7 + 0.0017h8 - 0.0463h9 + 0.0129h10 + 0.221h12 - 0.0118h13
+ 0.0337h14 + 0.0433h15 - 0.018h16 - 0.0145h17 - 0.0119h18 - 0.0247h19 +
0.0482h20 - 0.145h21 - 0.0305h22 - 0.0184h23 + 0.724h24
LM74: h25 = 4020 - 1.18e-4h1 + 0.00621h2 + 0.00233h3 - 5.5e-4h4 +
1.48e-4h5 - 0.023h7 + 0.0017h8 - 0.0463h9 + 0.0129h10 + 0.221h12 -
0.0118h13 + 0.0337h14 + 0.0433h15 - 0.018h16 - 0.0145h17 - 0.0119h18 -
0.0247h19 + 0.0482h20 - 0.145h21 - 0.0305h22 - 0.0184h23 + 0.767h24
LM75: h25 = 3180 - 1.18e-4h1 + 0.00621h2 + 0.291h3 - 0.29h4 + 1.48e-4h5
- 0.0211h7 + 0.0017h8 - 0.0143h9 + 0.0129h10 + 0.324h12 - 0.448h13 +
0.00179h14 + 0.508h15 - 0.0161h16 - 0.0122h17 - 0.0119h18 - 0.0247h19 +
0.0482h20 + 0.00274h21 - 0.398h22 - 0.0147h23 + 0.848h24
LM76: h25 = 2490 + 0.00797h1 + 0.0158h2 + 0.105h3 - 0.107h4 +
1.48e-4h5 - 0.0212h7 + 0.0017h8 - 0.0158h9 + 0.0249h10 + 0.0136h12 +
0.00179h14 + 0.0111h15 - 0.124h16 - 0.00824h17 - 0.0136h18 - 0.0606h19 +
0.0544h20 + 0.204h21 - 0.00928h22 + 0.00492h23 + 0.782h24
LM77: h25 = 8140 + 0.0291h1 + 0.0154h2 + 0.00233h3 - 0.0295h4 +
1.48e-4h5 - 0.0208h7 + 0.0017h8 - 0.0158h9 + 0.0245h10 + 0.0136h12 +
0.00179h14 + 0.0455h15 - 0.0345h16 - 0.00794h17 - 0.0136h18 - 0.115h19 +
0.0544h20 + 0.00274h21 - 0.00928h22 - 0.129h23 + 0.74h24
LM78: h25 = 6530 + 0.0358h1 + 0.0154h2 + 0.00233h3 - 0.0351h4 +
1.48e-4h5 - 0.0208h7 + 0.0017h8 - 0.0158h9 + 0.0245h10 + 0.0136h12 +
0.00179h14 + 0.591h15 - 0.334h16 - 0.00794h17 - 0.0136h18 - 0.132h19 +
0.0544h20 + 0.00274h21 - 0.00928h22 + 0.203h23 + 0.264h24
205
Apndice A rboles de Regresin
LM79: h25 = 2960 - 0.0411h1 + 0.0216h2 + 0.176h3 - 0.21h4 - 0.00105h5
+ 0.0358h6 + 0.00628h7 + 0.0269h8 - 0.012h9 - 0.408h10 - 0.0303h11 +
0.0385h12 + 0.00519h14 - 0.00485h15 + 0.3h16 - 0.00135h18 - 0.0945h19 +
0.0517h20 + 0.00248h22 + 0.242h23 + 0.727h24
LM80: h25 = 3080 - 0.026h1 + 0.0916h2 + 0.0094h3 - 0.00987h4 - 0.00105h5
+ 0.0205h6 + 0.00628h7 + 0.037h8 - 0.012h9 - 0.00939h10 - 0.0141h11 +
0.0223h12 + 0.00519h14 - 0.00485h15 + 0.0177h16 - 0.00135h18 - 0.103h19 +
0.0517h20 + 0.0612h22 + 0.328h23 + 0.358h24
LM81: h25 = 4230 - 0.0827h1 + 0.0117h2 + 0.0094h3 - 0.00987h4 - 0.00105h5
+ 0.0205h6 + 0.00628h7 + 0.165h8 - 0.012h9 - 0.00939h10 - 0.0141h11 +
0.0223h12 + 0.00519h14 - 0.00485h15 + 0.0177h16 - 0.00135h18 - 0.35h19 +
0.0517h20 + 0.423h22 + 0.00942h23 + 0.515h24
LM82: h25 = 3190 - 0.0134h1 + 0.00309h2 + 0.0625h3 - 0.00646h4 -
0.00105h5 + 0.00771h6 + 0.00628h7 - 0.0821h9 + 0.00132h10 + 0.00896h12 -
0.0806h14 + 0.0838h15 + 0.00469h16 - 0.00135h18 - 0.0626h19 + 0.294h20 +
0.00248h22 + 8.25e-4h23 + 0.601h24
LM83: h25 = 13900 - 0.0134h1 + 0.00309h2 + 0.0309h3 - 0.0943h4 -
0.00105h5 + 0.00771h6 + 0.00628h7 + 0.141h8 - 0.0125h9 + 0.00132h10 +
0.00896h12 + 0.00519h14 - 0.00485h15 + 0.00469h16 - 0.124h18 - 0.0982h19
+ 0.283h20 + 0.00248h22 - 0.144h23 + 0.234h24
LM84: h25 = 5590 - 0.0134h1 + 0.00309h2 + 0.0309h3 - 0.053h4 - 0.00105h5
+ 0.00771h6 + 0.00628h7 + 0.106h8 - 0.0125h9 + 0.00132h10 + 0.00896h12
+ 0.00519h14 - 0.00485h15 + 0.00469h16 - 0.0902h17 - 0.124h18 - 0.0982h19
+ 0.199h20 + 0.00248h22 + 0.0207h23 + 0.702h24
LM85: h25 = 5980 - 0.0134h1 + 0.00309h2 + 0.0309h3 - 0.053h4 - 0.00105h5
+ 0.00771h6 + 0.00628h7 + 0.106h8 - 0.0125h9 + 0.00132h10 + 0.00896h12
+ 0.00519h14 - 0.00485h15 + 0.00469h16 - 0.0971h18 - 0.0982h19 + 0.199h20
+ 0.00248h22 - 0.0197h23 + 0.604h24
LM86: h25 = 7390 - 0.0134h1 + 0.00309h2 + 0.0309h3 - 0.053h4 - 0.00105h5
+ 0.00771h6 + 0.00628h7 + 0.12h8 - 0.0125h9 + 0.00132h10 + 0.00896h12 +
0.00519h14 - 0.00485h15 + 0.00469h16 - 0.059h18 - 0.0982h19 + 0.199h20 +
0.00248h22 - 0.0774h23 + 0.543h24
206
A.1 Sin seleccin de atributos
LM87: h25 = 9110 - 0.116h1 + 0.00309h2 + 0.137h3 - 0.00209h4 - 0.00105h5
+ 0.00229h6 + 0.028h7 - 0.00887h9 + 0.00132h10 + 7.18e-4h12 + 0.00969h14
- 0.0101h15 + 0.0094h16 - 0.00135h18 - 0.221h19 + 0.0703h20 + 0.196h21 +
0.00248h22 + 0.0364h23 + 0.395h24
LM88: h25 = 7960 - 0.0288h1 - 0.129h2 + 0.00702h3 - 0.00209h4 -
0.00105h5 - 0.1h6 + 0.205h7 - 0.00887h9 + 0.00132h10 + 7.18e-4h12 +
0.162h13 + 0.00969h14 - 0.0101h15 + 0.0094h16 - 0.145h18 - 0.0767h19 +
0.401h20 + 0.00248h22 + 0.0601h23 + 0.23h24
LM89: h25 = 4740 - 0.0288h1 - 0.129h2 + 0.00702h3 - 0.00209h4 - 0.00105h5
- 0.1h6 + 0.353h7 - 0.00887h9 + 0.00132h10 + 7.18e-4h12 + 0.162h13 +
0.00969h14 - 0.0101h15 + 0.0094h16 - 0.145h18 - 0.0767h19 + 0.401h20 +
0.00248h22 + 0.0601h23 + 0.23h24
LM90: h25 = 3550 - 0.0751h1 - 0.0583h2 + 0.00702h3 - 0.00209h4 +
0.0388h5 - 0.0453h6 + 0.12h7 - 0.00887h9 + 0.00132h10 + 7.18e-4h12 +
0.0752h13 + 0.00969h14 - 0.0101h15 + 0.0744h16 - 0.253h18 - 0.0767h19 +
0.634h20 + 0.00248h22 + 0.0601h23 + 0.337h24
LM91: h25 = 7510 - 0.108h1 - 0.0583h2 + 0.00702h3 - 0.00209h4 +
0.0671h5 - 0.0453h6 + 0.12h7 - 0.00887h9 + 0.00132h10 + 7.18e-4h12 +
0.0752h13 + 0.00969h14 - 0.0101h15 + 0.121h16 - 0.146h18 - 0.0767h19 +
0.337h20 + 0.00248h22 + 0.0601h23 + 0.296h24
LM92: h25 = 3440 - 0.00532h1 + 0.0157h2 + 0.0874h3 - 0.103h4 +
0.00103h5 - 8.14e-4h6 + 0.0668h7 - 0.00355h9 + 0.00132h10 + 0.00489h11 -
0.00259h12 + 7.12e-4h14 + 3.51e-4h15 - 0.00135h18 - 0.365h19 + 0.426h20 +
0.00393h22 + 2.11e-5h23 + 0.699h24
LM93: h25 = 7440 - 0.00532h1 + 0.333h2 + 0.0074h3 - 0.332h4 + 0.00103h5
- 8.14e-4h6 + 2.18e-4h7 + 0.149h8 - 0.00355h9 - 0.144h10 + 0.00489h11 +
0.0768h12 - 0.334h14 + 0.238h15 - 0.0943h16 - 0.00135h18 - 0.093h19 +
0.65h20 + 0.00393h22 + 2.11e-5h23 + 0.161h24
LM94: h25 = 14400 - 0.00532h1 + 1.18h2 + 0.0074h3 - 1.11h4 + 0.24h5 -
8.14e-4h6 - 0.34h7 - 0.00355h9 + 0.00132h10 + 0.00489h11 + 0.0768h12 -
0.0757h14 + 3.51e-4h15 - 0.137h16 - 0.00135h18 - 0.093h19 + 0.375h20 +
0.00393h22 + 2.11e-5h23 + 0.161h24
207
Apndice A rboles de Regresin
LM95: h25 = 4840 - 0.00532h1 + 0.22h2 + 0.0074h3 - 0.259h4 + 0.00103h5
+ 0.124h6 + 2.18e-4h7 - 0.00355h9 + 0.00132h10 + 0.00489h11 + 0.135h12
- 0.132h14 + 3.51e-4h15 - 0.00135h18 - 0.093h19 + 0.268h20 + 0.128h22 +
2.11e-5h23 + 0.346h24
LM96: h25 = 2270 - 0.00532h1 + 0.012h2 + 0.00854h3 - 0.0113h4 +
0.00171h5 - 0.0018h6 + 2.18e-4h7 - 0.00355h9 + 0.00132h10 + 0.00579h11 -
0.00329h12 - 0.0114h14 + 3.51e-4h15 + 0.171h17 - 0.0169h18 - 0.123h19 +
0.179h20 + 0.00393h22 + 0.127h23 + 0.558h24
LM97: h25 = 9380 - 0.00532h1 + 0.012h2 + 0.00854h3 - 0.0113h4 + 0.00171h5
- 0.0018h6 + 2.18e-4h7 - 0.00355h9 + 0.00132h10 + 0.00579h11 - 0.00329h12
- 0.0114h14 + 3.51e-4h15 + 0.0188h17 - 0.0169h18 - 0.141h19 + 0.39h20 +
0.00393h22 - 0.00121h23 + 0.28h24
LM98: h25 = 8990 - 0.00532h1 + 0.012h2 + 0.00854h3 - 0.0113h4 +
0.00171h5 - 0.0018h6 + 2.18e-4h7 - 0.00355h9 + 0.00132h10 + 0.00579h11 -
0.00329h12 - 0.0114h14 + 3.51e-4h15 + 0.0188h17 - 0.0169h18 - 0.141h19 +
0.4h20 + 0.00393h22 - 0.00121h23 + 0.28h24
LM99: h25 = 6240 - 0.00532h1 + 0.012h2 + 0.00854h3 - 0.0113h4 +
0.00171h5 - 0.0018h6 + 2.18e-4h7 - 0.00355h9 + 0.00132h10 + 0.00579h11 -
0.00329h12 - 0.0114h14 + 3.51e-4h15 + 0.0188h17 - 0.0169h18 - 0.141h19 +
0.536h20 + 0.00393h22 - 0.00121h23 + 0.28h24
LM100: h25 = 9450 - 0.00532h1 + 0.012h2 + 0.184h3 - 0.132h4 + 0.00171h5
- 0.0018h6 + 2.18e-4h7 - 0.00355h9 + 0.00132h10 + 0.00579h11 - 0.00329h12
- 0.0989h14 + 3.51e-4h15 + 0.26h17 - 0.186h18 - 0.0494h19 + 0.078h20 +
0.00393h22 - 0.00121h23 + 0.463h24
LM101: h25 = 15200 - 0.236h1 + 0.272h2 + 0.113h3 - 0.174h4 - 0.0413h5 +
0.0019h6 + 2.18e-4h7 - 0.0074h9 + 0.00132h10 + 0.00905h11 - 0.00448h12 +
7.12e-4h14 + 3.51e-4h15 - 0.00135h18 - 0.509h19 + 0.666h20 + 0.00868h22 +
0.0808h23 + 0.0627h24
LM102: h25 = 31100 - 1.13h1 + 0.448h2 + 0.253h3 - 0.393h4 - 0.0413h5
+ 0.0019h6 + 2.18e-4h7 - 0.0074h9 - 0.917h10 + 0.00905h11 + 0.786h12 +
7.12e-4h14 + 3.51e-4h15 - 0.00135h18 - 0.114h19 + 0.42h20 + 0.00868h22 +
0.0808h23 + 0.0627h24
208
A.1 Sin seleccin de atributos
LM103: h25 = 7010 - 0.0628h1 + 0.0991h2 + 0.00917h3 - 0.0112h4 - 0.0274h5
+ 0.0019h6 + 0.161h7 - 0.153h9 + 0.00132h10 + 0.00905h11 - 0.00448h12 +
0.125h13 + 7.12e-4h14 + 3.51e-4h15 - 0.143h18 - 0.0895h19 + 0.0995h20 +
0.00868h22 + 0.557h23 + 0.0627h24
LM104: h25 = 18200 - 0.0156h1 + 0.091h2 + 0.00181h3 - 0.00225h4 -
0.0624h5 - 0.00991h6 + 0.00265h7 - 8.52e-4h8 - 0.00699h9 + 9.7e-4h10 +
0.00621h11 + 7.41e-4h12 - 0.0221h14 + 0.0291h15 - 2.23e-4h17 - 0.00966h18 -
0.0223h19 + 0.137h20 - 0.0896h21 + 1.31e-4h22 + 0.00577h23 + 0.0717h24
LM105: h25 = 15500 - 0.0156h1 + 0.101h2 + 0.00181h3 - 0.00225h4 - 0.0723h5
- 0.00991h6 + 0.00265h7 - 8.52e-4h8 - 0.00699h9 + 9.7e-4h10 + 0.00621h11 +
7.41e-4h12 - 0.0221h14 + 0.0291h15 - 2.23e-4h17 - 0.00966h18 - 0.0223h19 +
0.519h20 - 0.102h21 + 1.31e-4h22 - 0.229h23 + 0.0717h24
LM106: h25 = 17400 - 0.00789h1 + 0.0225h2 + 0.00578h3 - 0.00784h4
- 0.00507h5 - 0.00991h6 + 0.00265h7 - 8.52e-4h8 - 0.012h9 + 0.00555h10 +
0.00621h11 + 0.00728h12 - 0.00812h13 - 0.0119h14 + 0.0177h15 + 0.0065h16
- 2.23e-4h17 - 0.00966h18 - 0.0223h19 + 0.0542h20 - 0.0183h21 + 1.31e-4h22
+ 0.00577h23 + 0.13h24
LM107: h25 = 15100 - 0.00789h1 + 0.0225h2 + 0.0133h3 - 0.0184h4 -
0.00507h5 - 0.00991h6 + 0.00265h7 - 8.52e-4h8 - 0.0215h9 + 0.0142h10 +
0.00621h11 + 0.0197h12 - 0.0235h13 - 0.0119h14 + 0.0177h15 + 0.0188h16 -
2.23e-4h17 - 0.00966h18 - 0.0223h19 + 0.0542h20 - 0.0183h21 + 1.31e-4h22 +
0.00577h23 + 0.241h24
LM108: h25 = 12500 - 0.226h1 + 0.38h2 + 0.00181h3 - 0.00225h4 +
9.93e-5h5 - 0.0218h6 + 0.00265h7 - 0.219h8 - 0.00699h9 + 0.235h10 +
0.00621h11 + 7.41e-4h12 - 0.0173h14 + 0.0285h15 - 2.23e-4h17 - 0.298h18 -
0.0464h19 + 0.731h20 - 0.258h21 + 1.31e-4h22 + 0.00577h23 + 0.0717h24
LM109: h25 = 18100 - 0.00282h1 - 0.0875h2 + 0.0433h3 - 0.00936h4 +
0.0064h5 - 0.0115h6 + 0.00265h7 - 0.00708h8 - 0.00677h9 - 0.00531h10 +
0.02h11 + 7.41e-4h12 + 0.00256h15 + 0.0872h16 - 2.23e-4h17 - 0.0334h18 -
0.0119h19 + 0.0206h20 - 0.00354h21 + 1.31e-4h22 + 0.00577h23 + 0.119h24
209
Apndice A rboles de Regresin
LM110: h25 = 16900 + 0.084h1 - 0.173h2 + 0.173h3 - 0.00936h4 + 0.0064h5
- 0.0115h6 + 0.00265h7 - 0.00708h8 - 0.00677h9 - 0.00531h10 + 0.134h11 +
7.41e-4h12 - 0.106h14 + 0.00256h15 - 2.23e-4h17 - 0.0356h18 - 0.0119h19 +
0.0206h20 - 0.00354h21 + 1.31e-4h22 + 0.00577h23 + 0.119h24
LM111: h25 = 22600 - 0.139h1 - 0.0938h2 + 0.243h3 - 0.00936h4 + 0.0064h5
- 0.0115h6 + 0.00265h7 - 0.00708h8 - 0.00677h9 - 0.00531h10 + 0.071h11 +
7.41e-4h12 - 0.248h14 + 0.00256h15 - 2.23e-4h17 - 0.0356h18 - 0.0119h19 +
0.0206h20 - 0.00354h21 + 1.31e-4h22 + 0.00577h23 + 0.119h24
LM112: h25 = 20100 - 0.0651h1 - 0.0938h2 + 0.158h3 - 0.00936h4 +
0.0064h5 - 0.0115h6 + 0.00265h7 - 0.00708h8 - 0.00677h9 - 0.00531h10 +
0.071h11 + 7.41e-4h12 - 0.118h14 + 0.00256h15 - 2.23e-4h17 - 0.0356h18 -
0.0119h19 + 0.0206h20 - 0.00354h21 + 1.31e-4h22 + 0.00577h23 + 0.119h24
LM113: h25 = 21400 - 0.00282h1 + 0.0111h2 + 0.0103h3 - 0.0253h4 +
0.0138h5 - 0.00926h6 + 0.00265h7 - 0.00496h8 - 0.00677h9 - 0.0341h10 +
0.0152h11 + 0.0103h12 + 0.0171h13 + 0.00256h15 - 2.23e-4h17 - 0.0029h18 -
0.151h19 + 0.0206h20 - 0.00354h21 + 1.31e-4h22 + 0.00577h23 + 0.102h24
LM114: h25 = 51100 - 0.194h1 + 0.312h2 + 0.0103h3 - 0.0253h4 +
0.0138h5 - 0.00926h6 + 0.00265h7 - 0.00496h8 - 0.00677h9 - 0.298h10 +
0.0152h11 + 0.0103h12 + 0.0419h13 + 0.00256h15 - 2.23e-4h17 - 0.0029h18 -
0.0119h19 + 0.0206h20 - 0.00354h21 + 1.31e-4h22 + 0.00577h23 - 1.33h24
LM115: h25 = 7780 - 0.00282h1 + 0.0663h2 + 0.0103h3 - 0.0212h4 +
0.0116h5 - 0.00926h6 - 0.105h7 + 0.0895h8 - 0.00677h9 - 0.0123h10 +
0.0152h11 + 0.00816h12 + 0.00256h15 - 2.23e-4h17 - 0.0029h18 - 0.0119h19
+ 0.0206h20 - 0.00354h21 + 1.31e-4h22 + 0.00577h23 + 0.566h24
LM116: h25 = 16800 - 0.167h1 + 0.22h2 + 0.00181h3 - 0.00225h4 +
9.93e-5h5 - 0.249h6 + 0.214h7 - 8.52e-4h8 - 0.188h9 + 9.7e-4h10 + 0.00661h11
+ 7.41e-4h12 + 0.25h14 + 0.00256h15 - 0.262h17 - 0.0029h18 - 0.281h19 +
0.583h20 + 1.31e-4h22 + 0.0106h23 + 0.0617h24
LM117: h25 = 9570 - 0.00607h1 + 0.00844h2 + 0.163h3 - 0.153h4 +
0.127h5 - 0.144h6 + 0.00574h7 - 8.52e-4h8 - 0.106h9 + 9.7e-4h10 +
0.00111h11 + 7.41e-4h12 + 0.0912h15 - 2.23e-4h17 - 0.00827h18 - 0.00377h19
+ 0.0118h20 + 0.00425h22 + 0.00417h23 + 0.55h24
210
A.1 Sin seleccin de atributos
LM118: h25 = 14200 - 0.0328h1 + 0.0394h2 + 0.00977h3 - 0.0095h4 +
9.93e-5h5 - 0.038h6 + 0.103h7 - 8.52e-4h8 - 0.00291h9 + 9.7e-4h10 +
0.00111h11 + 7.41e-4h12 + 0.011h14 + 0.0105h15 - 2.23e-4h17 - 0.216h18
- 0.00377h19 + 0.387h20 + 0.0266h21 + 0.00746h22 + 0.00417h23 + 0.0283h24
LM119: h25 = 9740 - 0.599h1 + 0.752h2 + 0.00977h3 - 0.156h4 +
9.93e-5h5 - 0.0744h6 + 0.0603h7 - 8.52e-4h8 - 0.00291h9 + 9.7e-4h10 +
0.00111h11 + 7.41e-4h12 + 0.681h14 + 0.0105h15 - 0.0847h17 - 0.2h18 -
0.00377h19 + 0.0148h20 + 0.0663h21 + 0.00746h22 + 0.00417h23 + 0.0283h24
LM120: h25 = 16000 - 1.11h1 + 1.28h2 + 0.00977h3 - 0.125h4 + 9.93e-5h5
- 0.0744h6 + 0.0603h7 - 8.52e-4h8 - 0.00291h9 + 9.7e-4h10 + 0.00111h11 +
7.41e-4h12 + 0.324h14 + 0.0105h15 - 0.0847h17 - 0.169h18 - 0.00377h19 +
0.0148h20 + 0.0663h21 + 0.00746h22 + 0.00417h23 + 0.0283h24
LM121: h25 = 15400 - 0.383h1 + 0.409h2 + 0.00977h3 - 0.0095h4 +
9.93e-5h5 - 0.0744h6 + 0.0603h7 - 8.52e-4h8 - 0.00291h9 + 9.7e-4h10 +
0.00111h11 + 0.0638h12 + 0.237h14 + 0.0105h15 - 0.121h17 - 0.0544h18 -
0.00377h19 + 0.0148h20 + 0.0663h21 + 0.00746h22 + 0.00417h23 + 0.0283h24
LM122: h25 = 14600 - 0.383h1 + 0.409h2 + 0.00977h3 - 0.0095h4 +
9.93e-5h5 - 0.0744h6 + 0.0603h7 - 8.52e-4h8 - 0.00291h9 + 9.7e-4h10 +
0.00111h11 + 0.102h12 + 0.237h14 + 0.0105h15 - 0.121h17 - 0.0544h18 -
0.00377h19 + 0.0148h20 + 0.0663h21 + 0.00746h22 + 0.00417h23 + 0.0283h24
LM123: h25 = 4020 - 6.67e-4h1 + 5.6e-4h2 + 0.108h3 - 0.118h4 - 0.089h5
+ 0.0636h6 + 0.00545h7 - 0.00558h8 - 0.0802h9 + 0.176h10 - 0.119h11 +
0.0981h12 - 0.0792h14 + 0.00679h15 - 2.23e-4h17 - 0.0116h18 - 0.00175h19 +
0.101h20 + 1.31e-4h22 + 0.00431h23 + 0.757h24
LM124: h25 = 25800 + 0.0326h1 + 5.6e-4h2 + 0.0757h3 - 0.0709h4 +
9.93e-5h5 + 0.034h6 + 0.00545h7 - 0.00558h8 - 0.0675h9 + 0.0162h10 -
0.00396h11 + 0.0055h12 - 0.0148h14 + 0.0117h15 - 2.23e-4h17 - 0.0854h18 -
0.00175h19 + 0.0105h20 - 0.299h21 - 0.0816h22 + 0.101h23 + 0.127h24
LM125: h25 = 16900 + 0.0152h1 + 5.6e-4h2 + 0.0495h3 - 0.0469h4 +
9.93e-5h5 + 0.0167h6 + 0.139h7 - 0.00558h8 - 0.187h9 + 0.0162h10 -
0.00396h11 + 0.0055h12 + 0.139h13 - 0.0148h14 + 0.0117h15 - 2.23e-4h17 -
0.309h18 - 0.00175h19 + 0.0105h20 - 0.0388h22 + 0.299h23 + 0.127h24
211
Apndice A rboles de Regresin
LM126: h25 = 17700 + 0.0152h1 + 5.6e-4h2 + 0.0495h3 - 0.0469h4 +
9.93e-5h5 + 0.0167h6 + 0.061h7 - 0.00558h8 - 0.116h9 - 0.253h10 + 0.342h11
+ 0.0055h12 - 0.0148h14 + 0.0117h15 - 2.23e-4h17 - 0.05h18 - 0.00175h19 +
0.0105h20 - 0.0388h22 + 0.0504h23 + 0.127h24
LM127: h25 = 17600 - 0.0427h1 + 5.6e-4h2 + 0.0151h3 - 0.0931h4 +
0.0805h5 + 0.00269h6 + 0.0644h7 - 0.078h8 + 0.16h9 + 0.00944h10 -
0.00655h11 + 0.00874h12 - 0.00616h14 + 0.00588h15 - 2.23e-4h17 - 0.0119h18
- 0.00175h19 + 0.0163h20 + 1.31e-4h22 + 0.0084h23 + 0.0746h24
LM128: h25 = 19300 - 0.0829h1 + 5.6e-4h2 + 0.0151h3 - 0.0931h4 +
0.0805h5 + 0.00269h6 + 0.0644h7 - 0.078h8 + 0.117h9 + 0.00944h10 -
0.00655h11 + 0.00874h12 - 0.00616h14 + 0.00588h15 - 2.23e-4h17 - 0.0119h18
- 0.00175h19 + 0.0163h20 + 1.31e-4h22 + 0.0084h23 + 0.0746h24
LM129: h25 = 20100 - 6.67e-4h1 + 5.6e-4h2 + 0.0151h3 - 0.0624h4 + 0.0462h5
+ 0.00269h6 + 0.271h7 - 0.316h8 - 0.00584h9 + 0.00944h10 - 0.00655h11 +
0.00874h12 - 0.00616h14 + 0.00588h15 - 2.23e-4h17 + 0.181h18 - 0.00175h19
- 0.146h20 + 1.31e-4h22 + 0.0084h23 + 0.0746h24
LM130: h25 = 14100 - 6.67e-4h1 + 5.6e-4h2 + 0.0151h3 - 0.0858h4 +
0.0685h5 + 0.00269h6 + 0.00779h7 - 0.21h8 + 0.472h9 + 0.00944h10 -
0.00655h11 + 0.00874h12 - 0.00616h14 + 0.00588h15 - 2.23e-4h17 - 0.0119h18
- 0.00175h19 + 0.0163h20 + 1.31e-4h22 + 0.0084h23 + 0.0746h24
LM131: h25 = 19300 - 6.67e-4h1 + 5.6e-4h2 + 0.0151h3 - 0.0858h4 +
0.0685h5 + 0.00269h6 + 0.00779h7 - 0.112h8 + 0.13h9 + 0.00944h10 -
0.00655h11 + 0.00874h12 - 0.00616h14 + 0.00588h15 - 2.23e-4h17 - 0.0119h18
- 0.00175h19 + 0.0163h20 + 1.31e-4h22 + 0.0084h23 + 0.0746h24
LM132: h25 = 19200 - 6.67e-4h1 + 5.6e-4h2 + 0.0151h3 - 0.0858h4 +
0.0685h5 + 0.00269h6 + 0.00779h7 - 0.112h8 + 0.13h9 + 0.00944h10 -
0.00655h11 + 0.00874h12 - 0.00616h14 + 0.00588h15 - 2.23e-4h17 - 0.0119h18
- 0.00175h19 + 0.0163h20 + 1.31e-4h22 + 0.0084h23 + 0.0746h24
LM133: h25 = 19300 - 6.67e-4h1 + 5.6e-4h2 + 0.0151h3 - 0.0858h4 +
0.0685h5 + 0.00269h6 + 0.00779h7 - 0.112h8 + 0.13h9 + 0.00944h10 -
0.00655h11 + 0.00874h12 - 0.00616h14 + 0.00588h15 - 2.23e-4h17 - 0.0119h18
- 0.00175h19 + 0.0163h20 + 1.31e-4h22 + 0.0084h23 + 0.0746h24
212
A.1 Sin seleccin de atributos
LM134: h25 = 19300 - 6.67e-4h1 + 5.6e-4h2 + 0.0151h3 - 0.0858h4 + 0.0685h5
+ 0.00269h6 + 0.00779h7 - 0.112h8 + 0.13h9 + 0.00944h10 - 0.00655h11 +
0.00874h12 - 0.00616h14 + 0.00588h15 - 2.23e-4h17 - 0.0119h18 - 0.00175h19
+ 0.0163h20 + 1.31e-4h22 + 0.0084h23 + 0.0746h24
LM135: h25 = 20200 - 6.67e-4h1 + 5.6e-4h2 + 0.113h3 - 0.151h4 + 9.93e-5h5
- 6.19e-4h6 + 0.0102h7 - 0.00867h8 + 0.00436h9 - 0.00263h10 - 0.0015h11 +
0.00423h12 - 0.0021h13 - 0.152h14 + 0.196h15 - 2.23e-4h17 - 0.00285h18 -
0.00175h19 + 0.0054h20 - 0.00474h21 + 1.31e-4h22 + 0.00113h23 + 0.0803h24
LM136: h25 = 23300 - 6.67e-4h1 + 5.6e-4h2 + 0.0197h3 - 0.0939h4 +
9.93e-5h5 + 0.0432h6 + 0.0158h7 - 0.0142h8 + 0.0114h9 - 0.0285h10 -
0.052h11 + 0.00423h12 - 0.0021h13 - 0.0165h14 + 0.101h15 - 0.0159h17 -
0.00285h18 - 0.00175h19 + 0.0351h20 - 0.036h21 + 1.31e-4h22 - 0.113h23 +
0.109h24
LM137: h25 = 21400 - 6.67e-4h1 + 5.6e-4h2 + 0.0197h3 - 0.0639h4 + 9.93e-
5h5 + 0.0159h6 + 0.0158h7 - 0.0142h8 + 0.0114h9 - 0.0285h10 - 0.0205h11
+ 0.00423h12 - 0.0021h13 - 0.0165h14 + 0.074h15 - 0.0159h17 - 0.00285h18 -
0.00175h19 + 0.0351h20 - 0.036h21 + 1.31e-4h22 - 0.0419h23 + 0.109h24
LM138: h25 = 1840 - 6.67e-4h1 + 0.496h2 + 0.0197h3 - 0.0669h4 +
9.93e-5h5 - 6.19e-4h6 + 0.0158h7 - 0.0142h8 + 0.0114h9 - 0.059h10 -
0.0015h11 + 0.00423h12 - 0.0021h13 - 0.0165h14 + 0.446h15 - 0.0405h17 -
0.00285h18 - 0.00175h19 + 0.0818h20 - 0.0753h21 + 1.31e-4h22 + 0.00113h23
+ 0.109h24
LM139: h25 = 6280 - 6.67e-4h1 + 5.6e-4h2 + 0.0128h3 - 0.018h4 + 9.93e-5h5
- 6.19e-4h6 + 0.00588h7 - 0.0044h8 - 0.00101h9 + 0.00223h10 - 0.0015h11 +
0.00423h12 - 0.0021h13 - 0.00572h14 + 0.0111h15 - 2.23e-4h17 - 0.00285h18
- 0.00175h19 + 0.0054h20 + 0.0784h21 + 1.31e-4h22 + 0.00113h23 + 0.632h24
LM140: h25 = 7840 - 6.67e-4h1 + 5.6e-4h2 + 0.00986h3 - 0.0413h4 +
9.93e-5h5 - 6.19e-4h6 + 0.00993h7 - 0.2h8 - 0.0395h9 + 0.373h10 - 0.341h11
+ 0.061h12 - 0.054h13 + 1.08h14 - 0.0239h15 - 2.23e-4h17 - 0.00285h18 -
0.248h19 + 0.0054h20 + 0.0306h21 + 1.31e-4h22 + 0.00113h23 + 0.0554h24
213
Apndice A rboles de Regresin
LM141: h25 = 7880 - 6.67e-4h1 + 5.6e-4h2 + 0.00986h3 - 0.0413h4 +
9.93e-5h5 - 6.19e-4h6 + 0.00993h7 - 0.2h8 - 0.0395h9 + 0.373h10 - 0.341h11
+ 0.061h12 - 0.054h13 + 1.08h14 - 0.0239h15 - 2.23e-4h17 - 0.00285h18 -
0.248h19 + 0.0054h20 + 0.0306h21 + 1.31e-4h22 + 0.00113h23 + 0.0554h24
LM142: h25 = 13700 - 6.67e-4h1 + 0.108h2 + 0.00986h3 - 0.0413h4 +
9.93e-5h5 - 6.19e-4h6 + 0.00993h7 - 0.2h8 - 0.0395h9 + 0.373h10 - 0.341h11
+ 0.061h12 - 0.054h13 + 0.923h14 - 0.0239h15 - 2.23e-4h17 - 0.00285h18 -
0.45h19 + 0.0054h20 + 0.0306h21 + 1.31e-4h22 + 0.00113h23 + 0.0554h24
LM143: h25 = 14000 - 6.67e-4h1 + 0.0605h2 + 0.00986h3 - 0.0413h4 +
9.93e-5h5 - 6.19e-4h6 + 0.00993h7 - 0.2h8 - 0.0395h9 + 0.373h10 - 0.341h11
+ 0.061h12 - 0.054h13 + 0.923h14 - 0.0239h15 - 2.23e-4h17 - 0.00285h18 -
0.423h19 + 0.0054h20 + 0.0306h21 + 1.31e-4h22 + 0.00113h23 + 0.0554h24
LM144: h25 = 22600 - 6.67e-4h1 + 5.6e-4h2 + 0.00986h3 - 0.0413h4 -
0.0255h5 - 6.19e-4h6 + 0.00993h7 - 0.171h8 - 0.0395h9 + 0.431h10 - 0.348h11
+ 0.061h12 - 0.054h13 + 0.225h14 - 0.0239h15 - 2.23e-4h17 - 0.00285h18 -
0.134h19 + 0.0054h20 + 0.0306h21 + 1.31e-4h22 + 0.00113h23 + 0.0554h24
LM145: h25 = 24700 - 6.67e-4h1 + 5.6e-4h2 + 0.00986h3 - 0.0413h4 -
0.0308h5 - 6.19e-4h6 + 0.00993h7 - 0.171h8 - 0.0395h9 + 0.352h10 - 0.365h11
+ 0.061h12 - 0.054h13 + 0.225h14 - 0.0239h15 - 2.23e-4h17 - 0.00285h18 -
0.134h19 + 0.0054h20 + 0.0306h21 + 1.31e-4h22 + 0.00113h23 + 0.0554h24
LM146: h25 = 22600 - 6.67e-4h1 + 5.6e-4h2 + 0.00986h3 - 0.0413h4 -
0.0308h5 - 6.19e-4h6 + 0.00993h7 - 0.171h8 - 0.0395h9 + 0.441h10 - 0.365h11
+ 0.061h12 - 0.054h13 + 0.225h14 - 0.0239h15 - 2.23e-4h17 - 0.00285h18 -
0.134h19 + 0.0054h20 + 0.0306h21 + 1.31e-4h22 + 0.00113h23 + 0.0554h24
LM147: h25 = 30400 - 6.67e-4h1 + 0.171h2 + 0.00986h3 - 0.0413h4 +
9.93e-5h5 - 6.19e-4h6 + 0.00993h7 - 0.65h8 - 0.0395h9 + 0.361h10 - 0.369h11
+ 0.061h12 - 0.054h13 + 0.225h14 - 0.0239h15 - 2.23e-4h17 - 0.00285h18 -
0.134h19 + 0.0054h20 + 0.0306h21 + 1.31e-4h22 + 0.00113h23 + 0.0554h24
LM148: h25 = 21200 - 6.67e-4h1 + 5.6e-4h2 + 0.00986h3 - 0.138h4 +
0.0763h5 + 0.0144h6 + 0.00993h7 - 0.00718h8 - 0.0189h9 + 0.0441h10 -
0.0252h11 + 0.0502h12 - 0.0279h13 + 0.101h14 - 0.423h15 + 0.0944h16 -
0.038h17 - 0.00285h18 - 0.0249h19 + 0.0054h20 + 0.0143h21 + 1.31e-4h22 +
0.0706h23 + 0.26h24
214
A.2 Con seleccin de atributos
LM149: h25 = 15400 - 6.67e-4h1 + 5.6e-4h2 + 0.00986h3 - 0.0835h4 +
0.0271h5 + 0.0144h6 + 0.00993h7 - 0.00718h8 - 0.0189h9 + 0.0441h10 -
0.0252h11 + 0.0502h12 - 0.0279h13 + 0.0672h14 - 0.0455h15 + 0.0504h16 -
0.038h17 - 0.00285h18 - 0.0249h19 + 0.0054h20 + 0.0143h21 + 0.0908h22 +
0.0706h23 + 0.128h24
LM150: h25 = 5190 - 6.67e-4h1 + 5.6e-4h2 + 0.00986h3 - 0.196h4 +
9.93e-5h5 + 0.0266h6 + 0.00993h7 - 0.00718h8 - 0.0189h9 + 0.0441h10 -
0.0252h11 + 0.0648h12 - 0.0279h13 + 0.0485h14 - 0.0105h15 + 0.0475h16 -
0.0686h17 - 0.00285h18 - 0.406h19 + 0.0054h20 + 0.453h21 + 1.31e-4h22 +
0.768h23 + 0.0554h24
LM151: h25 = 1230 - 0.0495h1 + 0.0815h3 - 0.163h4 + 0.0619h5 +
0.0426h7 - 3.28e-4h8 - 6.42e-4h9 + 0.0645h10 - 0.0638h11 + 4.76e-4h12 +
0.126h15 - 0.0522h16 - 0.0859h17 - 6.56e-4h18 - 0.0688h19 + 0.158h20 -
0.079h22 + 3.76e-4h23 + 0.971h24
Figura A.2: Modelos lineales en cada hoja del rbol de regresin formado por
151 reglas.
A.2. Con seleccin de atributos
La gura A.3 muestra el rbol de regresin obtenido tras una ejecucin
del algoritmo M5 con previa seleccin de atributos. La gura A.4 muestra los
modelos lineales obtenidos en cada hoja del rbol. Para obtener este rbol se
han usado 8280 ejemplos de entrenamiento y el nmero de ejemplos de test ha
sido 3072. El nmero de reglas obtenido con este rbol es 53 que han cometido
en la prediccin un 11 % de error.
215
Apndice A rboles de Regresin
h24 <= 20300 :
| h20 <= 18300 :
| | h20 <= 16100 :
| | | h20 <= 14600 : LM1 (99/45.6 %)
| | | h20 >14600 : LM2 (345/48.3 %)
| | h20 >16100 :
| | | h24 <= 17500 :
| | | | h23 <= 17500 :
| | | | | h24 <= 16700 :
| | | | | | h23 <= 17000 : LM3 (241/34.3 %)
| | | | | | h23 >17000 : LM4 (74/25.1 %)
| | | | | h24 >16700 : LM5 (252/28.5 %)
| | | | h23 >17500 : LM6 (154/31.9 %)
| | | h24 >17500 :
| | | | h20 <= 17600 :
| | | | | h23 <= 17600 : LM7 (83/18.3 %)
| | | | | h23 >17600 : LM8 (222/50.3 %)
| | | | h20 >17600 :
| | | | | h24 <= 18300 : LM9 (115/21.1 %)
| | | | | h24 >18300 : LM10 (120/33 %)
| h20 >18300 :
| | h24 <= 19200 :
| | | h23 <= 19000 :
| | | | h24 <= 18400 :
| | | | | h23 <= 18200 : LM11 (158/35 %)
| | | | | h23 >18200 : LM12 (99/27.7 %)
| | | | h24 >18400 : LM13 (235/23.5 %)
| | | h23 >19000 : LM14 (238/33.3 %)
| | h24 >19200 :
| | | h23 <= 20400 : LM15 (705/29.6 %)
| | | h23 >20400 : LM16 (177/45.1 %)
h24 >20300 :
| h24 <= 22700 :
| | h24 <= 21500 :
| | | h24 <= 21000 :
| | | | h23 <= 21000 :
| | | | | h24 <= 20600 : LM17 (332/26.4 %)
| | | | | h24 >20600 : LM18 (360/20.9 %)
| | | | h23 >21000 :
| | | | | h20 <= 21700 :
| | | | | | h24 <= 20800 : LM19 (78/27.2 %)
216
A.2 Con seleccin de atributos
| | | | | | h24 >20800:
| | | | | | | h20 <= 21400:
| | | | | | | | h24 <= 20900:
| | | | | | | | | h23 <= 21000 : LM20 (3/36.2 %)
| | | | | | | | | h23 >21000 : LM21 (10/41.9 %)
| | | | | | | | h24 >20900 : LM22 (43/48.7 %)
| | | | | | | h20 >21400 : LM23 (21/22 %)
| | | | | h20 >21700 : LM24 (66/29.7 %)
| | | h24 >21000 :
| | | | h23 <= 21700 : LM25 (524/26.8 %)
| | | | h23 >21700 :
| | | | | h20 <= 22300 : LM26 (82/35.8 %)
| | | | | h20 >22300 : LM27 (50/28.6 %)
| | h24 >21500 :
| | | h24 <= 22000 :
| | | | h20 <= 22200 : LM28 (452/25.2 %)
| | | | h20 >22200 : LM29 (189/23.8 %)
| | | h24 >22000 :
| | | | h23 <= 22600 : LM30 (633/24.5 %)
| | | | h23 >22600 :
| | | | | h23 <= 23200 :
| | | | | | h24 <= 22300:
| | | | | | | h24 <= 22100:
| | | | | | | | h20 <= 22500 : LM31 (6/60.7 %)
| | | | | | | | h20 >22500 : LM32 (8/18.2 %)
| | | | | | | h24 >22100 : LM33 (30/31.7 %)
| | | | | | h24 >22300 : LM34 (156/24.5 %)
| | | | | h23 >23200 : LM35 (53/61.6 %)
| h24 >22700 :
| | h24 <= 24300 :
| | | h24 <= 23400 :
| | | | h24 <= 23100 :
| | | | | h23 <= 23100 : LM36 (292/19.5 %)
| | | | | h23 >23100 :
| | | | | | h24 <= 22800:
| | | | | | | h20 <= 23500 : LM37 (19/37.1 %)
| | | | | | | h20 >23500 : LM38 (9/32.6 %)
| | | | | | h24 >22800 : LM39 (105/27 %)
| | | | h24 >23100 : LM40 (236/30.5 %)
217
Apndice A rboles de Regresin
| | | h24 >23400 :
| | | | h24 <= 23800 :
| | | | | h23 <= 23900 : LM41 (249/24 %)
| | | | | h23 >23900 : LM42 (64/38.1 %)
| | | | h24 >23800 : LM43 (319/25.2 %)
| | h24 >24300 :
| | | h24 <= 25900 :
| | | | h24 <= 24900 :
| | | | | h23 <= 25000 : LM44 (168/26.3 %)
| | | | | h23 >25000 :
| | | | | | h23 <= 25600 : LM45 (34/27 %)
| | | | | | h23 >25600 :
| | | | | | | h23 <= 25700 : LM46 (4/20.5 %)
| | | | | | | h23 >25700 : LM47 (5/23.6 %)
| | | | h24 >24900 :
| | | | | h24 <= 25400 : LM48 (139/26.2 %)
| | | | | h24 >25400 :
| | | | | | h23 <= 26000 : LM49 (71/23 %)
| | | | | | h23 >26000:
| | | | | | | h23 <= 26600:
| | | | | | | | h20 <= 25100 : LM50 (4/25.2 %)
| | | | | | | | h20 >25100 : LM51 (11/12.5 %)
| | | | | | | h23 >26600 : LM52 (4/9.88 %)
| | | h24 >25900 : LM53 (134/24.5 %)
Figura A.3: rbol de regresin con 53 reglas.
218
A.2 Con seleccin de atributos
LM1: h25 = 851 + 0.949h20 + 0.46h23 - 0.43h24
LM2: h25 = 11000 + 0.0526h20 + 0.0124h23 + 0.245h24
LM3: h25 = 12500 + 0.0381h20 + 0.0165h23 + 0.187h24
LM4: h25 = 10400 + 0.0381h20 + 0.03h23 + 0.342h24
LM5: h25 = 5480 + 0.242h20 - 0.103h23 + 0.532h24
LM6: h25 = 1900 + 0.0436h20 + 0.793h23 + 0.0353h24
LM7: h25 = -1600 + 0.0942h20 - 0.0771h23 + 1.07h24
LM8: h25 = 448 + 0.487h20 - 0.844h23 + 1.32h24
LM9: h25 = 3790 + 0.054h20 - 0.0148h23 + 0.751h24
LM10: h25 = 11100 + 0.054h20 - 0.298h23 + 0.636h24
LM11: h25 = 7040 + 0.0162h20 + 0.0448h23 + 0.547h24
LM12: h25 = 15100 + 0.0162h20 + 0.0562h23 + 0.101h24
LM13: h25 = 4870 + 0.14h20 - 0.0954h23 + 0.691h24
LM14: h25 = 3950 + 0.022h20 + 0.497h23 + 0.281h24
LM15: h25 = 3270 + 0.211h20 - 0.11h23 + 0.73h24
LM16: h25 = 5430 + 0.0324h20 + 0.633h23 + 0.053h24
LM17: h25 = 16300 + 0.132h20 - 3.7e-4h23 + 0.0695h24
LM18: h25 = 19100 + 0.00961h20 - 2.85e-6h23 + 0.0669h24
LM19: h25 = 18200 + 0.028h20 + 0.0388h23 + 0.0561h24
LM20: h25 = -1900 + 0.028h20 + 0.964h23 + 0.0561h24
LM21: h25 = 3780 + 0.028h20 + 0.705h23 + 0.0561h24
219
Apndice A rboles de Regresin
LM22: h25 = 18200 + 0.028h20 + 0.0388h23 + 0.0561h24
LM23: h25 = 18200 + 0.028h20 + 0.0388h23 + 0.0561h24
LM24: h25 = 17600 + 0.0453h20 + 0.0721h23 + 0.0561h24
LM25: h25 = 8460 + 0.00792h20 + 0.00313h23 + 0.588h24
LM26: h25 = 23400 + 0.0465h20 + 0.00313h23 - 0.149h24
LM27: h25 = 59700 + 0.0612h20 + 0.00313h23 - 1.85h24
LM28: h25 = 6030 + 0.00692h20 + 9.04e-4h23 + 0.711h24
LM29: h25 = 20000 + 0.0108h20 + 9.04e-4h23 + 0.0773h24
LM30: h25 = 8170 + 0.00479h20 + 9.04e-4h23 + 0.626h24
LM31: h25 = 354000 + 0.00673h20 + 9.04e-4h23 - 15.1h24
LM32: h25 = 217000 + 0.00673h20 + 9.04e-4h23 - 8.84h24
LM33: h25 = 20900 + 0.00673h20 + 9.04e-4h23 + 0.0542h24
LM34: h25 = 21000 + 0.00673h20 + 9.04e-4h23 + 0.0542h24
LM35: h25 = 21000 + 0.00673h20 + 9.04e-4h23 + 0.0542h24
LM36: h25 = 21300 + 0.00209h20 - 4.3e-4h23 + 0.0679h24
LM37: h25 = 21100 + 0.00209h20 - 4.3e-4h23 + 0.0679h24
LM38: h25 = 20300 - 0.273h20 + 0.332h23 + 0.0679h24
LM39: h25 = 21400 + 0.00209h20 - 4.3e-4h23 + 0.0679h24
LM40: h25 = 21100 + 0.00209h20 - 4.3e-4h23 + 0.0894h24
LM41: h25 = 21600 + 0.00209h20 - 4.3e-4h23 + 0.0781h24
LM42: h25 = 46900 + 0.00209h20 - 1.05h23 + 0.0781h24
220
A.2 Con seleccin de atributos
LM43: h25 = 6650 + 0.00209h20 - 4.3e-4h23 + 0.717h24
LM44: h25 = 5820 + 0.0126h20 - 0.0197h23 + 0.765h24
LM45: h25 = 25900 + 0.0126h20 - 0.376h23 + 0.319h24
LM46: h25 = 35100 + 0.0126h20 - 0.747h23 + 0.319h24
LM47: h25 = 29700 + 0.218h20 - 0.747h23 + 0.319h24
LM48: h25 = 20900 + 0.0122h20 - 0.0188h23 + 0.172h24
LM49: h25 = 20600 + 0.0122h20 - 0.0188h23 + 0.194h24
LM50: h25 = 29900 + 0.0122h20 - 0.373h23 + 0.194h24
LM51: h25 = 29900 + 0.0122h20 - 0.373h23 + 0.194h24
LM52: h25 = 48200 + 0.0122h20 - 1.06h23 + 0.194h24
LM53: h25 = 3320 + 0.11h20 - 0.18h23 + 0.942h24
Figura A.4: Modelos lineales en cada hoja del rbol de regresin formado por
53 reglas.
221
Apndice A rboles de Regresin
222
Apndice B
Datos
En este apndice se presentan los datos de entrada correspondientes a los
dos casos de estudio analizados para la resolucin de la Programacin Horaria
de Centrales. Estos datos se presentan en dos tablas, una muestra las caracte-
rsticas tcnicas de cada grupo y la otra, las caractersticas econmicas. Entre
las caractersticas tcnicas se incluyen la potencia mxima nominal, el mnimo
tcnico, la rampa de subida, la rampa de bajada y la potencia de salida de la
hora 0. En la tabla de costes se incluyen los coecientes que forman parte de la
funcin objetivo: el coste cuadrtico, lineal y jo, y los costes de arranque y pa-
rada. Los coecientes de costes estn expresados en unidades de calor (termia,
Te). Para convertir estos datos en euros se emplea el precio del combustible,
representado por PC
i
, cuyas unidades son euros/Te.
B.1. Caso test
La tabla B.1 muestra las caractersticas tcnicas de los generadores que
forman el caso test usado para validar el mtodo presentado. La tabla B.2
muestra los datos de los costes de produccin, arranque y parada de estos
generadores. Por simplicidad, se han considerado tanto el coste cuadrtico
como el coste de parada cero.
223
Apndice B Datos
Grupo P
M
i
P
m
i
RS
i
RB
i
P
i
(0)
MW MW MW/h MW/h MW
1 1000 500 100 100 1000
2 1000 200 150 150 500
3 1000 200 300 300 500
4 1000 200 300 300 0
5 1000 200 300 300 0
Tabla B.1: Caractersticas tcnicas de las centrales trmicas del caso test.
Grupo a
i
b
i
c
i
CA
i
CP
i
PC
i
Te/MW
2
h Te/MWh Te/h Te Te euros/Te
1 0 0.98 54.54 520 0 1
2 0 2.31 71 2494.9 0 1
3 0 2.18 61.46 1010 0 1
4 0 3.68 72 2080 0 1
5 0 2.25 125.88 1600 0 1
Tabla B.2: Costes de las centrales trmicas del caso test.
Finalmente, la tabla B.3 muestra la demanda horaria considerada en este
caso.
Hora Demanda (MW)
1 1843
2 1706
3 1610
4 1592
5 1575
6 1597
7 1722
8 1902
9 2085
10 2171
11 2245
12 2291
Hora Demanda (MW)
13 2300
14 2256
15 2163
16 2187
17 2237
18 2288
19 2244
20 2147
21 2109
22 2107
23 2153
24 1988
Tabla B.3: Demanda para el caso test.
224
B.2 Caso realista
B.2. Caso realista
Las tablas B.4 y B.5 muestran las caractersticas tcnicas de los generadores
que forman el segundo caso de estudio basado en el sistema de generacin
trmico espaol. Las tablas B.6 y B.7 muestran los datos de los costes de
produccin, arranque y parada de estos generadores. Al igual que en el caso
test el coste cuadrtico y el coste de parada se han considerado cero.
Grupo P
M
i
P
m
i
RS
i
RB
i
P
i
(0)
MW MW MW/h MW/h MW
1 360 196.8 144 144 216.5
2 543 248.8 180 180 273.7
3 314 61.1 242 242 67.2
4 314 61.1 242 242 67.2
5 220 66 138 138 72.6
6 533 160 300 300 176
7 7856 2878 1200 1200 7000
8 350 166 168 168 182.6
9 150 36 180 180 0
10 300 48 180 180 52.8
11 141 65 70 70 71.5
12 141 69 65 65 75.9
13 330 158 160 160 173.8
14 350 173 165 165 190.3
15 350 173 165 165 190.3
16 80 44 40 40 48.4
17 289 100 46 46 110
18 160 80 74 74 88
19 520 80 235 235 88
20 148 74 74 74 81.4
21 350 150 191 191 165
22 270 136 60 60 149.6
23 350 213 121 121 234.3
24 155 70 60 60 77
25 350 180 161 161 198
Tabla B.4: Caractersticas tcnicas de las centrales trmicas del caso realista
(Centrales 1 a 25).
225
Apndice B Datos
Grupo P
M
i
P
m
i
RS
i
RB
i
P
i
(0)
MW MW MW/h MW/h MW
26 550 180 276 276 198
27 550 180 276 276 0
28 550 180 356 356 0
29 550 270 276 276 0
30 65 35 24 24 38.5
31 154 84 64 64 92.4
32 350 213 121 121 234.3
33 214 105 106 106 115.5
34 313 150 150 150 165.1
35 220 80 131 131 88
36 318 100 131 131 110
37 350 230 111 111 253
38 350 230 111 111 253
39 350 230 111 111 253
40 350 230 111 111 253
41 350 100 235 235 0
42 350 100 235 235 0
43 160 80 75 75 88
44 68 45 15 15 49.8
45 254 154 69 69 169.4
46 350 172 165 165 189.2
47 350 180 132 132 198
48 350 180 132 132 198
49 350 180 132 132 198
Tabla B.5: Caractersticas tcnicas de las centrales trmicas del caso realista
(Centrales 26 a 49).
226
B.2 Caso realista
Grupo a
i
b
i
c
i
CA
i
CP
i
PC
i
Te/MW
2
h Te/MWh Te/h Te Te euros/Te
1 0 2.4 54.8 7991.1 0 1
2 0 2.2 68.1 2494.9 0 1
3 0 2.4 19.6 780.8 0 1.6
4 0 2.3 45 2080 0 1.6
5 0 2.2 44.9 1644.8 0 1.6
6 0 2.2 92.6 1561.6 0 1.6
7 0 2.5 136.3 100000 0 0.4
8 0 2.3 46 1811.4 0 1
9 0 2.3 37.2 2080 0 1.6
10 0 2.3 37.2 809.6 0 1.6
11 0 2.2 61.5 911.7 0 1
12 0 2.3 47.7 310.4 0 1
13 0 2.2 73.3 1132.1 0 1
14 0 2.2 55.8 1636.8 0 1
15 0 2.2 46.3 832 0 1
16 0 2.3 20.1 1340.3 0 1
17 0 2.3 45 2080 0 1.6
18 0 2.6 33.9 932.9 0 1.1
19 0 2.2 75.8 1243.2 0 1.6
20 0 2.7 16.2 1357.2 0 1
21 0 2.3 37.9 1346.8 0 1
22 0 2.2 40.9 1418.2 0 1
23 0 2.4 45.2 1174.5 0 1
24 0 2.2 59.4 466.5 0 1.1
25 0 2.3 78.2 884.1 0 1.1
Tabla B.6: Costes de las centrales trmicas del caso realista (Centrales 1 a 25).
227
Apndice B Datos
Grupo a
i
b
i
c
i
CA
i
CP
i
PC
i
Te/MW
2
h Te/MWh Te/h Te Te euros/Te
26 0 2.2 61.5 1010 0 1
27 0 2.2 61.5 1010 0 1
28 0 2.1 105.6 1707 0 1
29 0 2.7 117.9 2126.2 0 1
30 0 2.4 27.6 744.7 0 1
31 0 2.3 26.5 790.7 0 1
32 0 2.3 35.7 1475 0 1
33 0 2.5 15.4 717 0 1
34 0 2.4 29 1867.6 0 1
35 0 2.2 77 792 0 1.1
36 0 2.1 30 1417 0 1.1
37 0 2.9 18 1224.6 0 0.9
38 0 2.9 70 1228.5 0 0.9
39 0 2.9 70 1223.3 0 0.9
40 0 3.1 -8.9 1828.4 0 0.9
41 0 2.4 48.9 2080 0 1.6
42 0 2.4 48.9 860.8 0 1.6
43 0 2.3 32.1 1409.2 0 1.1
44 0 3 8.7 402.6 0 1.1
45 0 2.4 14.8 850.6 0 1
46 0 2.1 63.7 1170.4 0 1
47 0 2.4 60 1354.6 0 1
48 0 2.4 60 1268.8 0 1
49 0 2.6 3 2189.2 0 1
Tabla B.7: Costes de las centrales trmicas del caso realista (Centrales 26 a
49).
228
B.2 Caso realista
Finalmente, la tabla B.8 muestra la demanda horaria considerada en este
caso.
Hora Demanda (MW)
1 16793
2 15543
3 14669
4 14501
5 14350
6 14551
7 15688
8 17328
9 18000
10 18000
11 18000
12 18000
Hora Demanda (MW)
13 18000
14 18000
15 18000
16 18000
17 18000
18 18000
19 18000
20 18000
21 18000
22 18000
23 18000
24 18000
Tabla B.8: Demanda para el caso realista.
229
Apndice B Datos
230
Apndice C
Soluciones obtenidas
En este apndice se muestran las programaciones de arranques y paradas
y las potencias de salida de las mejores soluciones obtenidas de la aplicacin
del Algoritmo Gentico y el procedimiento propuesto en esta tesis basado en
tcnicas de Punto Interior al problema de la Programacin Horaria de Centrales
para los dos casos de estudio analizados, cuyos datos de entrada se muestran
en el Apndice B.
C.1. Caso test
Las tablas C.1 y C.2 presentan las matrices de acoplamiento y potencias de
salida de las mejores soluciones obtenidas para el caso test por el mtodo de
optimizacin descrito en esta tesis y el Algoritmo Gentico, respectivamente.
C.2. Caso realista
Las tablas C.3, C.4, C.5, C.6 y C.7 muestran las matrices de acoplamiento
y potencias de salida de la mejor solucin obtenida para el caso realista por el
mtodo descrito en esta tesis.
Las tablas C.8, C.9, C.10, C.11 y C.12 presentan las matrices de acopla-
miento y potencias de salida de la mejor solucin obtenida para el caso realista
por el Algoritmo Gentico.
231
Apndice C Soluciones obtenidas
1 2 3 4 5
1 1 1 1 0 0
2 1 1 1 0 0
3 1 1 1 0 0
4 1 1 1 0 0
5 1 1 1 0 0
6 1 1 1 0 0
7 1 1 1 0 0
8 1 1 1 0 0
9 1 1 1 0 0
10 1 1 1 0 1
11 1 1 1 0 1
12 1 1 1 0 1
13 1 1 1 0 1
14 1 1 1 0 1
15 1 1 1 0 1
16 1 1 1 0 1
17 1 1 1 0 1
18 1 1 1 0 1
19 1 1 1 0 1
20 1 1 1 0 1
21 1 1 1 0 1
22 1 1 1 0 1
23 1 1 1 0 0
24 1 0 1 0 0
1 2 3 4 5
1 1 1 1 0 0
2 1 1 1 0 0
3 1 1 1 0 0
4 1 1 1 0 0
5 1 1 1 0 0
6 1 1 1 0 0
7 1 1 1 1 1
8 1 1 1 1 1
9 1 1 1 1 1
10 1 1 1 1 1
11 1 1 1 0 1
12 1 1 1 0 0
13 1 1 1 0 0
14 1 1 1 0 0
15 1 1 1 0 0
16 1 1 1 0 0
17 1 1 1 0 0
18 1 1 1 0 0
19 1 1 1 0 0
20 1 1 1 0 0
21 1 1 1 0 0
22 1 1 1 0 0
23 1 1 1 0 0
24 1 1 0 0 0
Tabla C.1: Matriz de acoplamiento de la mejor solucin para el caso test por:
a) el mtodo propuesto, b) el Algoritmo Gentico.
232
C.2 Caso realista
1 2 3 4 5
1 1000 200 643 600 600
2 1000 200 506 600 600
3 1000 200 410 600 600
4 1000 200 392 600 600
5 1000 200 375 600 600
6 1000 200 397 600 600
7 1000 200 522 600 600
8 1000 200 702 600 600
9 1000 200 885 600 600
10 1000 200 771 600 200
11 1000 200 845 600 200
12 1000 200 891 600 200
13 1000 200 900 600 200
14 1000 200 856 600 200
15 1000 200 763 600 200
16 1000 200 787 600 200
17 1000 200 837 600 200
18 1000 200 888 600 200
19 1000 200 844 600 200
20 1000 200 747 600 200
21 1000 200 709 600 200
22 1000 200 707 600 200
23 1000 200 953 600 600
24 1000 600 988 600 600
1 2 3 4 5
1 1000 200 643 0 0
2 1000 200 506 0 0
3 1000 200 410 0 0
4 1000 200 392 0 0
5 1000 200 375 0 0
6 1000 200 397 0 0
7 922 200 200 200 200
8 1000 201 289 200 212
9 1000 200 485 200 200
10 1000 200 571 200 200
11 1000 200 845 0 200
12 1000 291 1000 0 0
13 1000 300 1000 0 0
14 1000 256 1000 0 0
15 1000 200 963 0 0
16 1000 200 987 0 0
17 1000 237 1000 0 0
18 1000 288 1000 0 0
19 1000 244 1000 0 0
20 1000 200 947 0 0
21 1000 200 909 0 0
22 1000 200 907 0 0
23 1000 200 953 0 0
24 1000 988 0 0 0
Tabla C.2: Potencias (MW) de la mejor solucin para el caso test por: a) el
mtodo propuesto, b) el Algoritmo Gentico.
233
Apndice C Soluciones obtenidas
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1
5 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0
6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
7 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
9 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1
10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
11 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
12 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1
13 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
14 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
15 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
16 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
17 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0
18 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1
19 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
20 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
21 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
22 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
23 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
24 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
25 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
26 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
27 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
28 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
29 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
30 1 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1
31 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
32 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
33 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1
34 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
35 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
36 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
37 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
38 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
39 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
40 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
41 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 0 0
42 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
43 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
44 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
45 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
46 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
47 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
48 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
49 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Tabla C.3: Matriz de acoplamiento de la mejor solucin para el caso realista
por el mtodo propuesto (Horas 1 a 18).
234
C.2 Caso realista
19 20 21 22 23 24
1 1 1 1 1 1 1
2 1 1 1 1 1 1
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 0 0 0 0 0
6 0 0 0 0 0 0
7 1 1 1 1 1 1
8 1 1 1 1 1 1
9 0 0 0 0 0 0
10 0 0 0 0 0 0
11 1 1 1 1 1 1
12 1 1 1 1 1 1
13 1 1 1 1 1 1
14 1 1 1 1 1 1
15 1 1 1 1 1 1
16 1 1 1 1 1 1
17 0 0 0 0 0 0
18 1 0 0 0 0 0
19 0 0 0 0 0 0
20 1 1 1 1 1 1
21 1 1 1 1 1 1
22 1 1 1 1 1 1
23 1 1 1 1 1 1
24 0 0 0 0 0 0
25 1 1 1 1 1 1
26 1 1 1 1 1 1
27 1 1 1 1 1 1
28 1 1 1 1 1 1
29 1 1 1 1 1 1
30 1 1 0 0 0 0
31 1 1 1 1 1 1
32 1 1 1 1 1 1
33 1 1 1 1 1 1
34 1 1 1 1 1 1
35 1 1 1 1 1 1
36 1 1 1 1 1 1
37 1 1 1 1 1 1
38 1 1 1 1 1 1
39 1 1 1 1 1 1
40 1 1 1 1 1 1
41 0 0 0 0 0 0
42 0 0 0 0 0 0
43 1 1 1 1 1 1
44 0 0 0 0 0 0
45 1 1 1 1 1 1
46 1 1 1 1 1 1
47 1 1 1 1 1 1
48 1 1 1 1 1 1
49 1 1 1 1 1 1
Tabla C.4: Matriz de acoplamiento de la mejor solucin para el caso realista
por el mtodo propuesto (Horas 19 a 24).
235
Apndice C Soluciones obtenidas
1 2 3 4 5 6 7 8
1 259 244 197 197 197 197 270 345
2 543 543 543 543 543 543 543 543
3 187.5 187.5 187.5 187.5 187.5 187.5 187.5 187.5
4 187.5 187.5 187.5 187.5 187.5 187.5 187.5 187.5
5 143 143 143 143 143 143 143 143
6 346.5 346.5 346.5 346.5 346.5 346.5 346.5 346.5
7 7856 7856 7856 7856 7856 7856 7856 7856
8 350 350 268 211 171 227 350 350
9 93 93 93 93 93 93 93 93
10 174 174 174 174 174 174 174 174
11 141 103 103 103 103 103 103 141
12 141 105 105 105 105 105 105 105
13 330 330 330 330 330 330 330 330
14 350 350 350 350 350 350 350 350
15 350 350 350 350 350 350 350 350
16 80 80 62 60 48 62 80 80
17 194.5 194.5 194.5 194.5 194.5 194.5 194.5 194.5
18 120 120 120 120 120 120 120 120
19 300 300 300 300 300 300 300 300
20 74 74 74 74 74 74 74 74
21 350 350 262 196 155 214 350 350
22 270 270 270 270 270 270 270 270
23 268 256 213 213 213 213 277 336
24 71 112.5 112.5 112.5 112.5 112.5 112.5 112.5
25 180 265 265 265 265 265 265 180
26 550 550 550 550 550 550 550 550
27 550 550 550 550 550 550 550 550
28 550 550 550 550 550 550 550 550
29 410 410 410 410 410 410 410 270
30 50 50 50 50 50 50 50 50
31 154 154 120 112 88 114 154 154
32 350 350 287 252 218 264 350 350
33 105 105 159.5 159.5 159.5 159.5 105 105
34 212 197 150 150 150 150 225 298
35 81 150 150 150 150 150 150 185
36 318 318 103 103 103 103 318 318
37 230 230 230 230 230 230 230 230
38 230 290 290 290 290 290 290 230
39 230 290 290 290 290 290 290 230
40 230 230 230 230 230 230 230 230
41 225 225 225 225 225 225 225 225
42 225 225 225 225 225 225 225 225
43 80 80 80 80 80 80 80 80
44 45 56.5 56.5 56.5 56.5 56.5 56.5 56.5
45 197 190 154 154 154 154 202 241
46 350 350 350 350 350 350 350 350
47 244 228 180 180 180 180 257 336
48 244 228 180 180 180 180 257 336
49 180 180 180 180 180 180 180 180
Tabla C.5: Potencias (MW) de la mejor solucin para el caso realista por el
mtodo propuesto (horas 1 a 8).
236
C.2 Caso realista
9 10 11 12 13 14 15 16
1 360 360 360 360 360 360 349 349
2 543 543 543 543 543 543 543 543
3 187.5 187.5 187.5 187.5 187.5 187.5 187.5 187.5
4 187.5 187.5 187.5 187.5 61 61 61 61
5 143 143 143 143 143 66 66 66
6 346.5 346.5 346.5 346.5 346.5 346.5 346.5 346.5
7 7856 7856 7856 7856 7856 7856 7856 7856
8 350 350 350 350 350 350 350 350
9 93 93 93 36 36 36 36 36
10 174 174 174 174 174 174 174 174
11 141 141 141 141 141 141 141 141
12 105 105 105 105 105 105 141 141
13 330 330 330 330 330 330 330 330
14 350 350 350 350 350 350 350 350
15 350 350 350 350 350 350 350 350
16 80 80 80 80 80 80 80 80
17 194.5 194.5 194.5 194.5 196.5 100 100 100
18 120 120 120 80 80 80 80 80
19 300 300 300 300 300 300 300 300
20 74 74 74 74 74 74 74 74
21 350 350 350 350 350 350 350 350
22 270 270 270 270 270 270 270 270
23 350 350 350 350 350 350 340 340
24 112.5 112.5 112.5 112.5 112.5 112.5 112.5 112.5
25 350 350 350 350 325 180 180 180
26 550 550 550 550 550 550 550 550
27 550 550 550 550 550 550 550 550
28 550 550 550 550 550 550 550 550
29 270 270 270 270 270 270 270 270
30 65 65 65 65 65 65 57 57
31 154 154 154 154 154 154 154 154
32 350 350 350 350 350 350 350 350
33 214 214 214 214 214 150 120 120
34 313 313 313 313 313 313 302 302
35 220 220 220 220 220 220 180 180
36 318 318 318 318 318 318 318 318
37 233 233 233 233 230 230 230 230
38 233 233 233 232 230 230 230 230
39 230 230 230 230 230 230 230 230
40 230 230 230 230 230 230 230 230
41 225 225 225 225 225 100 100 100
42 225 225 225 225 225 225 225 225
43 160 160 160 160 136 80 80 80
44 56.5 56.5 56.5 56.5 56.5 56.5 56.5 56.5
45 254 254 254 254 254 254 244 244
46 350 350 350 350 350 350 350 350
47 350 350 350 350 350 350 339 339
48 350 350 350 350 350 350 339 339
49 302 302 302 187 180 180 180 180
Tabla C.6: Potencias (MW) de la mejor solucin para el caso realista por el
mtodo propuesto (horas 9 a 16).
237
Apndice C Soluciones obtenidas
17 18 19 20 21 22 23 24
1 360 360 360 360 360 360 360 360
2 543 543 543 543 543 543 543 543
3 187.5 187.5 187.5 187.5 187.5 187.5 187.5 187.5
4 61 61 187.5 187.5 187.5 187.5 187.5 187.5
5 66 143 143 143 143 143 143 143
6 346.5 346.5 346.5 346.5 346.5 346.5 346.5 346.5
7 7856 7856 7856 7856 7856 7856 7856 7856
8 350 350 350 350 350 350 350 350
9 36 36 93 93 93 93 93 93
10 174 174 174 174 174 174 174 174
11 141 141 141 141 141 141 141 141
12 141 141 141 141 141 141 141 141
13 330 330 330 330 330 330 330 330
14 350 350 350 350 350 350 350 350
15 350 350 350 350 350 350 350 350
16 80 80 80 80 80 80 80 80
17 100 194.5 194.5 194.5 194.5 194.5 194.5 194.5
18 80 80 80 120 120 120 120 120
19 300 300 300 300 300 300 300 300
20 74 74 74 74 74 74 74 74
21 350 350 350 350 350 350 350 350
22 270 270 270 270 270 270 270 270
23 350 350 350 350 350 350 350 350
24 112.5 112.5 112.5 112.5 112.5 112.5 112.5 112.5
25 180 215 293 345 350 350 350 350
26 550 550 550 550 550 550 550 550
27 550 550 550 550 550 550 550 550
28 550 550 550 550 550 550 550 550
29 270 270 270 270 270 270 270 270
30 65 65 65 65 50 50 50 50
31 154 154 154 154 154 154 154 154
32 350 350 350 350 350 350 350 350
33 110 213 213 213 214 214 214 214
34 313 313 313 313 313 313 313 313
35 220 220 220 220 220 220 220 220
36 318 318 318 318 318 318 318 318
37 230 230 230 230 233 233 233 233
38 230 230 230 230 233 233 233 233
39 230 230 230 230 233 233 233 233
40 230 230 230 230 230 230 230 230
41 225 225 225 225 225 225 225 225
42 225 225 225 225 225 225 225 225
43 80 107 126 154 160 160 160 160
44 56.5 56.5 56.5 56.5 56.5 56.5 56.5 56.5
45 254 254 254 254 254 254 254 254
46 350 350 350 350 350 350 350 350
47 350 350 350 350 350 350 350 350
48 350 350 350 350 350 350 350 350
49 180 180 180 180 224 224 224 224
Tabla C.7: Potencias (MW) de la mejor solucin para el caso realista por el
mtodo propuesto (horas 17 a 24).
238
C.2 Caso realista
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
4 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
7 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
8 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
9 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
12 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
13 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
14 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
15 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
16 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
17 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0
18 1 1 1 1 1 1 1 1 1 1 0 0 0 0 0 0 0 0
19 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
20 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
21 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
22 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
23 1 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
24 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
25 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1
26 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
27 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
28 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
29 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
30 1 1 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1
31 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
32 1 1 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1
33 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
34 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
35 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
36 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
37 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1
38 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
39 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
40 1 1 1 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0
41 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
42 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
43 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
44 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
45 1 1 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
46 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
47 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
48 1 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1
49 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1
Tabla C.8: Matriz de acoplamiento de la mejor solucin para el caso realista
por el Algoritmo Gentico (Horas 1 a 18).
239
Apndice C Soluciones obtenidas
19 20 21 22 23 24
1 1 1 1 1 1 1
2 1 1 1 1 1 1
3 0 0 0 0 0 0
4 0 0 0 0 0 0
5 0 0 0 0 0 0
6 0 0 0 0 0 0
7 1 1 1 1 1 1
8 1 1 1 1 1 1
9 0 0 0 0 0 0
10 0 0 0 0 0 0
11 1 1 1 1 1 1
12 1 1 1 1 1 1
13 1 1 1 1 1 1
14 1 1 1 1 1 1
15 1 1 1 1 1 1
16 1 1 1 1 1 1
17 0 0 0 0 0 0
18 0 0 0 0 0 0
19 0 0 0 0 0 0
20 0 0 0 0 0 0
21 1 1 1 1 1 1
22 1 1 1 1 1 1
23 1 1 1 1 1 1
24 1 1 1 1 1 1
25 1 1 1 1 1 1
26 1 1 1 1 1 1
27 1 1 1 1 1 1
28 1 1 1 1 1 1
29 0 0 0 0 0 0
30 1 1 1 1 1 1
31 1 1 1 1 1 1
32 1 1 1 1 1 1
33 1 1 1 1 1 1
34 1 1 1 1 1 1
35 1 1 1 1 1 1
36 1 1 1 1 1 1
37 1 1 1 1 1 1
38 1 1 1 1 1 1
39 1 1 1 1 1 1
40 0 0 0 0 0 0
41 0 0 0 0 0 0
42 0 0 0 0 0 0
43 1 1 1 1 1 1
44 0 0 0 0 0 0
45 1 1 1 1 1 1
46 1 1 1 1 1 1
47 1 1 1 1 1 1
48 1 1 1 1 1 1
49 1 1 1 1 1 1
Tabla C.9: Matriz de acoplamiento de la mejor solucin para el caso realista
por el Algoritmo Gentico (Horas 19 a 24).
240
C.2 Caso realista
1 2 3 4 5 6 7 8
1 357 209 197 197 197 197 307 360
2 543 543 543 543 543 543 543 543
3 0 0 0 0 0 0 0 0
4 61 61 61 61 61 61 0 0
5 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0
7 7856 7856 7856 7856 7856 7856 7856 7856
8 350 350 335 279 220 203 350 350
9 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 0
11 141 141 141 141 141 141 141 141
12 141 141 131 109 98 94 141 141
13 330 330 330 330 330 330 330 330
14 350 350 350 350 350 350 350 350
15 350 350 350 350 350 350 350 350
16 80 80 72 63 60 59 80 80
17 100 100 100 100 100 100 100 100
18 80 80 80 80 80 80 80 80
19 0 0 0 0 0 0 0 0
20 0 0 0 0 0 0 0 0
21 350 350 335 275 206 187 350 350
22 270 270 270 270 270 270 270 270
23 347 0 0 0 0 0 0 350
24 70 70 70 70 70 70 70 155
25 0 0 0 0 0 0 0 0
26 550 550 550 550 550 550 550 550
27 550 550 550 550 550 550 550 550
28 550 550 550 550 550 550 550 550
29 0 0 0 0 0 0 0 0
30 64 44 0 0 0 0 50 65
31 154 154 144 122 113 108 154 154
32 350 350 0 0 0 247 350 350
33 105 105 105 105 105 105 105 214
34 310 162 150 150 150 150 260 313
35 80 80 80 80 80 80 80 220
36 318 318 100 100 100 100 318 318
37 0 0 0 0 0 0 0 0
38 230 230 230 230 230 230 230 230
39 230 230 230 230 230 230 230 230
40 230 230 230 230 230 230 0 0
41 0 0 0 0 0 0 0 0
42 0 0 0 0 0 0 0 0
43 0 0 0 0 0 0 0 160
44 0 0 0 0 0 0 0 0
45 252 167 0 0 0 0 0 254
46 350 350 350 350 350 350 350 350
47 347 192 180 180 180 180 296 350
48 347 0 0 0 0 0 296 350
49 0 0 0 0 0 0 0 315
Tabla C.10: Potencias (MW) de la mejor solucin para el caso realista por el
Algoritmo Gentico (horas 1 a 8).
241
Apndice C Soluciones obtenidas
9 10 11 12 13 14 15 16
1 360 360 360 360 360 360 360 360
2 543 543 543 543 543 543 543 543
3 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0
7 7856 7856 7856 7856 7856 7856 7856 7856
8 350 350 350 350 350 350 350 350
9 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 0
11 141 141 141 141 141 141 141 141
12 141 141 141 141 141 141 141 141
13 330 330 330 330 330 330 330 330
14 350 350 350 350 350 350 350 350
15 350 350 350 350 350 350 350 350
16 80 80 80 80 80 80 80 80
17 100 100 0 0 0 0 0 0
18 80 80 0 0 0 0 0 0
19 0 0 0 0 0 0 0 0
20 0 0 0 0 0 0 0 0
21 350 350 350 350 350 350 350 350
22 270 270 270 270 270 270 270 270
23 350 350 350 350 350 350 350 350
24 155 155 155 155 155 155 155 155
25 350 350 350 350 350 350 350 350
26 550 550 550 550 550 550 550 550
27 550 550 550 550 550 550 550 550
28 550 550 550 550 550 550 550 550
29 0 0 0 0 0 0 0 0
30 65 65 65 65 65 65 65 65
31 154 154 154 154 154 154 154 154
32 350 350 350 350 350 350 350 350
33 214 214 214 214 214 214 214 214
34 313 313 313 313 313 313 313 313
35 220 220 220 220 220 220 220 220
36 318 318 318 318 318 318 318 318
37 249 249 310 310 310 310 310 310
38 249 249 310 310 310 310 310 310
39 249 249 310 310 310 310 310 310
40 0 0 0 0 0 0 0 0
41 0 0 0 0 0 0 0 0
42 0 0 0 0 0 0 0 0
43 160 160 160 160 160 160 160 160
44 0 0 0 0 0 0 0 0
45 254 254 254 254 254 254 254 254
46 350 350 350 350 350 350 350 350
47 350 350 350 350 350 350 350 350
48 350 350 350 350 350 350 350 350
49 350 350 349 349 349 349 349 349
Tabla C.11: Potencias (MW) de la mejor solucin para el caso realista por el
Algoritmo Gentico (horas 9 a 16).
242
C.2 Caso realista
17 18 19 20 21 22 23 24
1 360 360 360 360 360 360 360 360
2 543 543 543 543 543 543 543 543
3 0 0 0 0 0 0 0 0
4 0 0 0 0 0 0 0 0
5 0 0 0 0 0 0 0 0
6 0 0 0 0 0 0 0 0
7 7856 7856 7856 7856 7856 7856 7856 7856
8 350 350 350 350 350 350 350 350
9 0 0 0 0 0 0 0 0
10 0 0 0 0 0 0 0 0
11 141 141 141 141 141 141 141 141
12 141 141 141 141 141 141 141 141
13 330 330 330 330 330 330 330 330
14 350 350 350 350 350 350 350 350
15 350 350 350 350 350 350 350 350
16 80 80 80 80 80 80 80 80
17 0 0 0 0 0 0 0 0
18 0 0 0 0 0 0 0 0
19 0 0 0 0 0 0 0 0
20 0 0 0 0 0 0 0 0
21 350 350 350 350 350 350 350 350
22 270 270 270 270 270 270 270 270
23 350 350 350 350 350 350 350 350
24 155 155 155 155 155 155 155 155
25 350 350 350 350 350 350 350 350
26 550 550 550 550 550 550 550 550
27 550 550 550 550 550 550 550 550
28 550 550 550 550 550 550 550 550
29 0 0 0 0 0 0 0 0
30 65 65 65 65 65 65 65 65
31 154 154 154 154 154 154 154 154
32 350 350 350 350 350 350 350 350
33 214 214 214 214 214 214 214 214
34 313 313 313 313 313 313 313 313
35 220 220 220 220 220 220 220 220
36 318 318 318 318 318 318 318 318
37 310 310 310 310 310 310 310 310
38 310 310 310 310 310 310 310 310
39 310 310 310 310 310 310 310 310
40 0 0 0 0 0 0 0 0
41 0 0 0 0 0 0 0 0
42 0 0 0 0 0 0 0 0
43 160 160 160 160 160 160 160 160
44 0 0 0 0 0 0 0 0
45 254 254 254 254 254 254 254 254
46 350 350 350 350 350 350 350 350
47 350 350 350 350 350 350 350 350
48 350 350 350 350 350 350 350 350
49 349 349 349 349 349 349 349 349
Tabla C.12: Potencias (MW) de la mejor solucin para el caso realista por el
Algoritmo Gentico (horas 17 a 24).
243
Apndice C Soluciones obtenidas
244
Apndice D
Subproblemas
Como notacin estndar se usarn letras maysculas para las variables y
datos del problema y minsculas para todas las variables intermedias y auxi-
liares que se necesiten para resolverlo.
D.1. Subproblema continuo
El subproblema de optimizacin continuo es el siguiente:
Minimizar C
T
(D.1)
sujeto a
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
= D
t
(D.2)
ng
i=1
P
M
i
U
i,t
R
t
+D
t
n
h
h=1
PH
M
h
(D.3)
V H
h,t
= V H
h,t1
PH
h,t
+
sig(k)=h
PH
k,tret(k)
+W
h
(D.4)
P
m
i
P
i,t
P
M
i
(D.5)
0 U
i,t
1 (D.6)
C
T
C (D.7)
RB
i
P
i,t
P
i,t1
RS
i
(D.8)
PH
m
h
PH
h,t
PH
M
h
(D.9)
V H
m
h
V H
h,t
V H
M
h
(D.10)
Introduciendo variables adecuadas, para que todas las restricciones de m-
ximos y mnimos se apliquen sobre variables del problema, se obtiene:
245
Apndice D Subproblemas
Minimizar V (D.11)
sujeto a V = C
T
(D.12)
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
= D
t
(D.13)
X
t
R
t
+D
t
n
h
h=1
PH
M
h
(D.14)
V H
h,t
= V H
h,t1
PH
h,t
+
sig(k)=h
PH
k,tret(k)
+W
h
(D.15)
Z
i,t
= P
i,t
P
i,t1
(D.16)
X
t
=
ng
i=1
P
M
i
U
i,t
(D.17)
P
m
i
P
i,t
P
M
i
(D.18)
0 U
i,t
1 (D.19)
V C (D.20)
RB
i
Z
i,t
RS
i
(D.21)
PH
m
h
PH
h,t
PH
M
h
(D.22)
V H
m
h
V H
h,t
V H
M
h
(D.23)
Introduciendo variables de holguras apropiadas, se convierten las restriccio-
nes de desigualdad en igualdad, y penalizando la funcin objetivo para asegurar
que las variables de holgura sean positivas el problema se formula as:
246
D.1 Subproblema continuo
Minimizar V
i,h,t
ln(s
k
) (D.24)
sujeto a V = C
T
(D.25)
ng
i=1
P
i,t
U
i,t
+
n
h
h=1
PH
h,t
= D
t
(D.26)
V H
h,t
= V H
h,t1
PH
h,t
+
sig(k)=h
PH
k,tret(k)
+W
h
(D.27)
Z
i,t
= P
i,t
P
i,t1
(D.28)
X
t
=
ng
i=1
P
M
i
U
i,t
(D.29)
s
1
i,t
+P
i,t
P
M
i
= 0 (D.30)
s
2
i,t
P
i,t
+P
m
i
= 0 (D.31)
s
3
i,t
+U
i,t
1 = 0 (D.32)
s
4
i,t
U
i,t
= 0 (D.33)
s
5
+V C = 0 (D.34)
s
6
i,t
+Z
i,t
RS
i
= 0 (D.35)
s
7
i,t
Z
i,t
RB
i
= 0 (D.36)
s
8
h,t
+PH
h,t
PH
M
h
= 0 (D.37)
s
9
h,t
PH
h,t
+PH
m
h
= 0 (D.38)
s
10
h,t
+V H
h,t
V H
M
h
= 0 (D.39)
s
11
h,t
V H
h,t
+V H
m
h
= 0 (D.40)
s
12
t
X
t
+R
t
+D
t
n
h
h=1
PH
M
h
= 0 (D.41)
s
k
0 k = 1, . . . , 12 (D.42)
donde es el factor de penalizacin.
247
Apndice D Subproblemas
El Lagrangiano del problema, para cada , es el que sigue:
L
= V +
1
(V C
T
) +
2
t
_
i
P
i,t
U
i,t
h
PH
h,t
+D
t
_
+
h,t
3
h,t
_
_
V H
h,t
V H
h,t1
+PH
h,t
sig(k)=h
PH
k,tret(k)
W
h
_
_
+
i,t
_
4
i,t
(s
1
i,t
+P
i,t
P
M
i
) +
5
i,t
(s
2
i,t
P
i,t
+P
m
i
)
_
+
i,t
_
6
i,t
(s
3
i,t
1 +U
i,t
) +
7
i,t
(s
4
i,t
U
i,t
)
_
+
8
(s
5
+V C) +
i,t
9
i,t
(Z
i,t
P
i,t
+P
i,t1
)
+
i,t
_
10
i,t
(s
6
i,t
RS
i
+Z
i,t
) +
11
i,t
(s
7
i,t
Z
i,t
RB
i
)
_
(D.43)
+
h,t
_
12
h,t
(s
8
h,t
+PH
h,t
PH
M
h
) +
13
h,t
(s
9
h,t
PH
h,t
+PH
m
h
)
_
+
h,t
_
14
h,t
(s
10
h,t
+V H
h,t
V H
M
h
) +
15
h,t
(s
11
h,t
V H
h,t
+V H
m
h
)
_
+
16
t
_
X
t
i
P
M
i
U
i,t
_
+
17
t
_
s
12
t
X
t
+R
t
+D
t
h
PH
M
h
_
lns
5
i,t
(ln s
1
i,t
+ ln s
2
i,t
+ ln s
3
i,t
+ ln s
4
i,t
+ ln s
6
i,t
+ ln s
7
i,t
)
h,t
(ln s
8
h,t
+ ln s
9
h,t
+ ln s
10
h,t
+ ln s
11
h,t
)
t
ln s
12
t
donde
k
con k = 1, . . . , 17 son los Multiplicadores de Lagrange.
248
D.1 Subproblema continuo
Las ecuaciones de optimalidad de KKT de primer orden son las siguientes:
L
P
i,t
=
1
C
i,t
U
i,t
2
t
U
i,t
+
4
i,t
5
i,t
9
i,t
+
9
i,t+1
= 0 (D.44)
L
U
i,t
=
1
C
U,A,P
i,t
+
6
i,t
7
i,t
2
t
P
i,t
16
t
P
M
i
= 0 (D.45)
L
PH
h,t
=
3
h,t
3
sig(h),t+ret(h)
2
t
+
12
h,t
13
h,t
= 0 (D.46)
L
V H
h,t
=
3
h,t
3
h,t+1
+
14
h,t
15
h,t
= 0 (D.47)
L
V
= 1 +
1
+
8
= 0 (D.48)
L
Z
i,t
=
9
i,t
+
10
i,t
11
i,t
= 0 (D.49)
L
X
t
=
16
t
17
t
= 0 (D.50)
L
s
k
= 0 s
k
k
= k = 1, . . . , 12 (D.51)
junto con las ecuaciones (D.25)-(D.41).
Aplicando el Mtodo de Newton y eliminando las variables de holgura y sus
correspondientes multiplicadores se obtiene el sistema de ecuaciones de KKT
reducido siguiente:
Ecuaciones relacionadas con las restricciones tcnicas de las centrales
trmicas:
DP
i,t
P
i,t
+PU
i,t
U
i,t
9
i,t
+
9
i,t+1
U
i,t
2
t
C
i,t
U
i,t
1
= h
1
(, ) (D.52)
PU
i,t
P
i,t
+
1
C
A,P
i
(U
i,t1
+ U
i,t+1
) +DU
i,t
U
i,t
P
i,t
2
t
P
M
i
16
t
C
U,A,P
i,t
1
= h
2
(, ) (D.53)
DZ
i,t
Z
i,t
+
9
i,t
= h
3
(, ) (D.54)
P
i,t1
P
i,t
+ Z
i,t
= h
4
(, ) (D.55)
Ecuaciones relacionadas con la restriccin impuesta al coste:
DV V +
1
= h
5
(, ) (D.56)
i,t
C
i,t
P
i,t
i,t
C
U,A,P
i,t
U
i,t
+ V = h
6
(, ) (D.57)
249
Apndice D Subproblemas
Ecuaciones relacionadas con las restricciones tcnicas de las centrales
hidrulicas:
DPH
h,t
PH
h,t
+
3
h,t
3
sig(h),t+ret(h)
2
t
= h
7
(, ) (D.58)
3
h,t
3
h,t+1
+DV H
h,t
V H
h,t
= h
8
(, ) (D.59)
V H
h,t
V H
h,t1
+ PH
h,t
sig(k)=h
PH
k,tret(k)
= h
9
(, ) (D.60)
Ecuaciones relacionadas con las restricciones del sistema:
i
U
i,t
P
i,t
i
P
i,t
U
i,t
h
PH
h,t
= h
10
(, ) (D.61)
X
t
i
P
M
i
U
i,t
= h
11
(, ) (D.62)
16
t
+DXX
t
= h
12
(, ) (D.63)
donde los coecientes de la matriz vienen dados por:
DP
i,t
=
4
i,t
s
1
i,t
+
5
i,t
s
2
i,t
2
1
c
i
U
i,t
(D.64)
DU
i,t
=
6
i,t
s
3
i,t
+
7
i,t
s
4
i,t
(D.65)
PU
i,t
=
1
C
i,t
2
t
(D.66)
C
A,P
i
= CA
i
+CP
i
(D.67)
C
U,A,P
i,t
= C
i,t
+C
A,P
i
(1 U
i,t1
U
i,t+1
) (D.68)
DZ
i,t
=
10
i,t
s
6
i,t
+
11
i,t
s
7
i,t
(D.69)
DV =
8
s
5
(D.70)
DPH
h,t
=
12
h,t
s
8
h,t
+
13
h,t
s
9
h,t
(D.71)
DV H
h,t
=
14
h,t
s
10
h,t
+
15
h,t
s
11
h,t
(D.72)
DX =
17
t
s
12
t
(D.73)
250
D.1 Subproblema continuo
Y los trminos independientes de las ecuaciones son los siguientes:
h
1
(, ) =
L
P
i,t
s
1
i,t
4
i,t
s
1
i,t
(P
i,t
P
M
i
) +
s
2
i,t
+
+
5
i,t
s
2
i,t
(P
m
i
P
i,t
) (D.74)
h
2
(, ) =
L
U
i,t
s
3
i,t
6
i,t
s
3
i,t
(U
i,t
1) +
s
4
i,t
7
i,t
s
4
i,t
U
i,t
(D.75)
h
3
(, ) =
L
Z
i,t
s
6
i,t
10
i,t
s
6
i,t
(Z
i,t
RS
i
) +
s
7
i,t
+
+
11
i,t
s
7
i,t
(RB
i
Z
i,t
) (D.76)
h
4
(, ) =
L
9
i,t
(D.77)
h
5
(, ) =
L
V
s
5
8
s
5
(V C) (D.78)
h
6
(, ) =
L
1
(D.79)
h
7
(, ) =
L
PH
h,t
s
8
h,t
12
h,t
s
8
h,t
(PH
h,t
PH
M
h
)
+
s
9
h,t
+
13
h,t
s
9
h,t
(PH
m
h
PH
h,t
) (D.80)
h
8
(, ) =
L
V H
h,t
s
10
h,t
14
h,t
s
10
h,t
(V H
h,t
V H
M
h
)
+
s
11
h,t
+
15
h,t
s
11
h,t
(V H
m
h
V H
h,t
) (D.81)
h
9
(, ) =
L
3
h,t
(D.82)
h
10
(, ) =
L
2
t
(D.83)
h
11
(, ) =
L
16
t
(D.84)
h
12
(, ) =
L
X
t
+
s
12
t
+
17
t
s
12
t
(X
t
+R
t
+D
t
h
PH
M
h
) (D.85)
Sin prdida de generalidad y para una mayor comodidad de notacin, se
supone que:
251
Apndice D Subproblemas
El horizonte de programacin est dividido en dos intervalos horarios.
El embalse h tiene al embalse h +1 situado aguas abajo y el tiempo que
tarda en llegar el agua de un embalse a otro es de un intervalo horario.
Entonces el sistema de ecuaciones se puede escribir matricialmente por
bloques como sigue:
_
_
D
i,h
1
S
i
1
P 0 R
1
0 C
i
1
S
i
1
D
i,h
2
0 P R
2
0 C
i
2
P 0 0 0 0 0 0
P 0 0 0 0 0 0
R
1
0 0 D
1
0 0 0
R
2
0 0 0 D
2
0 0
0 0 0 0 0 0 DV 1
C
i
1
C
i
2
0 0 0 0 1
_
_
_
_
X
h,i
1
X
h,i
2
2
1
2
2
Y
i
1
Y
i
2
V
1
_
_
=
_
_
a
h,i
1
a
h,i
2
b
1
b
2
c
1
c
2
d
e
_
_
Fijado un intervalo de tiempo se tiene que:
Los bloques diagonales, D
i,h
t
, y los bloques superdiagonales, S
i
1
, son ma-
trices cuadradas de dimensin 4n
g
+ 3n
h
. A continuacin se describen
los bloques diagonales y superdiagonales. Por comodidad de notacin se
supone que hay dos centrales trmicas y dos hidrulicas.
Cada bloque diagonal tiene la siguiente estructura:
D
i,h
t
=
_
TER
HID
_
donde
TER =
P
1,t
P
2,t
U
1,t
U
2,t
Z
1,t
Z
2,t
9
1,t
9
2,t
P
1,t
P
2,t
U
1,t
U
2,t
Z
1,t
Z
2,t
9
1,t
9
2,t
_
_
DP
1,t
PU
1,t
1
DP
2,t
PU
2,t
1
PU
1,t
DU
1,t
PU
2,t
DU
2,t
DZ
1,t
1
DZ
2,t
1
1 1
1 1
_
_
252
D.1 Subproblema continuo
HID =
PH
1,t
PH
2,t
3
1,t
V H
1,t
3
2,t
V H
2,t
PH
1,t
PH
2,t
3
1,t
V H
1,t
3
2,t
V H
2,t
_
_
DPH
1,t
1
DPH
2,t
1
1 1
1 DV H
1,t
1 1
1 DV H
2,t
_
_
Los bloques superdiagonales estn formados por dos bloques diagonales,
uno relacionado con las ecuaciones trmicas, S
TER
, que surge debido a la
ecuacin de rampas de subida y bajada y otro relacionado con las ecua-
ciones hidrulicas, S
HID
, que surge debido a la ecuacin de acoplamiento
entre embalses. Estos bloques son como se muestra a continuacin:
S
TER
=
P
1,t
P
2,t
U
1,t
U
2,t
Z
1,t
Z
2,t
9
1,t
9
2,t
P
1,t
P
2,t
U
1,t
U
2,t
Z
1,t
Z
2,t
9
1,t
9
2,t
_
_
1
1
1
1
_
_
S
HID
=
PH
1,t
PH
2,t
3
1,t
V H
1,t
3
2,t
V H
2,t
PH
1,t
PH
2,t
1
V H
1,t
3
2,t
V H
2,t
_
_
1
1
1
_
_
P es un vector de dimensin 4n
g
+ 3n
h
, donde las 2n
g
primeras compo-
nentes estn formadas por las potencias trmicas P
i,t
, las siguientes 2n
g
estn formadas por ceros, las siguientes n
h
por unos y las restantes 2n
h
por ceros.
R
t
es una matriz de dimensin (4n
g
+3n
h
)2, donde la primera columna
est formada por ceros y la segunda tambin excepto las componentes
n
g
+ 1, . . . , 2n
g
que estn formadas por las potencias mximas de las
centrales trmicas, P
M
i
.
253
Apndice D Subproblemas
C
i
t
es un vector de dimensin 4n
g
+ 3n
h
donde las n
g
primeras compo-
nentes estn formadas por U
i,t
C
i,t
, las n
g
siguientes por C
U,A,P
i,t
y el resto
por ceros.
D
t
es una matriz 2 2 como sigue:
D
t
=
X
t
16
t
X
t
16
t
_
DX 1
1 0
_
(D.86)
X
h,i
t
es un vector de dimensin 4n
g
+ 3n
h
con la estructura siguiente:
X
h,i
t
= [P
i,t
, U
i,t
, Z
i,t
,
9
i,t
, PH
h,t
, [
3
h,t
, V
h,t
]]
2
t
es el vector de las correcciones del multiplicador de la ecuacin de
la demanda.
Y
i
t
es un vector de dimensin 2n
t
con la estructura siguiente:
Y
i
t
= [X
t
,
16
t
]
a
h,i
t
es un vector de dimensin 4n
g
+ 3n
h
, donde las 4n
g
primeras com-
ponentes estn formadas por h
1
(, ), h
2
(, ), h
3
(, ) y h
4
(, ), las n
h
siguientes por h
7
(, ) y las 2n
h
ltimas, por h
8
(, ) y h
9
(, ), de forma
intercalada. Es decir:
a
h,i
t
= [h
1
(, ), h
2
(, ), h
3
(, ), h
4
(, ), h
7
(, ), [h
8
(, ), h
9
(, )]]
b
t
es un vector de dimensin n
t
cuyas componentes estn formadas por
h
10
(, ).
c
t
es un vector de dimensin 2 formado por:
c
t
= [h
12
(, ), h
11
(, )]
d es un escalar formado por h
5
(, ).
e es un escalar formado por h
6
(, ).
Se trata de una matriz simtrica tanto estructuralmente como numrica-
mente y en general no denida positiva.
254
D.2 Subproblema discreto
D.2. Subproblema discreto
Para obtener el subproblema de optimizacin discreto basta sustituir en el
problema (D.1)-(D.10) la restriccin:
0 < U
i,t
< 1 por U
i,t
(1 U
i,t
) = 0 (D.87)
Esta nueva restriccin produce en las ecuaciones anteriores algunos cambios
que se indican a continuacin. Estos cambios slo afectan a las ecuaciones
relacionadas con las centrales trmicas. Los autovalores
6
i,t
y
7
i,t
desaparecen y
aparece un nuevo autovalor,
18
i,t
, asociado a la nueva ecuacin de igualdad. As,
la ecuacin (D.53), del grupo de ecuaciones relacionadas con las restricciones
trmicas, en el subproblema discreto es la siguiente:
PU
i,t
P
i,t
+
1
C
A,P
i
(U
i,t1
+ U
i,t+1
) +DU
i,t
U
i,t
+LU
i,t
18
i,t
P
i,t
2
t
P
M
i
16
t
C
U,A,P
i,t
1
=
L
U
i,t
(D.88)
donde:
DU
i,t
= 2
18
i,t
(D.89)
LU
i,t
= 1 2U
i,t
(D.90)
L
U
i,t
=
1
C
U,A,P
i,t
+ (1 2U
i,t
)
18
i,t
2
t
P
i,t
16
t
P
M
i
(D.91)
Adems en este grupo de ecuaciones aparece una nueva ecuacin corres-
pondiente al autovalor
18
i,t
:
LU
i,t
U
i,t
= U
i,t
(1 2U
i,t
) (D.92)
Esto afecta a la estructura por bloques de la matriz tan slo en los bloques
diagonales y superdiagonales, en lo que respecta a la parte trmica. Los bloques
diagonales, D
i,h
t
, y los bloques superdiagonales, S
i
1
, incrementan su dimensin
en n
g
debido a la nueva ecuacin (D.92), es decir, en este caso son matrices
cuadradas de dimensin 5n
g
+ 3n
h
.
255
Apndice D Subproblemas
TER =
P
1,t
P
2,t
U
1,t
U
2,t
Z
1,t
Z
2,t
9
1,t
9
2,t
18
1,t
18
2,t
P
1,t
P
2,t
U
1,t
U
2,t
Z
1,t
Z
2,t
9
1,t
9
2,t
18
1,t
18
2,t
_
_
DP
1,t
PU
1,t
1
DP
2,t
PU
2,t
1
PU
1,t
DU
1,t
LU
i,t
PU
2,t
DU
2,t
LU
i,t
DZ
1,t
1
DZ
2,t
1
1 1
1 1
LU
i,t
LU
i,t
_
_
S
TER
=
P
1,t
P
2,t
U
1,t
U
2,t
Z
1,t
Z
2,t
9
1,t
9
2,t
18
1,t
18
2,t
P
1,t
P
2,t
U
1,t
U
2,t
Z
1,t
Z
2,t
9
1,t
9
2,t
18
1,t
18
2,t
_
_
1
1
1
1
_
_
256
Bibliografa
[1] A. Abraham and B. Nath. A neuro-fuzzy approach for modelling elec-
tricity demand in victoria. Applied Software Computing, 11(2):127138,
2001.
[2] M. Adya, F. Collopy, J. Scott Armstrong, and M. Kennedy. Automatic
identication of time series features for rule-based forecasting. Interna-
tional Journal of Forecasting, 17:143157, 2001.
[3] D. W. Aha, D. Kibler, and M. K. Albert. Instance-based learning algo-
rithms. Machine Learning, 6:3766, 1991.
[4] A. S. Alfuhaid and M. A. El-Sayed. Cascaded articial neural network
for short-term load forecasting. IEEE Transactions on Power System,
12:15241529, 1997.
[5] N. Amjady. Short-term hourly load forecasting using time-series mode-
ling with peak load estimation capability. IEEE Transactions on Power
System, 16(3):498505, 2001.
[6] P. Angelov and R. Buswell. Identication of evolving fuzzy rule-based
models. IEEE Transactions on Fuzzy Systems, 10(5):667677, 2002.
[7] J. M. Arroyo and A. J. Conejo. Optimal response of a thermal unit
to an electricity spot market. IEEE Transactions on Power System,
15(3):10981104, 2000.
[8] J. M. Arroyo and A. J. Conejo. A parallel repair genetic algorithm
to solve the unit commitment problem. IEEE Transactions on Power
System, 17(4):12161224, 2002.
[9] V. Babovic, M. Keijzer, and M. Stefansson. Optimal embedding using
evolutionary algorithms. In Proceedings of the 4th International Confe-
rence on Hydroinformatics, 2000.
257
Bibliografa
[10] M. S. Bazaraa, H. D. Sherali, and C. M. Shetty. Nonlinear Programming:
Theory and Algorithms. Second Edition. John Wiley & Sons, New York,
1993.
[11] R. Bellman. Dynamic Programming. Princeton University Press, 1957.
[12] D. Berndt and J. Cliord. Using dynamic time warping to nd patterns
in time series. In Proceedings of the AAAI-94 Workshop on Knowledge
in Databases (KDD-94), 1994.
[13] G. E. P. Box and G. M. Jenkins. Time Series Analysis Forecasting and
Control. Second Edition. Holden-Day, San Francisco, 1976.
[14] L. Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone. Classication
and Regression Trees. Wadsworth, Belmont CA, 1984.
[15] L. Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone. Data Mining.
Practical Machine Learning Tools and Techniques with Java Implemen-
tations. Morgan Kaufmann, 1999.
[16] R. H. Byrd, M. E. Hribar, and J. Nocedal. An interior-point algorithm
for large-scale nonlinear programming. SIAM Journal of Optimization,
9(4):877900, 1999.
[17] A. Canoyra, C. Illn, A. Landa, J. M. Moreno, J. I. Prez Arriaga, C. Sa-
ll, and C. Sol. The hierarchical market approach to the economic and
secure operation of the spanish power system. In Proocedings of the Bulk
Power System Dynamic and Control IV, 2002.
[18] C-P. Cheng, C-W. Liu, and C-C. Liu. Unit commitment by lagrangian
relaxation and genetic algorithm. IEEE Transactions on Power System,
15:707714, 2000.
[19] G. Chicco, R. Napoli, and F. Piglione. Load pattern clustering for short-
term load forecasting of anomalus days. In Proceedings of the IEEE
Porto Power Tech Conference, 2001.
[20] A. I. Cohen and M. Yoshimura. A branch-and-bound algorithm for unit
commitment. IEEE Transactions Power Applications Systems, PAS-
102:444451, 1983.
[21] A. J. Conejo, J. Contreras, J. M. Arroyo, and S. de la Torre. Opti-
mal response of an oligopolistic generating company to a competitive
pool-based electric power market. IEEE Transactions on Power System,
17(2):404410, 2002.
258
Bibliografa
[22] J. Contreras, R. Espnola, F. J. Nogales, and A. J. Conejo. Arima mo-
dels to predict next-day electricity prices. IEEE Transactions on Power
System, 18(3):10141020, 2003.
[23] S. Cost and S. Salzberg. A weigted nearest neighbor algorithm for lear-
ning with symbolic features. Machine Learning, 10:5778, 1993.
[24] T. M. Cover. Estimation by nearest neighbor rule. IEEE Transactions
on Information Theory, 14:5055, 1968.
[25] T. M. Cover and P. E. Hart. Nearest neighbor pattern classication.
IEEE Transactions on Information Theory, 13(1):2127, 1967.
[26] T. M. Cover and J. A. Thomas. Elements of Information Theory. John
Wiley and Sons, John Wiley and Sons edition, 1991.
[27] B. V. Dasarathy. Nearest neighbour (nn) norms: Nn pattern classication
techniques. IEEE Computer Society Press, 1991.
[28] S. Dudani. The distance-weighted k-nearest-neighbor rule. IEEE Tran-
sactions on Systems, Man and Cybernetics, SMC-6, 4(1):325327, 1975.
[29] J-P. Eckmann, S. O. Kamphorst, D. Ruelle, and S. Ciliberto. Lyapunov
exponents from time series. Phisical Review, 34A:49714979, 1986.
[30] A. S. El-Bakry, R. A. Tapia, T. Tsuchiya, and Y. Zhang. On the for-
mulation and theory of the newton interior-point method for nonlinear
programming. Journal of Optimization and Applications, 89(3):507541,
Junio 1996.
[31] R. Espnola, J. Contreras, F. J. Nogales, and A. J. Conejo. Day-electricity
price forecasting based on time series models: A comparison. In Procee-
dings of the PSCC Power System Computation Conference, 2002.
[32] U. Fayyad and R. Uthurusamy. Data mining and knowledge discovery
in databases. Communication of the ACM, 39(11):2434, 1996.
[33] C. Ferreira. Gene expression programming: a new adaptive algorithm
for solving problems. Complex Systems, 13(2):87129, 2001.
[34] F. J. Ferrer, J. S. Aguilar, and J. C. Riquelme. Non-parametric nearest
neighbour with local adaptation. Lecture Notes in Articial Intelligence,
2258:2229, 2001.
259
Bibliografa
[35] D. B. Fogel. Evolutionary Computation. Toward a New Philosophy of
Machine Intelligence. Second Edition. IEEE Press, New York, 2000.
[36] C. Fonlupt. Solving the ocean color problem using a genetic programming
approach. Applied Soft Computing, 1:6372, 2001.
[37] A. Forsgren and P. E. Gill. Primal-dual interior methods for nonconvex
nonlinear programming. SIAM Journal of Optimization, 8(4):11321152,
1998.
[38] E. Frank and I. H. Witten. Generating accurate rule sets without glo-
bal optimization. In Proceedings of 15th International Conference on
Machine Learning ICML98, 1998.
[39] F. Gao, X. Guan, X-R. Cao, and A. Papalexopoulos. Forecasting power
market clearing price and quantity using a neural network method. In
Proceedings of the Power Engineering Summer Meeting, 2000.
[40] J. Garca-Gonzlez and G. Alonso. Short-term hydro scheduling with
cascaded and head-dependent reservoirs based on mixed-integer linear
programming. In Proceedings of the IEEE Porto Power Tech Conference,
2001.
[41] J. M. Gimeno, J. Bjar, and M. Snchez. Nearest-neighbours for time
series. Applied Intelligence, 20:2135, 2004.
[42] A. Gmez, J. L. Martnez, and V. H. Quintana. Transmission power
loss by interior-point methods. In Proceedings of the Power Industry
Computer Applications PICA99, 1999.
[43] D. E. Goldberg. Genetic Algorithms in Search, Optimization and Ma-
chine Learning. Addison-Wesley, Massachusetts, USA, 1989.
[44] S. Granville. Optimal reactive dispatch through interior point methods.
IEEE Transactions on Power System, 9(1):136146, 1994.
[45] M. Harries and K. Horn. A nearest trajectory strategy for time series
prediction. In Proceedings of the International Workshop on Advanced
Black-Box Techniques for Nonlinear Modeling, pages 112128, 1998.
[46] H. S. Hippert, C. E. Pedreira, and C. Souza. Neural networks for short-
term load forecasting: A review and evaluation. IEEE Transactions on
Power System, 16(1):4455, 2001.
260
Bibliografa
[47] J. B. Hiriart-Urruty and C. Lemarchal. Convex Analysis and Mini-
mization Algorithms. Vol. I and II. Springer-Verlag, Berlin, Germany,
1996.
[48] J. H. Holland. Adaptation in Natural and Articial Systems. University
of Michigan Press, Ann Arbor, USA, 1975.
[49] G. Holmes, M. Hall, and E. Frank. Generating rule sets from model
trees. In Proceedings of the 12th Australian Joint Conference on Articial
Intelligence, pages 112, 1999.
[50] K-Y. Huang, H-T. Yang, and C-L. Huang. A new thermal unit commit-
ment approach using constraint logic programming. IEEE Transactions
on Power System, 13:936945, 1998.
[51] A. Inda, R. Nieva, and J. Frausto. Cht: a digital computer package
for solving short term hydro-thermal coordination and unit commitment
problems. IEEE Transactions on Power Applications Systems, PAS-
1:168174, 1986.
[52] A. W. Jayawardena, W. K. Li, and P. Xu. Neighbourhood selection for
local modelling and prediction of hydrological time series. Journal of
Hidrology, 258:4057, 2002.
[53] N. Jimnez and A. J. Conejo. Short-term hydro-thermal coordination by
lagrangian relaxation: Solution of the dual problem. IEEE Transactions
on Power System, 14(1):8995, 1999.
[54] M. A. Kaboudan. A measure of time series predictability using genetic
programming applied to stock returns. International Journal of Forecas-
ting, 18:345357, 1999.
[55] M. A. Kaboudan. Compumetric forecasting of crude oil prices. In Pro-
ceedings of the IFAC Simposium on Modeling and Control of Economic
Systems, pages 283287, 2001.
[56] N. Karmarkar. A new polynomial-time algorithm for linear program-
ming. Combinatoria, 4(4):373395, 1984.
[57] S. A. Kazarlis, A. G. Bakirtzis, and V. Petridis. A genetic algorithm
solution to the unit commitment problem. IEEE Transactions on Power
System, 11(1):8392, 1996.
261
Bibliografa
[58] J. E. Kelley. The cutting plane method for solving convex problems.
SIAM J. Industrial and Applied Mathematics, 8:703712, 1960.
[59] M. B. Kennel, R. Brown, and H. D. I. Abarbanel. Determining em-
bedding dimension for phase-space reconstruction using a geometrical
construction. Physical Review A, 45(6):34033411, 1992.
[60] E. J. Keogh and S. Kasetty. On the need for time series data mining
benchmarks: A survey and empirical demonstration. Lecture Notes in
Computer Science, pages 122133, 2000.
[61] E. J. Keogh and M. J. Pazzani. Scaling up dynamic time warping to mas-
sive datasets. Lecture Notes in Articial Intelligence, 1704:111, 1999.
[62] E. J. Keogh and M. J. Pazzani. A simple dimensionality reduction tech-
nique for fast similarity search in large time series databases. In Procee-
dings of the 8th ACM SIGKDD International Conference on Knowledge
Discovery and Data Mining, pages 102111, 2002.
[63] A. Khotanzad, E. Zhou, and H. Elragal. A neuro-fuzzy approach to
short-term load forecasting in a price-sensitive environment. IEEE Tran-
sactions on Power System, 17(4):12731282, 2002.
[64] D. Kim and C. Kim. Forecasting time series with genetic fuzzy predictor
ensemble. IEEE Transactions on Fuzzy Systems, 5(4):523535, 1997.
[65] T. Kohonen. Self-organized formation of topologically correct feature
maps. Biological Cybernetics, 43:5969, 1986.
[66] J. R. Koza. Genetic Programming: On the Programming of Computers
by Means of Natural Selection. MA: MIT Press, Cambridge, 1992.
[67] R. Lamedica, A. Prudenzi, M. Sforna, M. Caciotta, and V. O. Cencellli. A
neural network based technique for short-term forecasting of anomalous
load periods. IEEE Transactions on Power System, 11(4):17491756,
1996.
[68] G. S. Lauer, N. R. Sandell Jr., N. R. Bertsekas, and T. A. Posbergh.
Solution of large scale optimal unit commitment problems. IEEE Tran-
sactions Power Applications Systems, PAS-101:7996, 1982.
[69] F. N. Lee, J. Huang, and R. Adapa. Multi-area unit commitment via se-
quential method and a dc power ow network model. IEEE Transactions
on Power Systems, 9:279287, 1994.
262
Bibliografa
[70] C-A. Li, R. B. Johnson, A. J. Svoboda, C. Tseng, and E. Hsu. A ro-
bust unit commitment algorithm for hydro-thermal optimization. IEEE
Transactions on Power Systems, 13:10511056, 1998.
[71] S. Lu, K. H. Ju, and K. H. Chon. A new algorithm for linear and
nonlinear arma model parameter estimation using ane geometry. IEEE
Transactions on Biomedical Engineering, 48(10):11161124, 2001.
[72] D. G. Luenberger. Linear and Nonlinear Programming. Second Edition.
Addison Wesley, Reading, Massachusetts, 1984.
[73] M. Madrigal and V. H. Quintana. An interior-point/cutting-plane algo-
rithm to solve unit commitment problems. IEEE Transactions on Power
System, 15(3):10221027, 2000.
[74] T. T. Maifeld and G. B. Shebl. Genetic-based unit commitment algo-
rithm. IEEE Transactions on Power System, 11(3):13591370, 1996.
[75] A. H. Mantawy, Y. L. Abdel-Magid, and S. Z. Selim. A genetic algorithm
with local search for unit commitment. In Proceedings of the 1997 Inte-
lligent System Applications to Power Systems (ISAP97), pages 170175,
1997.
[76] F. J. Marn, F. Garca-Lagos, and F. Sandoval. Global model for short
term load forecasting neural networks. IEE Proceedings-Generation
Transmission Disribution, 149(2):121125, 2002.
[77] J. L. Martnez, A. Gmez, J. M. Riquelme, A. Troncoso, and A. R. Ma-
rulanda. Inuence of ann-based market price forecasting uncertainty on
optimal bidding. In Proceedings of the PSCC Power System Computation
Conference, 2002.
[78] J. L. Martnez, A. Gmez, A. Troncoso, and J. M. Riquelme. Despacho
econmico de centrales trmicas e hidrulicas en el corto plazo mediante
tcnicas de punto interior. In Actas de las Jornadas Hispano-Lusas de
Ingeniera Elctrica, 2001.
[79] J. L. Martnez, A. Troncoso, J. M. Riquelme, and A. Gmez. Short-term
hydro-thermal coordination based on interior point nonlinear program-
ming and genetic algorithms. In Proceedings of the IEEE Porto Power
Tech Conference, 2001.
[80] G. P. McCormick and A. V. Fiacco. Nonlinear Programming: Sequential
Unconstrained Minimization Techniques. SIAM, Philadelphia, 1990.
263
Bibliografa
[81] J. McNames. Local modeling optimization for time series prediction.
Physical Review E, 2000.
[82] J. Medina, V. H. Quintana, and A. J. Conejo. A clipping-o interior-
point technique for medium-term hydro-thermal coordination. IEEE
Transactions on Power System, 14(1):266273, 1999.
[83] J. Medina, V. H. Quintana, A. J. Conejo, and F. Prez. Comparison
of interior-point codes for medium-term hydro-thermal coordination. In
In Proceedings of the Power Industry Computer Applications PICA97,
pages 224231, 1997.
[84] S. Mehrotra. On the implementation of a (primal-dual) interior method.
SIAM Journal on Optimization, 2(4):575601, 1992.
[85] L. Mic, J. Oncina, and R. C. Carrasco. A fast branch and bound nearest
neighbour classier in metric spaces. Pattern Recognition Letters, 17:731
739, 1996.
[86] Z. Michalewicz. Genetic Algorithms + Data Structures = Evolution Pro-
grams. Third Edition. Springer-Verlag, Berlin, Germany, 1996.
[87] J. Moody and C. Darken. Learning with localized receptive elds. In
Prooceedings of the Conectionist Models Summer School of Pittsburgh,
pages 162172, 1988.
[88] L. Mora-Lpez, I. Fortes Ruz, R. Morales-Bueno, and F. Triguero Ruz.
Dynamic discretization of continous values from time series. Lecture
Notes in Articial Intelligence, 1810:280291, 2000.
[89] L. Mora-Lpez, R. Ruz, and R. Morales-Bueno. Modelo para la se-
leccin automtica de componentes signicativas en el anlisis de series
temporales. In Actas de la CAEPIA2003 Conferencia de la Asociacin
Espaola sobre Inteligencia Articial, 2003.
[90] H. Mori, N. Kosemura, K. Ishiguro, and T. Kondo. Short-term load
forecasting with fuzzy regression tree in power systems. In Proceedings
of the IEEE International Conference on Systems, Man and Cibernetics,
pages 19481953, 2001.
[91] K. J. Mun, H. S. Kim, J. H. Park, T. W. Park, S. H. Park, K. R. Ryu,
and S. H. Chung. A parallel genetic algorithm approach for the unit
commitment problem. In Proceedings of the 1997 Intelligent System Ap-
plications to Power Systems (ISAP97), pages 188193, 1997.
264
Bibliografa
[92] G. L. Nemhauser and L. A. Wolsey. Integer and Combinatorial Optimi-
zation. John Wiley & Sons, New York, 1988.
[93] F. J. Nogales, J. Contreras, A. J. Conejo, and R. Espnola. Forecasting
next-day electricity prices by time series models. IEEE Transactions on
Power System, 17(2):342348, 2002.
[94] T. Oates. Identing distinctive subsequences in multivariate time se-
ries by clustering. In Proceedings of the KDD Knowledge Discovery in
Databases, 1999.
[95] A. D. Papalexopoulos and T. C. Hesterberg. A regression-based approach
to short-term system load forecasting. IEEE Transactions on Power
System, 5:15351547, 1990.
[96] H-O. Peitgen, H. Jrgens, and D. Saupe. Chaos and Fractals. New Fron-
tiers of Science. Spriger-Verlag, 1992.
[97] B. T. Polyak. Introduction to Optimization. Optimization Software, Inc,
New York, 1987.
[98] J. R. Quinlan. Learning with continous classes. In Proceedings of the 5th
Australian Joint Conference on Articial Intelligence, Singapore: World
Scientic, pages 343348, 1992.
[99] J. R. Quinlan. C4.5: Programs for Machine Learning. Morgan Kauf-
mann, 1993.
[100] V. Ramasubramanian and K. K. Paliwal. Fast nearest-neighbor search
algorithm based on approximation-elimination search. Pattern Recogni-
tion, 33:14971510, 2000.
[101] B. Ramsay and A. J. Wang. An electricity spot-price estimator with
particular reference to weekends and public holidays. In Proceedings of
the Universities Power Engineering Conference UPEC97, 1997.
[102] B. Ramsay and A. J. Wang. A neural network based estimator for elec-
tricity spot-pricing with particular reference to weekend and public ho-
lidays. Neurocomputing, 23:4757, 1998.
[103] A. Ratle and M. Sebag. Grammar-guided genetic programming and
dimensional consistency: application to non-parametric identication in
mechanics. Applied Soft Computing, 1:105118, 2001.
265
Bibliografa
[104] J. C. Riquelme, F. J. Ferrer, and J. S. Aguilar. Bsqueda de un patrn
para el valor de k en k-nn. In Actas de la CAEPIA2001 Conferencia de
la Asociacin Espaola sobre Inteligencia Articial, 2001.
[105] J. M. Riquelme, J. L. Martnez, A. Gmez, and D. Cros Goma. Load
pattern recognition and load forecasting by articial neural networks.
International Journal of Power and Energy Systems, 22:7479, 2002.
[106] J. M. Riquelme, A. Troncoso, A. Gmez, and J. L. Martnez. Finding im-
proved local minima of power system optimization problems by interior-
point methods. IEEE Transactions on Power System, 18(1):238244,
2003.
[107] F. Rosenblatt. The perceptron: a probabilistic model for information
storage and organization in the brain. Psychological Review, 65:386408,
1958.
[108] R. Ruiz, J. C. Riquelme, and J. S. Aguilar-Ruiz. Projection-based measu-
re for ecient feature selection. Journal of Intelligent and Fuzzy System,
12:175183, 2002.
[109] D. E. Rumelhart, G. E. Hinton, and R. J. Willians. Learning internal
representations by error propagation. In Prooceedings of the 3th Interna-
tional Joint Conference on Articial Intelligence, pages 162172, 1973.
[110] L. M. Saini and M. K. Soni. Articial neural network-based peak load
forecasting using conjugate gradient methods. IEEE Transactions on
Power System, 18(1):99105, 2003.
[111] R. Setiono, W. K. Leow, and J. M. Zurada. Extraction of rules from
articial neural networks for nonlinear regression. IEEE Transactions
on Neural Networks, 13(3):564577, 2002.
[112] S. Singh. Forecasting using a fuzzy nearest neighbour method. In Pro-
ceedings of the 6th International Conference on Fuzzy Theory and Tach-
nology, Fourth Joint Conference on Information Sciences, pages 8083,
1998.
[113] W. L. Snyder, H. D. Powell, and J. C. Rayburn. Dynamic programming
approach to unit commitment. IEEE Transactions on Power Systems,
2:339347, 1987.
266
Bibliografa
[114] B. R. Szkuta, L. A. Sanabria, and T. S. Dillon. Electricity price short-
term forecasting using articial neural networks. IEEE Transactions on
Power System, 14(3):851857, 1999.
[115] F. Takens. Detecting strange attractors in turbulence. Lecture Notes in
Mathematics, 898:336381, 1981.
[116] S. Takriti and J. R. Birge. Using integer programming to rene
lagrangian-based unit commitment solutions. IEEE Transactions on Po-
wer System, 15:151156, 2000.
[117] W. F. Tinney and J. F. Walker. Direct solutions of sparse network
equations by optimally ordered triangular factorization. In Proceedings
of IEEE, volume 55, pages 18011809, 1967.
[118] L. Torgo. Applying propositional learning to time series prediction.
In Proceedings of the 8th European Conference on Machine Learning
ECML95, 1995.
[119] G. L. Torres and V. H. Quintana. On a nonlinear multiple-centrality-
corrections interior-point method for optimal power ow. IEEE Tran-
sactions on Power System, 16(2):222228, 2001.
[120] A. Troncoso, J. C. Riquelme, J. L. Martnez, J. M. Riquelme, and A. G-
mez. Inuence of knn-based load forecasting errors on optimal energy
production. Lecture Notes in Articial Intelligence, 2902:189203, 2003.
[121] A. Troncoso, J. C. Riquelme, J. M. Riquelme, J. L. Martnez, and
A. Gmez. Electricity market price forecasting: Neural networks ver-
sus weighted-distance k nearest neighbours. Lecture Notes in Computer
Science, 2453:321330, 2002.
[122] A. Troncoso, J. C. Riquelme, J. M. Riquelme, and J. L. Martnez. Apli-
cacin de tcnicas de computacin evolutiva a la planicacin ptima de
la produccin de energa elctrica en el corto plazo. In Actas de TTIA03
V Jornadas de Transferencia Tecnolgica de Inteligencia Articial, pages
419428, San Sebastian, 2003.
[123] A. Troncoso, J. C. Riquelme, J. M. Riquelme, J. L. Martnez, and A. G-
mez. Application of evolutionary computation techniques to optimal
short-term electric energy production scheduling. Lecture Notes in Ar-
ticial Intelligence, 3040:656665, 2004.
267
Bibliografa
[124] A. Troncoso, J. M. Riquelme, J. C. Riquelme, A. Gmez, and J. L.
Martnez. A comparison of two techniques for next-day electricity price
forecasting. Lecture Notes in Computer Science, 2412:384390, 2002.
[125] A. Troncoso, J. M. Riquelme, J. C. Riquelme, A. Gmez, and J. L.
Martnez. Time-series prediction: Application to the short-term electric
energy demand. Lecture Notes in Articial Intelligence, 3040:577586,
2004.
[126] A. Troncoso, J. M. Riquelme, J. C. Riquelme, and J. L. Martnez. Predic-
cin de series temporales: Aplicacin a la demanda de energa elctrica
en el corto plazo. In Actas de CAEPIA03 X Conferencia de la Asocia-
cin Espaola sobre Inteligencia Articial, pages 7988, San Sebastian,
2003.
[127] A. Troncoso, J. M. Riquelme, J. C. Riquelme, J. L. Martnez, and A. G-
mez. Prediccin de series temporales econmicas: aplicacin a los precios
de la energa en el mercado elctrico espaol. In Proceedings of the IBE-
RAMIA 2002 VIII Iberoamerican Conference on Articial Intelligence.
Workshop de Minera de Datos y Aprendizaje, pages 111, Sevilla, 2002.
[128] W. Vandaele. Applied Time Series Analysis and Box-Jenkins Models.
Academic, 1983.
[129] Vanderbei and F. D. Shano. An interior-point algorithm for nonconvex
nonlinear programming. Computational Optimization and Applications,
13:231252, 1999.
[130] E. Vidal. New formulation and improvements of the nearest-neighbour
approximating and eliminating search algorithm (aesa). Pattern Recog-
nition Letters, 15:17, 1994.
[131] S. Vucetic, K. Tomsovic, and Z. Obradovic. Discovering price-load rela-
tionships in californias electricity market. IEEE Transactions on Power
System, 16(2):280286, 2001.
[132] Y. Wang and I. H. Witten. Induction of model trees for predicting
continous classes. In Proocedings of the poster papers of the European
Conference on Machine Learning, pages 128137, 1997.
[133] H. Wei, H. Sasaki, J. Kubokawa, and R. Yokoyama. An interior point
nonlinear programming for optimal power ow problems with a novel
data structure. IEEE Transactions on Power System, 13(3):870877,
1998.
268
Bibliografa
[134] D. Wettschereck and T. G. Dietterich. An experimental comparison
of nearest neighbor and nearest hyperrectangle algorithms. Machine
Learning, 19(1):528, 1995.
[135] K. P. Wong and Y. W. Wong. Thermal generator scheduling using hybrid
genetic/simulated-annealing approach. IEE Proc. - Part C, 142(4):372
380, 1995.
[136] A. J. Wood and B. F. Wollenberg. Power Generation, Operation and
Control. John Wiley & Sons Inc, 1996.
[137] S. J. Wright. Primal-Dual Interior-Point Methods. Philadelphia, PA:
SIAM, 1997.
[138] Y-C. Wu, A. S. Debs, and R. E. Marsten. A direct nonlinear predictor-
corrector primal-dual interior point algorithm for optimal power ows.
IEEE Transactions on Power System, 9(2):876883, 1994.
[139] H. Yamashita and H. Yabe. Superlinear and quadratic convergence of
some primal-dual interior-point methods for constrained optimization.
Mathematical Programming, 75:377397, 1996.
[140] X. Yan and V. H. Quintana. Improving an interior-point-based opf by
dynamic adjustments of step sizes and tolerances. IEEE Transactions
on Power System, 14(2):709717, 1999.
[141] H-T. Yang, C-M. Huang, and C-L. Huang. Identication of armax model
for short term load forecasting: An evolutionary programming approach.
IEEE Transactions on Power System, 11(1):403408, 1996.
[142] H. T. Yang, P. C. Yang, and C. L. Huang. A parallel genetic algo-
rithm approach to solving the unit commitment problem: Implementa-
tion on the transputer networks. IEEE Transactions on Power System,
12(2):661668, 1997.
[143] L. Zhang, P. B. Luh, and K. Kasiviswanathan. Energy clearing price
prediction and condence interval estimation with cascaded neural net-
works. IEEE Transactions on Power System, 18(1):99105, 2003.
269
También podría gustarte
- Modeler Jython Scripting Automation Book PDFDocumento276 páginasModeler Jython Scripting Automation Book PDFSantinAún no hay calificaciones
- Sesión 10 Introducción A EviewsDocumento33 páginasSesión 10 Introducción A EviewsGOrtizAAún no hay calificaciones
- Investigación de Tecnicas para El Diseño y Desarrollo de Procesos ETLDocumento4 páginasInvestigación de Tecnicas para El Diseño y Desarrollo de Procesos ETLAlbertoAún no hay calificaciones
- La Demanda Residencial de Energia Electrica en La Comunidad Autonoma de Andalucia Un Analisis Cuantitativo 0 PDFDocumento448 páginasLa Demanda Residencial de Energia Electrica en La Comunidad Autonoma de Andalucia Un Analisis Cuantitativo 0 PDFAriel Luis SacacaAún no hay calificaciones
- Curso RDocumento99 páginasCurso RguiburAún no hay calificaciones
- Guias Practicas Eviews UNIDocumento0 páginasGuias Practicas Eviews UNIJose AntonioAún no hay calificaciones
- Taller 2 - Introducción PythonDocumento25 páginasTaller 2 - Introducción Pythonnatlaia ulloa100% (1)
- Aplicación de técnicas de minería de datos al CEAMADocumento68 páginasAplicación de técnicas de minería de datos al CEAMAcachojjAún no hay calificaciones
- Emisiones CO2 paísesDocumento347 páginasEmisiones CO2 paísesjorge eliécer loaiza muñozAún no hay calificaciones
- Hugh Rudnick - Remuneración de La Transmisión en ChileDocumento42 páginasHugh Rudnick - Remuneración de La Transmisión en ChileCristián Ariel Vargas RaveloAún no hay calificaciones
- Ciencia de Datos en Python Vs SPSSDocumento28 páginasCiencia de Datos en Python Vs SPSSAndres Hernandez100% (1)
- Guia Basico Eviews7Documento91 páginasGuia Basico Eviews7carlos gamarra orellaAún no hay calificaciones
- Modelo EstructuralDocumento61 páginasModelo EstructuralAlejandro Javier AcostaAún no hay calificaciones
- Analisis de Datos Con RDocumento163 páginasAnalisis de Datos Con Rjustorfc100% (1)
- Delgado Emerson Propuesta Plan Reduccion Merma PDFDocumento120 páginasDelgado Emerson Propuesta Plan Reduccion Merma PDFHeidi BishopAún no hay calificaciones
- Evaluación de Proyectos - 2021 - UNIDAD IIDocumento87 páginasEvaluación de Proyectos - 2021 - UNIDAD IIMelvin Oswaldo Reyes PinedaAún no hay calificaciones
- Proceso ETL Pandora FMSDocumento9 páginasProceso ETL Pandora FMSBruce HerreraAún no hay calificaciones
- Estimando el modelo de Cagan con EviewsDocumento53 páginasEstimando el modelo de Cagan con EviewsRaul AguirreAún no hay calificaciones
- Big Data - New Tricks For EconometricsEsDocumento67 páginasBig Data - New Tricks For EconometricsEsFranklin CrossAún no hay calificaciones
- Curso de Data Analytics PDFDocumento9 páginasCurso de Data Analytics PDFpatobohr100% (1)
- Redes y Procesamiento DistribuidoDocumento2 páginasRedes y Procesamiento DistribuidoHector Ignacio Moreira MendozaAún no hay calificaciones
- Optimizacion Multi-ObjetivoDocumento99 páginasOptimizacion Multi-ObjetivoEduardo MoralesAún no hay calificaciones
- Desarrollo en Windows 8 y Windows Phone 8 Con XAML y C# - VVAA - Krasis PressDocumento47 páginasDesarrollo en Windows 8 y Windows Phone 8 Con XAML y C# - VVAA - Krasis PressKrasis Press50% (2)
- Estadistica Aplicada Una Vision InstrumentalDocumento19 páginasEstadistica Aplicada Una Vision InstrumentalJose Carlos Ramirez Castillo50% (2)
- Lenguaje de Programacion Fortran PDFDocumento195 páginasLenguaje de Programacion Fortran PDFalvaroAún no hay calificaciones
- Python EssentialsDocumento17 páginasPython EssentialsJason AnthonyAún no hay calificaciones
- Introducción a Python y ML enDocumento20 páginasIntroducción a Python y ML enGABRIEL EDUARDO DEL CARPIO VILLAFUERTEAún no hay calificaciones
- Teorema del limite central y muestreo aleatorioDocumento41 páginasTeorema del limite central y muestreo aleatorioReyna Calles100% (1)
- SoaDocumento20 páginasSoaAlex Quingatuña100% (1)
- Ejercicios de Programacion en Consola de C#Documento276 páginasEjercicios de Programacion en Consola de C#Daly CristianAún no hay calificaciones
- Progresos en Economía ComputacionalDocumento195 páginasProgresos en Economía ComputacionalAlpahacaAún no hay calificaciones
- Módulo Modelos LinealesDocumento501 páginasMódulo Modelos LinealesGiovany Montaña100% (1)
- 2016L SI - Herramientas - Practicas - para - La - Gestion - R PDFDocumento348 páginas2016L SI - Herramientas - Practicas - para - La - Gestion - R PDFGabriel Marquezr100% (1)
- Proyecto Final - Recuperacion de La InformacionDocumento14 páginasProyecto Final - Recuperacion de La InformacionjerryAún no hay calificaciones
- 01LibroNet Logo Una Herramienta de ModeladoDocumento281 páginas01LibroNet Logo Una Herramienta de ModeladoRolando Cuellar TelloAún no hay calificaciones
- Tutorial Instalacion Office 365 PCDocumento9 páginasTutorial Instalacion Office 365 PCandroid 777Aún no hay calificaciones
- Libro Myriam-LilianaDocumento314 páginasLibro Myriam-LilianaAndres VelandiaAún no hay calificaciones
- 2 A0518 MA Finanzas Industriales ED1 V1 2015Documento122 páginas2 A0518 MA Finanzas Industriales ED1 V1 2015Lindsay Elescano MartinezAún no hay calificaciones
- Herramientas Predictivo GestionDocumento9 páginasHerramientas Predictivo Gestionwalter llanosAún no hay calificaciones
- IO optimización modelado 40Documento73 páginasIO optimización modelado 40Ing. Oscar Rojas HernandezAún no hay calificaciones
- Métodos Estadísticos para Economía y EmpresaDocumento394 páginasMétodos Estadísticos para Economía y EmpresaRigoberto Perez100% (1)
- Peti Esap 2017Documento356 páginasPeti Esap 2017Juan Carlos Jaramillo100% (1)
- Conceptos de Diagramas de ClasesDocumento25 páginasConceptos de Diagramas de ClasesSebastián Ortiz100% (1)
- Aplicación de Redes Neuronales MLP PDFDocumento183 páginasAplicación de Redes Neuronales MLP PDFJosephChiongAún no hay calificaciones
- Antologia de Administracion de Proyectos EstudiarDocumento65 páginasAntologia de Administracion de Proyectos EstudiarAbejita JoshAún no hay calificaciones
- Proyecciones de DemandaDocumento145 páginasProyecciones de DemandamiguelAún no hay calificaciones
- Decision Tools Suite 5.5 EspanolDocumento8 páginasDecision Tools Suite 5.5 EspanolGustavo AlvarezAún no hay calificaciones
- Antologia Simulación SistemaDocumento165 páginasAntologia Simulación SistemaJayder Antonio Gomez Moha100% (1)
- Programación Orientada A Objetos en JavaDocumento4 páginasProgramación Orientada A Objetos en JavaUniversidad del Norte EditorialAún no hay calificaciones
- Analitica de Negocios Con ExcelDocumento4 páginasAnalitica de Negocios Con ExcelPrevenciondelperuAún no hay calificaciones
- Impuesto de renta, grandes falencias del contribuyente - 2da ediciónDe EverandImpuesto de renta, grandes falencias del contribuyente - 2da ediciónAún no hay calificaciones
- Resumen de The Innovation Wave de Bettina Von StammDe EverandResumen de The Innovation Wave de Bettina Von StammAún no hay calificaciones
- Machine Learning aplicado al rendimiento académico en educación superior: factores, variables y herramientasDe EverandMachine Learning aplicado al rendimiento académico en educación superior: factores, variables y herramientasAún no hay calificaciones
- Colecciones de datos y algoritmos en Python: de cero al infinitoDe EverandColecciones de datos y algoritmos en Python: de cero al infinitoAún no hay calificaciones
- Ciberinteligencia y cibercontrainteligencia. Aplicación e impacto en la seguridad nacionalDe EverandCiberinteligencia y cibercontrainteligencia. Aplicación e impacto en la seguridad nacionalAún no hay calificaciones
- Auditoria Informatica-Municipalidad MoqueguaDocumento122 páginasAuditoria Informatica-Municipalidad MoqueguaLaura YanesAún no hay calificaciones
- Google Drive - Manual AvanzadoDocumento74 páginasGoogle Drive - Manual AvanzadoJuan Soras Valdivia100% (1)
- Auditoria Informatica-Municipalidad MoqueguaDocumento122 páginasAuditoria Informatica-Municipalidad MoqueguaLaura YanesAún no hay calificaciones
- Sistema HotelDocumento43 páginasSistema HotelGusTavo Prieto100% (1)
- Auditoria Informatica-Municipalidad MoqueguaDocumento122 páginasAuditoria Informatica-Municipalidad MoqueguaLaura YanesAún no hay calificaciones
- Ordenanza Municipal N°015-2009-MDSDocumento4 páginasOrdenanza Municipal N°015-2009-MDSGusTavo PrietoAún no hay calificaciones
- Técnicas Avanzadas de PredicciónDocumento293 páginasTécnicas Avanzadas de PredicciónGusTavo PrietoAún no hay calificaciones
- Introduccion A CLIPSDocumento30 páginasIntroduccion A CLIPSGusTavo PrietoAún no hay calificaciones
- En La Ficha InsertarDocumento2 páginasEn La Ficha InsertarGusTavo PrietoAún no hay calificaciones
- Laboratorio ClipsDocumento2 páginasLaboratorio ClipsGusTavo PrietoAún no hay calificaciones
- Prediccion de Fuga de ClientesDocumento93 páginasPrediccion de Fuga de ClientesGusTavo PrietoAún no hay calificaciones
- Tutorial Instalacion Java Eclipse Console PDFDocumento3 páginasTutorial Instalacion Java Eclipse Console PDFGusTavo PrietoAún no hay calificaciones
- Trabajo Final Data MiningDocumento2 páginasTrabajo Final Data MiningGusTavo PrietoAún no hay calificaciones
- Sesión 1 - Ing. de SoftwareDocumento15 páginasSesión 1 - Ing. de SoftwareGusTavo PrietoAún no hay calificaciones
- Introduccion Entidad - RelacionDocumento5 páginasIntroduccion Entidad - RelacionGusTavo PrietoAún no hay calificaciones
- El Análisis Del Ciclo de VidaDocumento7 páginasEl Análisis Del Ciclo de VidaDaniela Ovallos SanguinoAún no hay calificaciones
- Boca Juniors y Su Primer MundialDocumento2 páginasBoca Juniors y Su Primer MundialGusTavo PrietoAún no hay calificaciones
- Una Verdad IncomodaDocumento1 páginaUna Verdad IncomodaGusTavo PrietoAún no hay calificaciones
- Metodo de HolmbergDocumento9 páginasMetodo de HolmbergAnwar Miranda OlivosAún no hay calificaciones
- Practica de Regresion y CorrelacionDocumento8 páginasPractica de Regresion y CorrelacionChristian Quispe ZapataAún no hay calificaciones
- Manual de laboratorio de Física Aplicada a las Ciencias de la Vida y la Salud de la UNMSMDocumento91 páginasManual de laboratorio de Física Aplicada a las Ciencias de la Vida y la Salud de la UNMSMJaime Noel CaballeroAún no hay calificaciones
- Experiencia de Aprendizaje #11aDocumento6 páginasExperiencia de Aprendizaje #11aLuis ÑaupariAún no hay calificaciones
- Nicolás Pinilla Taller4Documento3 páginasNicolás Pinilla Taller4Nicolas PinillaAún no hay calificaciones
- Ejemplo de Cadenas en C#Documento5 páginasEjemplo de Cadenas en C#the123konAún no hay calificaciones
- Mapa MentalDocumento1 páginaMapa MentalAdriana UribeAún no hay calificaciones
- Comprobacion Leyes de KirchhoffDocumento7 páginasComprobacion Leyes de KirchhoffMaicol A MosqueraAún no hay calificaciones
- 10Cap9-Pavimentos de Cemento Portland MÇtodo PCA-98Documento33 páginas10Cap9-Pavimentos de Cemento Portland MÇtodo PCA-98alfredperalAún no hay calificaciones
- If Análisi de La Teoria de JuegosDocumento6 páginasIf Análisi de La Teoria de JuegosFrank Brunel Quispetupa MaxdeoAún no hay calificaciones
- Propagación Luz Vidrio Agua BencenoDocumento4 páginasPropagación Luz Vidrio Agua BencenoJohn MateusAún no hay calificaciones
- Materias 419Documento10 páginasMaterias 419Alexandra GarciaAún no hay calificaciones
- Informe de Redes SemanticasDocumento8 páginasInforme de Redes SemanticasYadira chicaiza0% (1)
- Segundo Parcial EstadisticaDocumento213 páginasSegundo Parcial EstadisticaMichael VelezAún no hay calificaciones
- Anexo y Act N°12 - Mat - 3ro - A y B - BenancioDocumento4 páginasAnexo y Act N°12 - Mat - 3ro - A y B - BenancioKarenThaliaArizaAlvaradoAún no hay calificaciones
- ENSAYO SIMCE #1 Quinto BasicoDocumento9 páginasENSAYO SIMCE #1 Quinto BasicoAhynoa Amor Araya SaezAún no hay calificaciones
- Modelado Sistema Mecánicos Traslacionales Parte 1Documento56 páginasModelado Sistema Mecánicos Traslacionales Parte 1Leonardo MoralesAún no hay calificaciones
- (MacIntyre, A) - Historia - de - La - EticaDocumento362 páginas(MacIntyre, A) - Historia - de - La - EticaAlejo Godoy100% (1)
- Matemáticas 4eso Tema 12 (ANAYA)Documento12 páginasMatemáticas 4eso Tema 12 (ANAYA)HAH592Aún no hay calificaciones
- Investigación Movimiento en Un PlanoDocumento12 páginasInvestigación Movimiento en Un PlanodanielAún no hay calificaciones
- UNIDAD 5 Productos y Cocientes NotablesDocumento49 páginasUNIDAD 5 Productos y Cocientes NotablessylvanaAún no hay calificaciones
- Teoria de Conjuntos3Documento47 páginasTeoria de Conjuntos3Jose Luis Soto DiazAún no hay calificaciones
- Torricelli NewtonDocumento2 páginasTorricelli NewtonCAMILAAún no hay calificaciones
- Guia Afianzamiento EcuacionesDocumento3 páginasGuia Afianzamiento EcuacionesJavier De La Ossa ArgelAún no hay calificaciones
- Material OlimpiadasDocumento28 páginasMaterial OlimpiadasGarcia Fernandez FernandoAún no hay calificaciones
- CONJUNTOSDocumento18 páginasCONJUNTOSEstefani Martinez PaitanAún no hay calificaciones
- Semana 01 - Sesión 2 - 3 Lógica ProposicionalDocumento16 páginasSemana 01 - Sesión 2 - 3 Lógica ProposicionalKarla Dorregaray SalvatierraAún no hay calificaciones
- El Concepto de Lengua en El Curso de Lingüística GeneralDocumento8 páginasEl Concepto de Lengua en El Curso de Lingüística Generall92algoc100% (1)
- 4°-Planificacion Eda 4Documento8 páginas4°-Planificacion Eda 4Jodar SsjAún no hay calificaciones
- 3 PotenciaciónDocumento27 páginas3 PotenciaciónJORGE CARLOS BETTIN BALLESTEROSAún no hay calificaciones